Python网页抓取教程
假设您想从网站获取一些信息?比方说 geeksforgeeks 网站上的一篇文章或一些新闻文章,你会怎么做?您可能想到的第一件事是将信息复制并粘贴到您的本地媒体中。但是,如果您每天都需要尽可能快的大量数据怎么办。在这种情况下,复制和粘贴将不起作用,这就是您需要网络抓取的地方。
在本文中,我们将讨论如何使用Python中的 requests 库和 beautifulsoup 库执行网页抓取。
请求模块
Requests 库用于向特定 URL 发出 HTTP 请求并返回响应。 Python请求提供了用于管理请求和响应的内置功能。
安装
请求安装取决于操作系统的类型,任何地方的基本命令都是打开命令终端并运行,
pip install requests发出请求
Python requests 模块有几个内置方法可以使用 GET、POST、PUT、PATCH 或 HEAD 请求向指定的 URI 发出 HTTP 请求。 HTTP 请求旨在从指定的 URI 检索数据或将数据推送到服务器。它作为客户端和服务器之间的请求-响应协议工作。在这里,我们将使用 GET 请求。
GET 方法用于使用给定的 URI 从给定的服务器检索信息。 GET 方法发送附加到页面请求的编码用户信息。
示例:发出 GET 请求的Python请求
Python3
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)Python3
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# print request object
print(r.url)
# print status code
print(r.status_code)Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Getting the title tag
print(soup.title)
# Getting the name of the tag
print(soup.title.name)
# Getting the name of parent tag
print(soup.title.parent.name)
# use the child attribute to get
# the name of the child tagPython3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
content = leftbar.find_all('li')
print(content)Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
for line in lines:
print(line.text)Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
lines = leftbar.find_all('li')
for line in lines:
print(line.text)Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# find all the anchor tags with "href"
for link in soup.find_all('a'):
print(link.get('href'))Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
images_list = []
images = soup.select('img')
for image in images:
src = image.get('src')
alt = image.get('alt')
images_list.append({"src": src, "alt": alt})
for image in images_list:
print(image)Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/1/'
req = requests.get(URL)
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs = {'class','head'})
print(titles[4].text)Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/'
for page in range(1, 10):
req = requests.get(URL + str(page) + '/')
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
for i in range(4, 19):
if page > 1:
print(f"{(i-3)+page*15}" + titles[i].text)
else:
print(f"{i-3}" + titles[i].text)Python3
import requests
from bs4 import BeautifulSoup as bs
URL = ['https://www.geeksforgeeks.org','https://www.geeksforgeeks.org/page/10/']
for url in range(0,2):
req = requests.get(URL[url])
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs={'class','head'})
for i in range(4, 19):
if url+1 > 1:
print(f"{(i - 3) + url * 15}" + titles[i].text)
else:
print(f"{i - 3}" + titles[i].text)Python3
import requests
from bs4 import BeautifulSoup as bs
import csv
URL = 'https://www.geeksforgeeks.org/page/'
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
titles_list = []
count = 1
for title in titles:
d = {}
d['Title Number'] = f'Title {count}'
d['Title Name'] = title.text
count += 1
titles_list.append(d)
filename = 'titles.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['Title Number','Title Name'])
w.writeheader()
w.writerows(titles_list)输出:

响应对象
当向 URI 发出请求时,它会返回响应。就Python而言,这个 Response 对象由 requests.method() 返回,方法是 get、post、put 等。Response 是一个强大的对象,具有许多有助于规范化数据或创建理想代码部分的函数和属性。例如, response.status_code 从 headers 本身返回状态代码,可以检查请求是否成功处理。
响应对象可用于暗示许多特性、方法和功能。
示例: Python请求响应对象
Python3
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# print request object
print(r.url)
# print status code
print(r.status_code)
输出:
https://www.geeksforgeeks.org/python-programming-language/
200有关更多信息,请参阅我们的Python请求教程。
BeautifulSoup 库
BeautifulSoup 用于从 HTML 和 XML 文件中提取信息。它提供解析树和导航、搜索或修改此解析树的功能。
安装
要在 Windows、Linux 或任何操作系统上安装 Beautifulsoup,需要 pip 包。要检查如何在您的操作系统上安装 pip,请查看 – PIP 安装 – Windows || Linux。现在在终端中运行以下命令。
pip install beautifulsoup4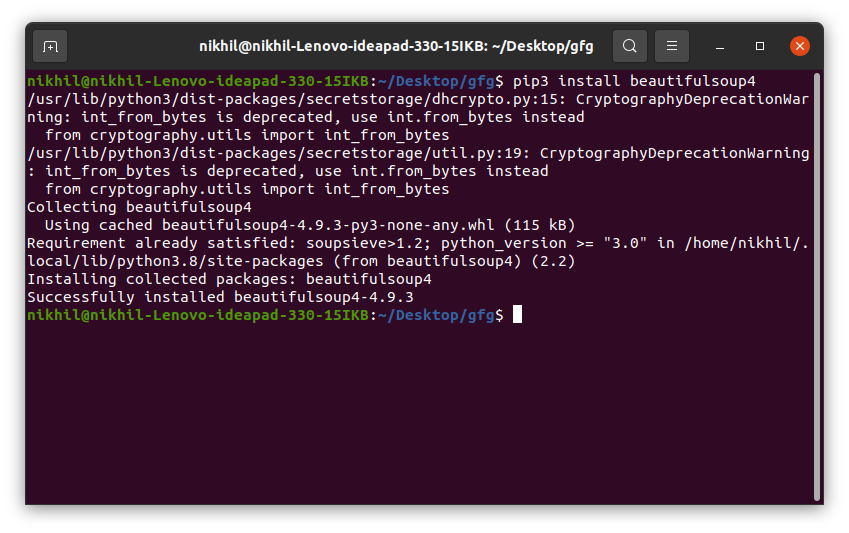
检查网站
在从页面的 HTML 中获取任何信息之前,我们必须了解页面的结构。需要这样做才能从整个页面中选择所需的数据。我们可以通过右键单击要抓取的页面并选择检查元素来做到这一点。
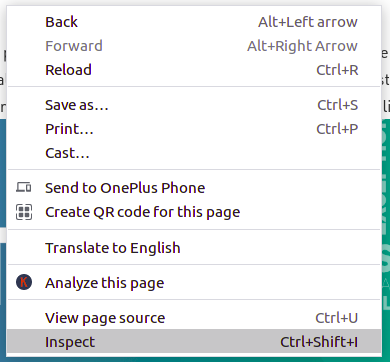
单击检查按钮后,浏览器的开发人员工具将打开。现在几乎所有的浏览器都安装了开发工具,我们将在本教程中使用 Chrome。
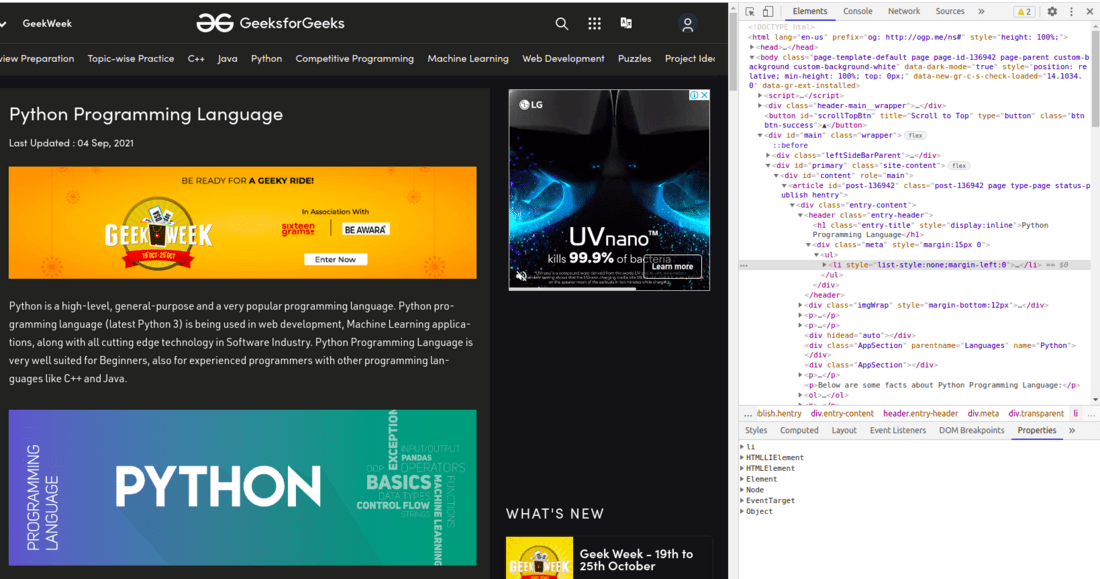
开发人员的工具允许查看站点的文档对象模型 (DOM)。如果您不了解 DOM,请不要担心,只需将显示的文本视为页面的 HTML 结构即可。
解析 HTML
在获得页面的 HTML 之后,让我们看看如何将这些原始 HTML 代码解析为一些有用的信息。首先,我们将通过指定我们要使用的解析器来创建一个 BeautifulSoup 对象。
注意: BeautifulSoup 库建立在 html5lib、lxml、html.parser 等 HTML 解析库之上。因此可以同时创建 BeautifulSoup 对象和指定解析器库。
示例: Python BeautifulSoup 解析 HTML
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
输出:
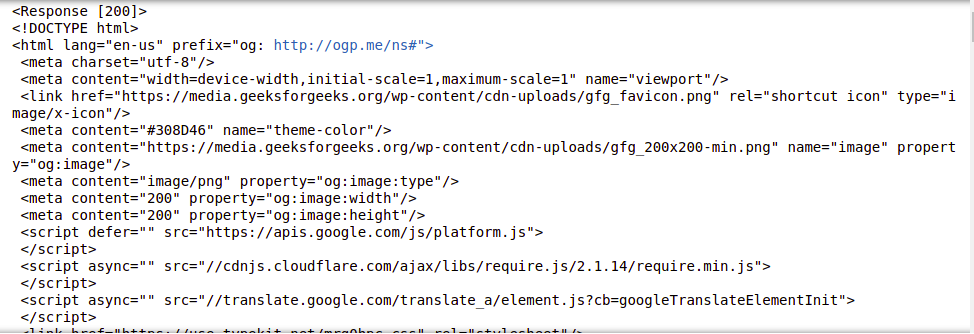
这些信息对我们来说仍然没有用,让我们看另一个例子,从中得到一些清晰的画面。让我们尝试提取页面的标题。
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Getting the title tag
print(soup.title)
# Getting the name of the tag
print(soup.title.name)
# Getting the name of parent tag
print(soup.title.parent.name)
# use the child attribute to get
# the name of the child tag
输出:
Python Programming Language - GeeksforGeeks
title
html寻找元素
现在,我们想从 HTML 内容中提取一些有用的数据。汤对象包含嵌套结构中的所有数据,这些数据可以通过编程方式提取。我们要抓取的网站包含大量文本,所以现在让我们抓取所有这些内容。首先,让我们检查我们要抓取的网页。
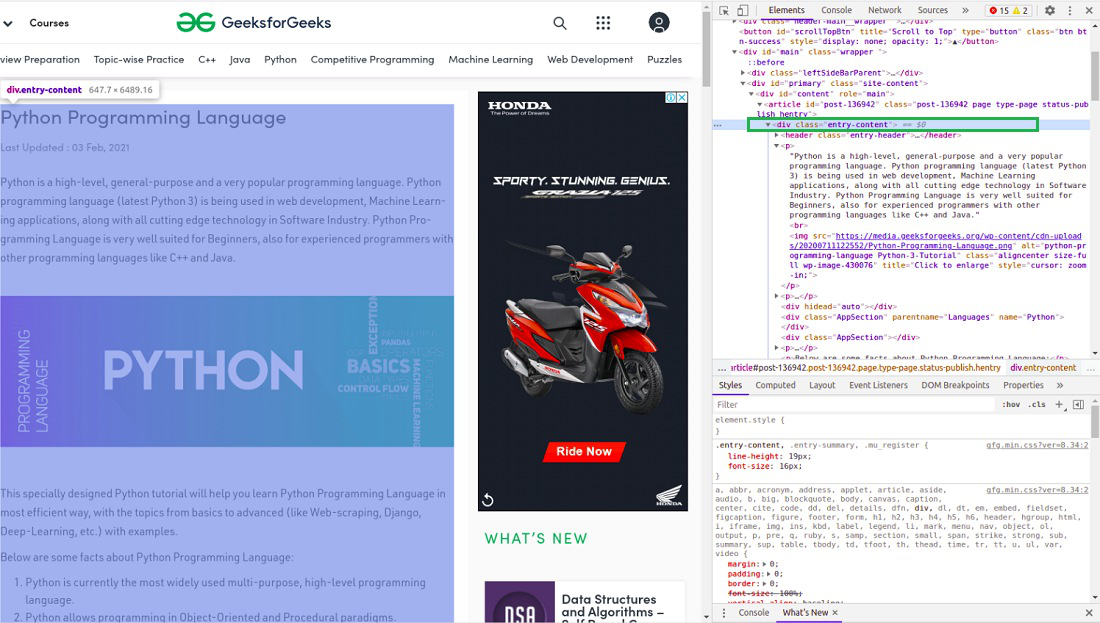
按类查找元素
在上图中,我们可以看到页面的所有内容都在类 entry-content 的 div 下。我们将使用 find 类。此类将找到具有给定属性的给定标签。在我们的例子中,它将找到所有具有类作为条目内容的 div。我们已经从该站点获得了所有内容,但您可以看到所有图像和链接也被刮掉了。所以我们的下一个任务是只从上面解析的 HTML 中找到内容。再次检查我们网站的 HTML –
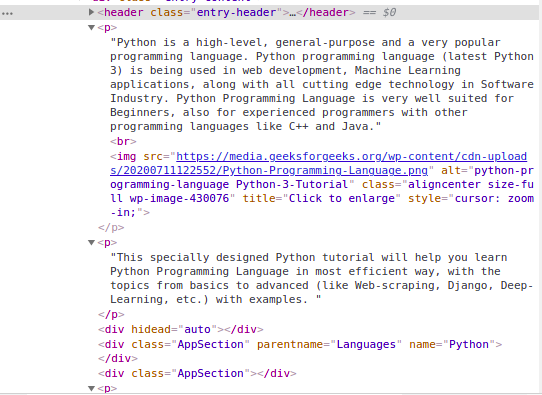
我们可以看到页面的内容在
标签下。现在我们必须找到这个类中存在的所有 p 标签。我们可以使用 BeautifulSoup 的 find_all 类。
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
输出:
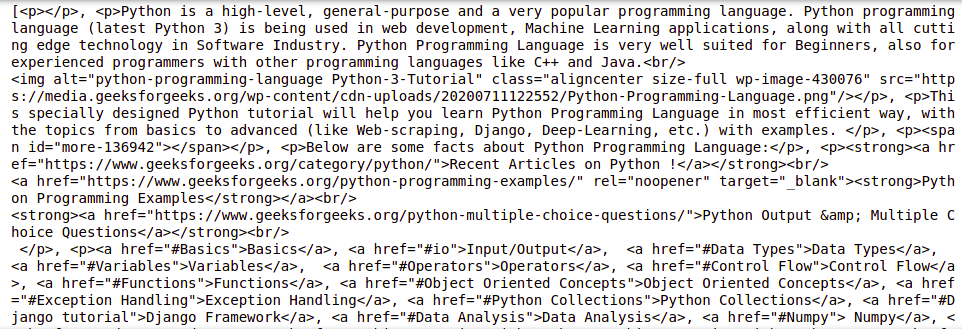
按 ID 查找元素
在上面的例子中,我们通过类名找到了元素,但是让我们看看如何通过 id 找到元素。现在对于这个任务,让我们抓取页面左侧栏的内容。第一步是检查页面并查看左栏位于哪个标签下。
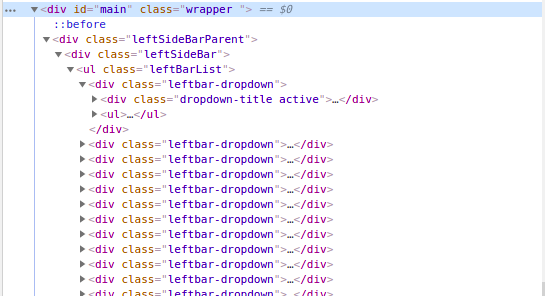
上图显示左栏位于以 id 为主的
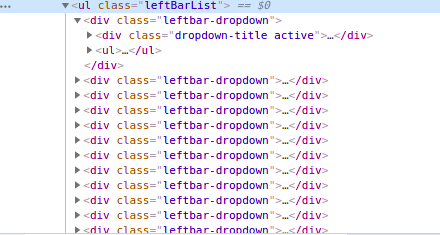
我们可以看到leftbar中的列表在
- 标签下,类为leftBarList,我们的任务是找到这个ul下的所有li。
- 同一个网站
- 不同的网站 URL
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
content = leftbar.find_all('li')
print(content)
输出:
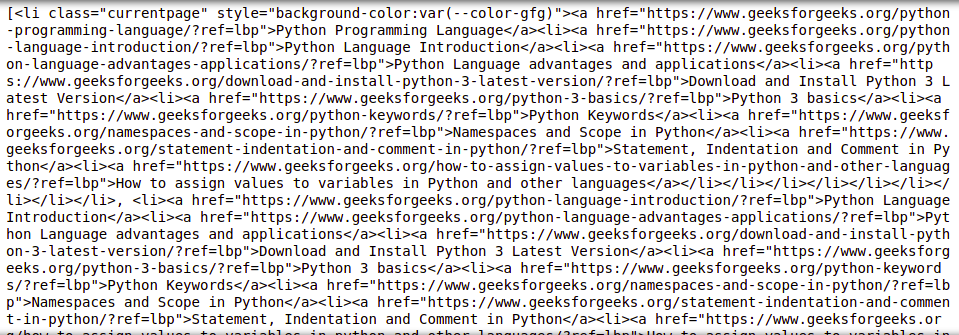
从标签中提取文本
在上面的示例中,您一定已经看到,在抓取数据的同时,标签也会被抓取,但是如果我们只想要没有任何标签的文本怎么办。不用担心,我们将在本节中讨论相同的内容。我们将使用 text 属性。它只打印标签中的文本。我们将使用上面的示例,并从中删除所有标签。
示例 1:从页面内容中删除标签
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
for line in lines:
print(line.text)
输出:

示例 2:从左侧栏的内容中删除标签
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
lines = leftbar.find_all('li')
for line in lines:
print(line.text)
输出:
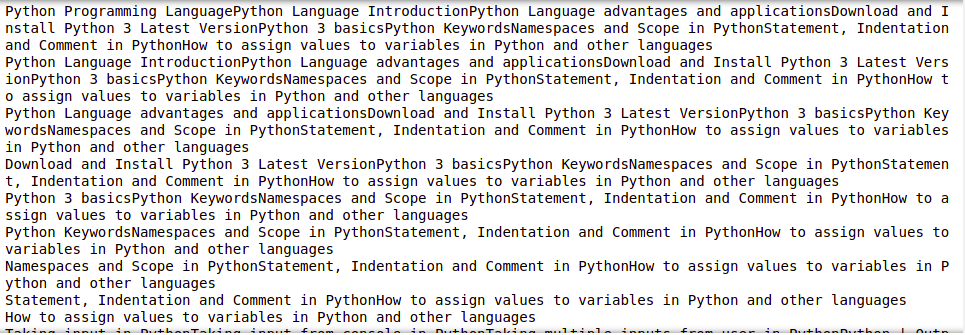
提取链接
到目前为止,我们已经了解了如何提取文本,现在让我们看看如何从页面中提取链接。
示例: Python BeautifulSoup 提取链接
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# find all the anchor tags with "href"
for link in soup.find_all('a'):
print(link.get('href'))
输出:
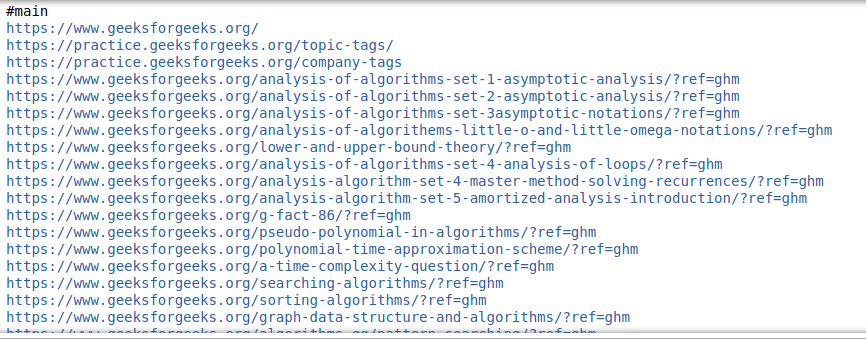
提取图像信息
再次检查页面时,我们可以看到图像位于 img 标记内,并且该图像的链接位于 src 属性内。见下图——

示例: Python BeautifulSoup 提取图像
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
images_list = []
images = soup.select('img')
for image in images:
src = image.get('src')
alt = image.get('alt')
images_list.append({"src": src, "alt": alt})
for image in images_list:
print(image)
输出:
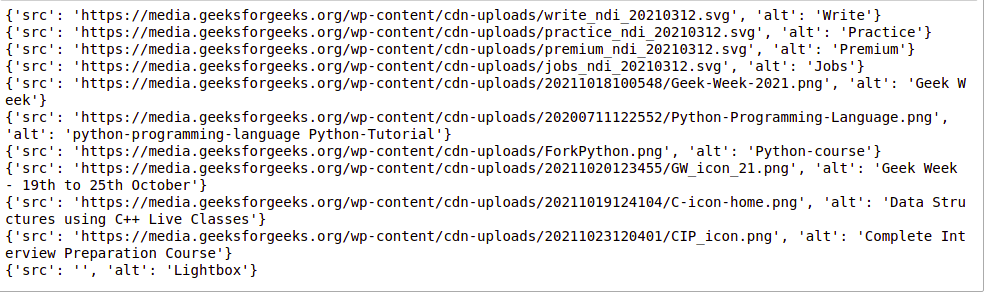
抓取多个页面
现在,可能会出现各种情况,您可能希望从同一网站的多个页面或多个不同的 URL 获取数据,并且为每个网页手动编写代码是一项耗时且乏味的任务。此外,它违反了自动化的所有基本原则。呸!
为了解决这个确切的问题,我们将看到两种主要的技术来帮助我们从多个网页中提取数据:
示例 1:遍历页码

GeeksforGeeks 网站底部的页码
大多数网站都有从 1 到 N 标记的页面。这使得我们可以非常简单地遍历这些页面并从中提取数据,因为这些页面具有相似的结构。例如:

GeeksforGeeks 网站底部的页码
在这里,我们可以在 URL 的末尾看到页面详细信息。使用这些信息,我们可以轻松地创建一个 for 循环,遍历任意数量的页面(通过将 page/(i)/ 放入 URL字符串并迭代“i”直到 N)并从中刮取所有有用的数据。以下代码将使您更清楚地了解如何在Python中使用 For 循环来抓取数据。
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/1/'
req = requests.get(URL)
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs = {'class','head'})
print(titles[4].text)
输出:
7 Most Common Time Wastes During Software Development现在,使用上面的代码,我们可以通过将这些行夹在一个循环中来获取所有文章的标题。
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/'
for page in range(1, 10):
req = requests.get(URL + str(page) + '/')
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
for i in range(4, 19):
if page > 1:
print(f"{(i-3)+page*15}" + titles[i].text)
else:
print(f"{i-3}" + titles[i].text)
输出:

示例 2:遍历不同 URL 的列表
上面的技术绝对很棒,但是如果你需要抓取不同的页面,而你不知道它们的页码怎么办?您需要逐个抓取这些不同的 URL,并为每个此类网页手动编写脚本。
相反,您可以只列出这些 URL 并循环访问它们。通过简单地迭代列表中的项目,即 URL,我们将能够提取这些页面的标题,而无需为每个页面编写代码。这是如何执行此操作的示例代码。
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = ['https://www.geeksforgeeks.org','https://www.geeksforgeeks.org/page/10/']
for url in range(0,2):
req = requests.get(URL[url])
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs={'class','head'})
for i in range(4, 19):
if url+1 > 1:
print(f"{(i - 3) + url * 15}" + titles[i].text)
else:
print(f"{i - 3}" + titles[i].text)
输出:

有关更多信息,请参阅我们的Python BeautifulSoup 教程。
将数据保存到 CSV
首先,我们将创建一个字典列表,其中包含要添加到 CSV 文件中的键值对。然后我们将使用 csv 模块将输出写入 CSV 文件。请参阅以下示例以更好地理解。
示例: Python BeautifulSoup 保存为 CSV
Python3
import requests
from bs4 import BeautifulSoup as bs
import csv
URL = 'https://www.geeksforgeeks.org/page/'
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
titles_list = []
count = 1
for title in titles:
d = {}
d['Title Number'] = f'Title {count}'
d['Title Name'] = title.text
count += 1
titles_list.append(d)
filename = 'titles.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['Title Number','Title Name'])
w.writeheader()
w.writerows(titles_list)
输出:
