Python中的内存管理
理解内存分配对任何软件开发人员都很重要,因为编写高效的代码意味着编写内存高效的代码。内存分配可以定义为将计算机内存中的一块空间分配给程序。在Python中,内存分配和释放方法是自动的,因为Python开发人员为Python创建了一个垃圾收集器,因此用户不必手动进行垃圾收集。
垃圾收集
垃圾收集是解释器在不使用时释放内存以使其可用于其他对象的过程。
假设没有引用指向内存中的对象,即它没有被使用,虚拟机有一个垃圾收集器自动从堆内存中删除该对象
注意:有关更多信息,请参阅Python中的垃圾收集
引用计数
引用计数通过计算一个对象被系统中其他对象引用的次数来工作。当对对象的引用被删除时,对象的引用计数会减少。当引用计数变为零时,对象被释放。
例如,假设有两个或多个具有相同值的变量,那么, Python虚拟机所做的是,而不是在私有堆中创建另一个相同值的对象,它实际上使第二个变量指向原来的那个私有堆中的现有值。因此,在类的情况下,具有多个引用可能会占用大量内存空间,在这种情况下,引用计数非常有利于保留内存以供其他对象使用
例子:
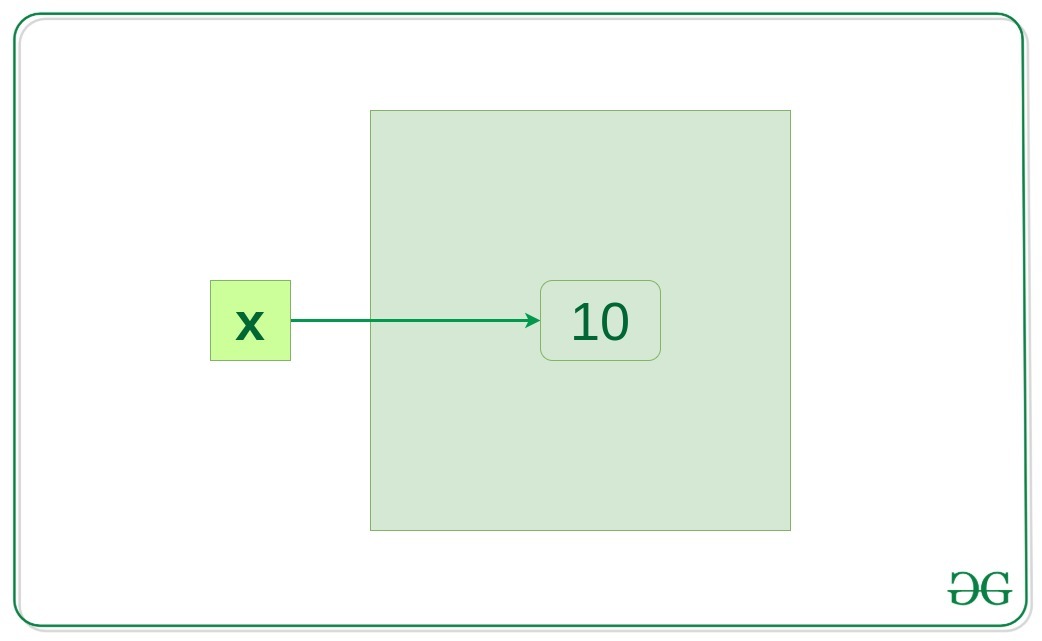
x = 10
当执行x = 10时,会在内存中创建一个整数对象 10,并将其引用分配给变量 x,这是因为Python中的一切都是对象。
让我们验证它是否属实
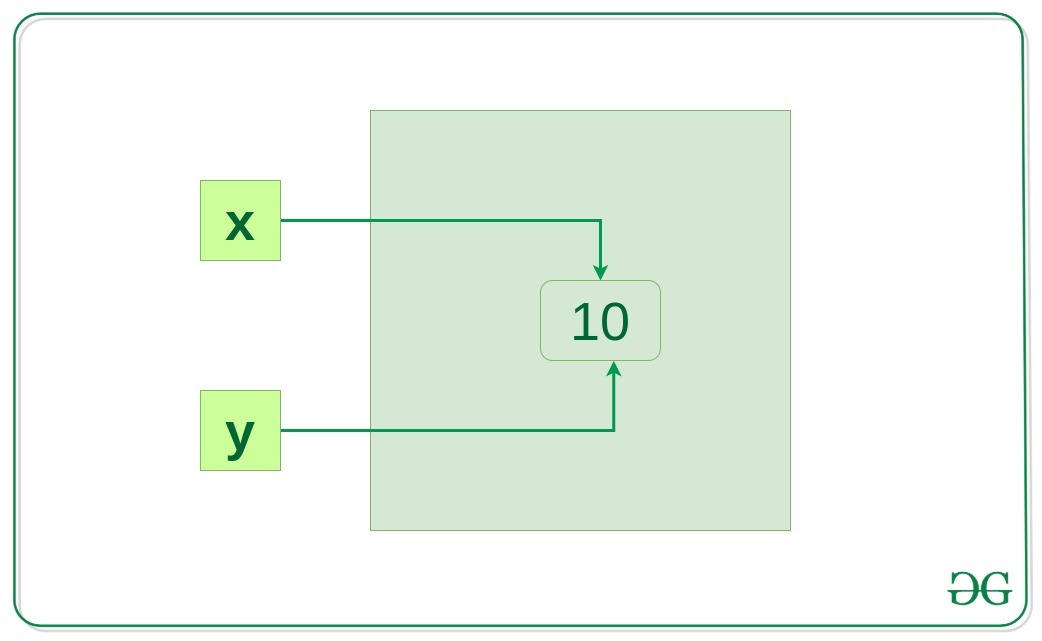
x = 10
y = x
if id(x) == id(y):
print("x and y refer to the same object")
输出:
x and y refer to the same object在上面的示例中, y = x将创建另一个引用变量 y,它将引用同一个对象,因为如果对象已经存在且具有相同的值, Python通过将相同的对象引用分配给新变量来优化内存利用率。
现在,让我们改变 x 的值,看看会发生什么。
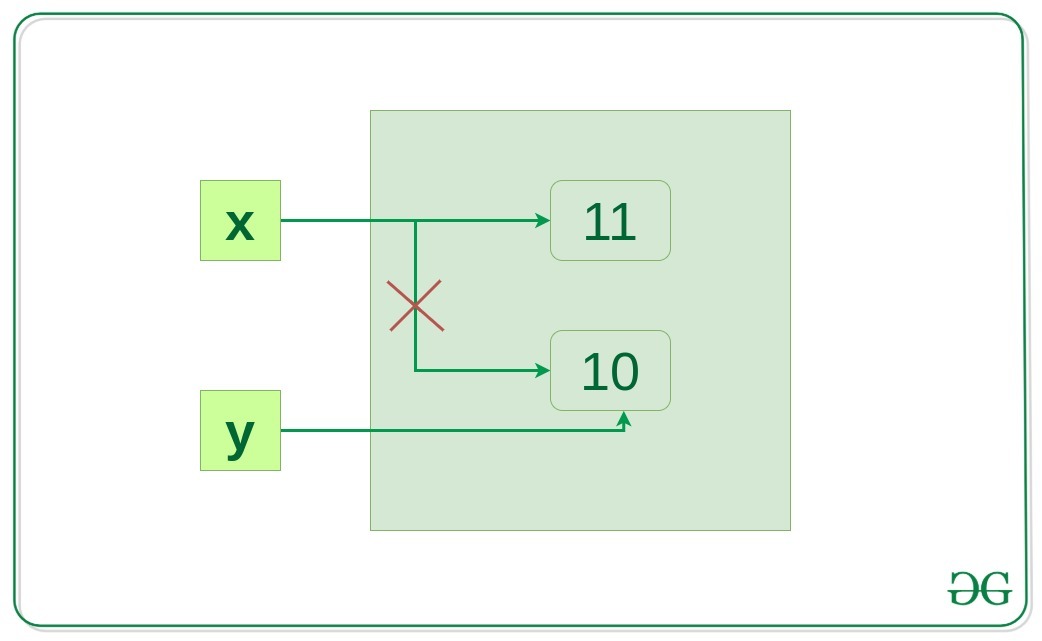
x = 10
y = x
x += 1
if id(x) != id(y):
print("x and y do not refer to the same object")
输出:
x and y do not refer to the same object所以现在 x 引用了一个新对象 x,x 和 10 之间的链接断开了,但 y 仍然引用 10。
Python中的内存分配
内存有两部分:
- 堆栈内存
- 堆内存
方法/方法调用和引用存储在堆栈内存中,所有值对象都存储在私有堆中。
堆栈内存的工作
分配发生在连续的内存块上。我们称之为堆栈内存分配,因为分配发生在函数调用堆栈中。编译器知道要分配的内存大小,每当调用函数时,它的变量都会在堆栈上分配内存。
它是仅在特定函数或方法调用内部需要的内存。调用函数时,会将其添加到程序的调用堆栈中。任何本地内存分配(例如特定函数内的变量初始化)都临时存储在函数调用堆栈中,一旦函数返回,它将被删除,调用堆栈继续执行下一个任务。编译器使用预定义的例程处理对连续内存块的分配,开发人员无需担心。
例子:
def func():
# All these variables get memory
# allocated on stack
a = 20
b = []
c = ""
堆内存的工作
内存是在执行程序员编写的指令期间分配的。注意heap这个名字与heap数据结构无关。之所以称为堆,是因为它是供程序员分配和取消分配的一堆内存空间。这些变量在方法或函数调用之外需要,或者在多个函数中共享,全局存储在堆内存中。
例子:
# This memory for 10 integers
# is allocated on heap.
a = [0]*10