编译器设计——语法树的变体
语法树是一棵树,其中每个叶节点代表一个操作数,而每个内部节点代表一个运算符。 Parse Tree 简称为语法树。当以树结构表示程序时,通常使用语法树。
构造语法树的规则
语法树的节点都可以作为具有许多字段的数据来执行。运算符符节点的一个元素标识运算符,而其余字段包含指向操作数节点的指针。运算符也称为节点的标签。使用以下函数创建具有二元运算符的表达式的语法树节点。每个函数都返回对最近创建的节点的引用。
1. mknode(op,left,right):创建一个运算符节点,名字为op和两个字段,包含left和right指针。
2. mkleaf(id, entry):创建一个标识符节点,带有标签id和入口字段,是对标识符的符号表入口的引用。
3. mkleaf(num, val):它创建一个名为 num 的数字节点和一个包含数字值 val 的字段。例如,为表达式 a 4 + c 创建一个语法树。 p1、p2、…、p5 分别是指向标识符“a”和“c”的符号表条目的指针,在这个序列中。
示例 1:字符串a – b ∗ c + d的语法树为:
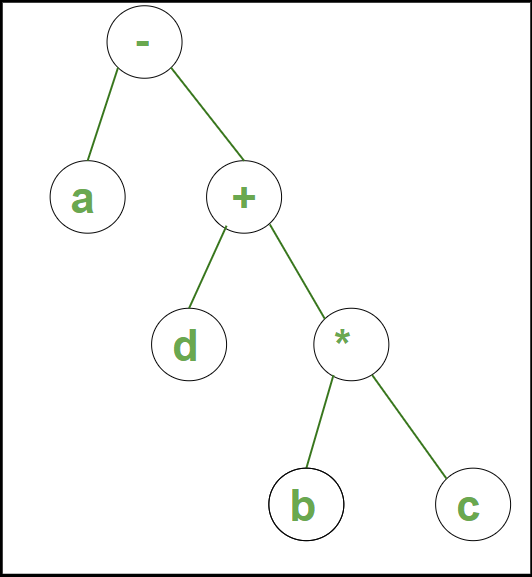
语法树示例 1
示例 2:字符串a * (b + c) – d /2的语法树是:
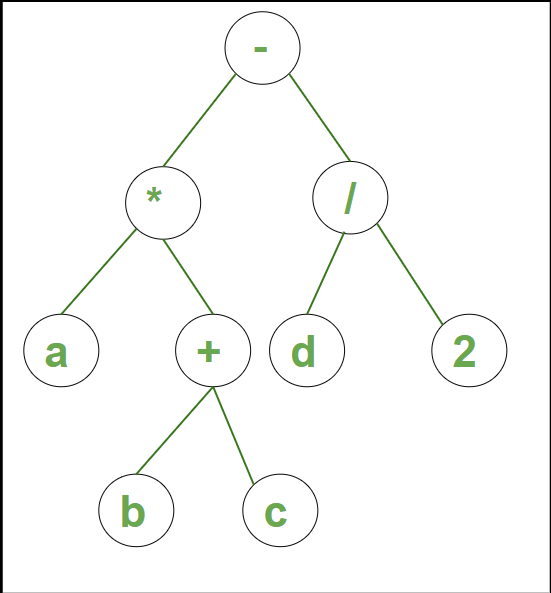
语法树示例 2
语法树的变体:
语法树基本上有两种变体,如下所述:
- 表达式的有向无环图 (DAG)
- 构建有向无环图的值数法
表达式的有向无环图 (DAG)
一个 DAG,就像一个表达式的语法树,包括对应于原子操作数的叶子和对应于运算符的内部代码。如果 N 表示公共子表达式,则 DAG 中的节点 N 有许多父节点;在语法树中,公共子表达式的树将被复制与子表达式在原始表达式中出现的次数一样多。因此,DAG 不仅更简洁地对表达式进行编码,而且还为编译器提供了有关如何生成有效代码来评估表达式的基本信息。
有向无环图 (DAG) 是一种显示基本块结构的工具,允许您检查它们之间的值流,还允许您优化它们。 DAG 允许对基本部分进行简单的转换。
DAG 的属性是:
- 叶节点代表标识符、名称或常量。
- 内部节点代表运算符。
- 内部节点还表示表达式的结果或要存储或分配值的标识符/名称。
例子:
T0 = a+b --- Expression 1
T1 = T0 +c --- Expression 2表达式1:T 0 = a+b
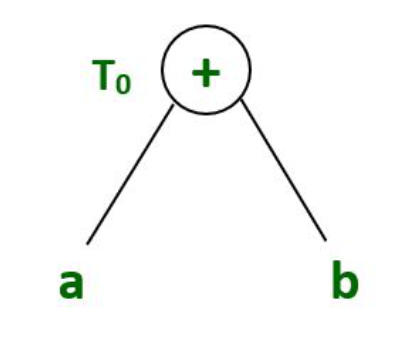
表达式 1 的语法树
表达式 2: T 1 = T 0 +c
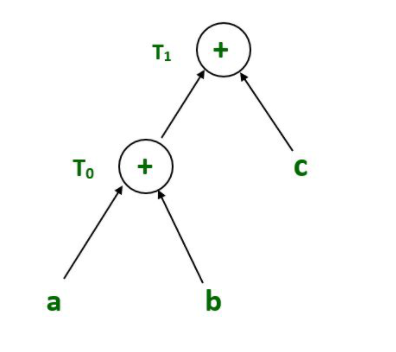
表达式 2 的语法树
构建 DAG 的值数法:
记录数组用于保存语法树或 DAG 的节点。数组的每一行对应一个记录,因此对应一个节点。每条记录的第一个字段是操作码,表示节点的标签。在下图中,内部节点包含另外两个表示左右子节点的字段,而叶子节点有一个额外的字段来存储词法值(在此实例中是符号表指针或常量)。
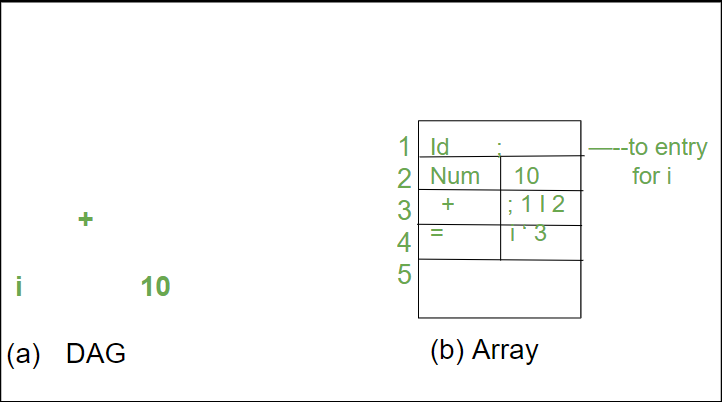
在数组中分配 i = i + 10 的 DAG 的节点
数组内该节点的记录的整数索引用于引用该数组中的节点。这个整数在过去被称为节点的值数或节点表示的表达式。标记为 -I- 的节点的值为 3,而其左右子节点的值分别为 1 和 2。在实践中,我们可以使用指向记录的指针或对对象的引用来代替整数索引,但对节点的引用仍将被称为其“值编号”。如果它们以正确的数据格式存储,值数字可以帮助我们构建表达式。
- 算法:构造有向无环图节点的值数法。
- INPUT:标签 op、节点 / 和节点 r。
- OUTPUT:数组中带有签名(op,l,r)的节点的值编号。
- 方法:在数组中搜索带有标签 op、左孩子 I 和右孩子 r 的节点 M。如果存在这样的节点,则返回 M 的值编号。如果没有,则在数组中创建一个标签为 op、左孩子 I 和右孩子 r 的新节点 N,并返回其值编号。
虽然算法会产生预期的结果,但每次请求一个节点时检查整个数组非常耗时,尤其是当数组包含来自整个程序的表达式时。哈希表,其中节点被划分为“桶”,每个桶通常只包含几个节点,是一种更有效的方法。哈希表是可以有效支持字典的众多数据结构之一。 1 字典是一种数据类型,它允许我们在集合中添加和删除元素,以及检测集合中是否存在特定元素。一个好的字典数据结构,例如哈希表,在恒定或接近恒定的时间内执行这些操作中的每一个,而不管集合的大小。
为了为 DAG 的节点构建一个哈希表,我们需要一个哈希函数h,它计算签名 (op, I, r) 的桶索引,使得签名分布在桶中并且没有一个桶得到更多而不是相当一部分的节点。桶索引 h(op, I, r) 是根据 op、I 和 r 确定性计算的,允许我们重复计算并始终得到每个节点 (op, I, r) 的相同桶索引。
桶可以实现为链表,如图所示。桶头存储在一个由哈希值索引的数组中,每个哈希值对应于列表的第一个单元格。存储桶的链表中的每一列都包含散列到该存储桶的节点之一的值编号。也就是说,节点 (op,l,r) 可能位于数组的列表中,其标题位于索引 h(op,l,r) 处。

搜索桶的数据结构
我们计算桶索引 h(op,l,r) 并在给定输入节点 op、I 和 r 的情况下搜索此桶中的单元格列表以查找指定的输入节点。通常有足够的桶,没有一个列表有超过几个单元格。但是,我们可能需要检查一个桶中的所有单元格,并且对于在一个单元格中发现的每个值编号 v,我们必须验证输入节点的签名 (op,l,r) 是否与单元格列表(如上图所示)。如果找到匹配项,则返回 v。我们构建一个新单元格,将其添加到存储桶索引 h(op,l,r) 的单元格列表中,如果找不到匹配项,则返回该新单元格中的值编号。