词法分析器一次从左到右扫描一个字符。它使用两个从ptr( bp )开始并向前的指针来跟踪已扫描输入的指针。

最初,两个指针都指向输入字符串的第一个字符,如下所示
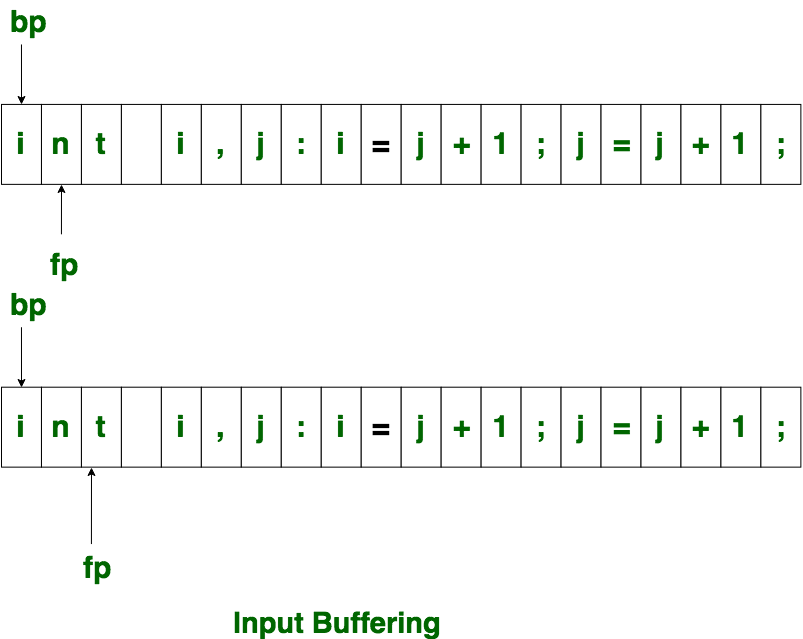
前进的ptr继续搜索词尾的结尾。遇到空格后,它指示勒克姆结束。在上面的示例中,ptr(fp)遇到空白时,立即识别了词素“ int”。
fp将在空白处向前移动,当fp遇到空白时,它将忽略并向前移动。然后在下一个标记处设置begin ptr(bp)和forward ptr(fp)。
因此,从辅助存储器中读取输入字符,但是以这种方式从辅助存储器中读取是昂贵的。首先将数据块读入缓冲区,然后再通过词法分析器将其读取。在此上下文中使用两种方法:一个缓冲区方案和两个缓冲区方案。这些解释如下。

- 一种缓冲方案:
在此方案中,仅使用一个缓冲区来存储输入字符串,但是此方案的问题在于,如果lexeme非常长,则它越过缓冲区边界,以扫描剩余的lexeme,必须重新填充缓冲区,这将导致覆盖莱克森的第一个。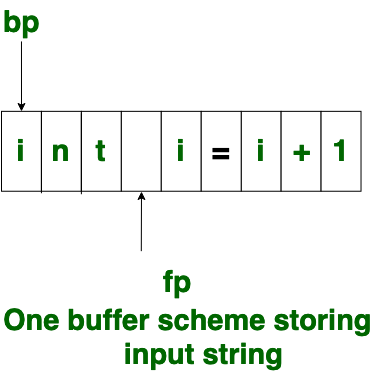
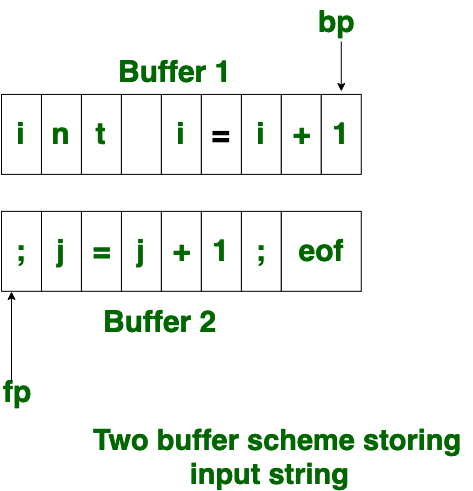
- 两种缓冲方案:
为了克服一种缓冲区方案的问题,在这种方法中,使用了两个缓冲区来存储输入字符串。交替扫描第一缓冲区和第二缓冲区。当到达当前缓冲区的末尾时,另一个缓冲区将被填充。此方法的唯一问题是,如果词素的长度大于缓冲区的长度,则无法完全扫描扫描输入。最初,bp和fp都指向第一个缓冲区的第一个字符。然后,fp向右移动以寻找尾素的末端。一旦识别出空白字符,就将bp和fp之间的字符串标识为相应的标记。为了识别,缓冲区字符的第一个缓冲区末尾的边界应放置在第一个缓冲区的末尾。
类似地,第二缓冲区的结尾也可以通过第二缓冲区的结尾处存在的缓冲区标记的结尾来识别。当fp遇到第一个eof时,则可以识别出第一个缓冲区的末尾,因此开始填充第二个缓冲区。以同样的方式,当获得第二个eof时,它指示第二个缓冲区。或者,两个缓冲区都可以填满,直到输入程序结束并标识了令牌流。在末尾引入的这个eof字符称为Sentinel ,用于标识缓冲区的末尾。