在上一篇文章中,我们讨论了假设检验,这是推论统计的基础。我们之前讨论了基本的假设检验,包括零假设和交替假设,z检验等。现在,在此讨论更多的I型和II型误差,显着性水平(α)和功效(β)。
P值:
p值定义为获得结果或比正态分布中实际观察到的结果更极端的概率。通常,我们采用显着性水平= 0.05,这意味着如果观察到的p值小于显着性水平,则我们拒绝原假设。
要计算p值,我们需要表中特定的测试统计信息(t检验,z检验,f检验),以及它是否是一尾两尾检验。
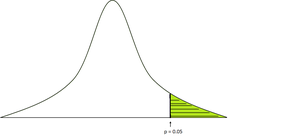
p值
Alpha和Beta测试:
| Null Hypothesis is TRUE | Null Hypothesis is FALSE | |
|---|---|---|
| Reject Null Hypothesis |
Type I Error
|
Correct decision
|
| Fail to Reject the Null Hypothesis |
Correct decision
|
Type II error
|
- 类型I错误(Alpha):现在,如果我们根据重要性p值计算的水平拒绝零假设,则样本实际上可能属于相同(零)分布,并且我们错误地拒绝了它,称为I型错误,用alpha表示
- II型错误(测试版) :现在,根据显着性水平和p值,如果我们接受的样品并非真正属于同一分布,则称为II型错误
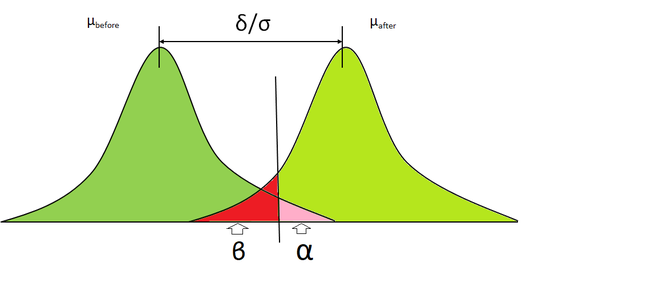
幂和置信区间:
- 置信区间:置信区间是可以可靠地拒绝原假设的区域。它是通过减去alpha和1来计算的
![]()
- 幂:幂是正确拒绝零假设并接受替代假设(H A )的概率。可以通过从1中减去beta来计算功效。
![]()
功率越高,产生II型错误的可能性越低。较低的功率意味着执行II型错误的风险更高,反之亦然。通常,0.80的功率被认为足够好。功率还取决于以下因素:
- 效应大小:效应大小只是衡量两个变量之间关系强度的方法。有多种计算效果大小的方法,例如用于计算两个变量之间的相关性的皮尔逊相关性,用于测量组之间差异的Cohen d检验,或仅通过计算不同组之间均值的差异即可。
- 样本数量: 统计样本中包含的观察数。
- 显着性:测试中使用的显着性水平(alpha)。
进行功率分析的步骤
- 陈述零假设(H 0 )和替代假设(H A )。
- 陈述Alpha风险等级(重要性等级)。
- 选择适当的统计检验。
- 确定效果大小。
- 创建抽样计划并确定样本量。之后收集样品。
- 通过确定p值来计算测试统计量。
- 如果p值
- 如果p值
- 重复上述步骤几次。
例子
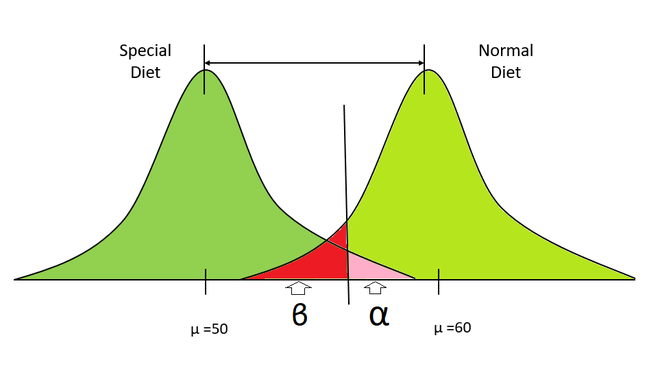
特殊饮食分配与正常饮食分配
- 假设有两个分布代表两组人的体重,左边代表饮食中的人,右边代表食用正常食物的人。
- 我们从分布中抽取一些样本并计算其均值。
- 在这里,我们的原假设是两个样本都来自相同的分布(饮食计划无影响),另一个假设是两个样本都来自不同的分布。
- 现在,我们从这些样本中计算出p值。
- 如果我们的p值小于显着性水平,那么我们将正确地拒绝原假设,即这两个样本均来自同一分布。
- 否则,我们不会拒绝原假设。
- 现在,我们多次重复上述步骤(即1000、10000),等等,并计算正确拒绝零假设(即幂)的概率。
执行:
Python3
# Necessary Imports
import numpy as np
from statsmodels.stats.power import TTestIndPower
import matplotlib.pyplot as plt
# here effect size is taken as (u1-u2) /sd
effect_size = (60-50)/10
alpha = 0.05
samples =20
p_analysis = TTestIndPower()
power = p_analysis.solve_power(effect_size=effect_size, alpha=alpha, nobs1 = samples, ratio =1)
print("Power is ",power)0.8689530131730794