背景:解析器使用CFG(Context-free-Grammer)来验证输入字符串并为编译器的下一阶段生成输出。输出可以是解析树或抽象语法树。现在,为了使语义分析与编译器的语法分析阶段交织在一起,我们使用“语法定向翻译”。
定义
语法定向翻译是语法的扩充规则,可促进语义分析。 SDT涉及以附加在节点上的属性的形式自下而上和/或自上而下地从解析树传递信息。语法定向的转换规则使用1)节点的词汇值,2)常量和3)与它们定义中的非终结点相关联的属性。
语法定向翻译的一般方法是构造一个解析树或语法树,并以某种顺序访问树节点上的属性值。在许多情况下,可以在解析过程中完成翻译而无需构建显式树。
例子
E -> E+T | T
T -> T*F | F
F -> INTLIT 这是一种语法上语法上验证其中具有加法和乘法的表达式的语法。现在,为了进行语义分析,我们将在此语法中增加SDT规则,以便将一些信息传递到解析树上,并检查是否存在语义错误。在这个例子中,我们将重点放在给定表达式的评估上,因为在这个非常基本的例子中,我们没有任何语义断言可以检查。
E -> E+T { E.val = E.val + T.val } PR#1
E -> T { E.val = T.val } PR#2
T -> T*F { T.val = T.val * F.val } PR#3
T -> F { T.val = F.val } PR#4
F -> INTLIT { F.val = INTLIT.lexval } PR#5
为了进一步理解翻译规则,我们采用了第一个扩展为[E-> E + T]生产规则的SDT。考虑的转换规则将val作为两个非终端E&T的属性。转换规则的右侧对应于生产规则右侧节点的属性值,反之亦然。概括而言,SDT是CFG的增强规则,它使用以下属性将1)属性集与语法的每个节点相关联,并将2)翻译规则集与每个产生规则相关联,并使用属性,常量和词法值。
让我们来看一个字符串,看看语义分析是如何发生的-S = 2 + 3 * 4。对应于S的解析树为
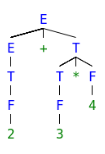
要评估翻译规则,我们可以在解析树上进行一次深度优先搜索遍历。这仅是因为SDT规则不会对评估施加任何特定的顺序,直到在具有所有综合属性的语法之前在子级属性之前计算子级属性。否则,我们将不得不找出最合适的计划来遍历解析树并评估一个或多个遍历中的所有属性。为了更好地理解,我们将以从左到右的方式自下而上地计算示例的翻译规则。
![]()
上图显示了语义分析是如何发生的。信息流自下而上发生,并且所有子级属性都在父级之前进行了计算,如上所述。右手侧节点有时带有下标1注释,以区分孩子和父母。
附加信息
综合属性是仅依赖于子节点的属性值的属性。
因此[E-> E + T {E.val = E.val + T.val}]具有对应于节点E的合成属性val。如果合成了增强语法中的所有语义属性,则在其中进行一次深度优先搜索遍历任何顺序对于语义分析阶段都是足够的。
继承属性是依赖于父级和/或同级属性的此类属性。
因此,[Ep-> E + T {Ep.val = E.val + T.val,T.val = Ep.val}](其中E和Ep是相同的生产符号,用于区分父子)对应于节点T的属性val。
参考:
http://www.personal.kent.edu/~rmuhamma/Compilers/MyCompiler/syntaxDirectTrans.htm
http://pages.cs.wisc.edu/~fischer/cs536.s06/course.hold/html/NOTES/4.SYNTAX-DIRECTED-TRANSLATION.html