寄存器分配是编译器最后阶段的重要方法。寄存器比高速缓存访问的速度更快。寄存器的大小小至数百Kb,因此必须使用最少数量的寄存器进行变量分配。有三种流行的寄存器分配算法。
- 天真的寄存器分配
- 线性扫描算法
- 柴廷算法
这些解释如下。
1.天真的寄存器分配:
- 天真的(否)寄存器分配基于这样的假设,即变量存储在Main Memory中。
- 我们不能直接对存储在主存储器中的变量执行操作。
- 变量被移到寄存器中,从而允许使用ALU进行各种操作。
- ALU包含一个临时寄存器,在执行算术和逻辑运算之前,会将变量移至其中。
- 一旦操作完成,我们需要使用这种方法将结果存储回主存储器。
- 从主内存来回传递变量降低了执行的整体速度。
a = b + c
d = a
c = a + d存储在主存储器中的变量:
| a | b | c | d |
| 2 fp | 4 fp | 6 fp | 8 fp |
机器级别说明:
LOAD R1, _4fp
LOAD R2, _6fp
ADD R1, R2
STORE R1, _2fp
LOAD R1, _2fp
STORE R1, _8fp
LOAD R1, _2fp
LOAD R2, _8fp
ADD R1, R2
STORE R1, _6fp好处 :
- 易于理解的操作以及变量从主存储器到寄存器的流动,反之亦然。
- 仅2个寄存器就足以执行任何操作。
- 设计复杂度更低。
缺点:
- 随着变量从主存储器移到寄存器中,时间复杂度增加。
- 太多的LOAD和STORE指令。
- 要第二次访问变量,我们需要将其存储到主存储器中以记录所做的任何更改,然后再次加载它。
- 此方法不适用于现代编译器。
2.线性扫描算法:
- 线性扫描算法是一种全局寄存器分配机制。
- 这是一种自下而上的方法。
- 如果在任何时间点都有n个变量存在,那么我们需要’n’个寄存器。
- 在该算法中,对变量进行线性扫描,以确定变量的有效范围,并根据该范围分配寄存器。
- 该算法的主要思想是分配最少数量的寄存器,以便可以再次使用这些寄存器,这完全取决于变量的有效范围。
- 对于这种算法,我们需要对代码优化进行实时变量分析。
a = b + c
d = e + f
d = d + e
IFZ a goto L0
b = a + d
goto L1
L0 : b = a - d
L1 : i = b控制流程图:

- 在此示例中,在任何时间点,活动变量的最大数量为4。因此,我们最多需要4个寄存器来进行寄存器分配。

如果我们在上图的任意点画水平线,我们可以看到我们需要4个寄存器来执行程序中的操作。
分裂:
- 有时可能无法使用所需数量的寄存器。在这种情况下,我们可能需要将一些变量移入和移出RAM。这被称为溢出。
- 通过移动在程序中使用较少次数的变量,可以有效地完成溢出。
缺点:
- 线性扫描算法未考虑变量的“生存期漏洞”。
- 变量在整个程序中并不活跃,并且该算法无法在变量的有效范围内记录漏洞。
3,图着色(Chaitin算法)
- 寄存器分配被解释为图形着色问题。
- 节点代表变量的有效范围。
- 边缘表示两个活动范围之间的连接。
- 给节点分配颜色,使得没有两个相邻节点具有相同的颜色。
- 颜色数量表示所需的最少寄存器数量。
图的k色映射到k个寄存器。
脚步 :
- 选择一个度数小于k的任意节点。
- 将那个节点推入堆栈,并删除所有的输出边缘。
- 检查剩余边的度数是否小于k,如果是,则转到5,否则转到#
- 如果任何剩余顶点的度数小于k,则将其推入堆栈。
- 如果没有更多的边缘可用于推送,并且如果堆栈POP中存在所有边缘,则对每个节点进行着色,以使两个相邻节点都不具有相同的颜色。
- 分配给节点的颜色数是所需的最少寄存器数。
#根据节点的活动范围溢出它们,然后使用相同的k值重试。如果问题仍然存在,则意味着假定的k值不能是寄存器的最小数量。尝试将k值增加1并再次尝试执行整个过程。
对于上述相同的说明,图形着色如下:
假设k = 4
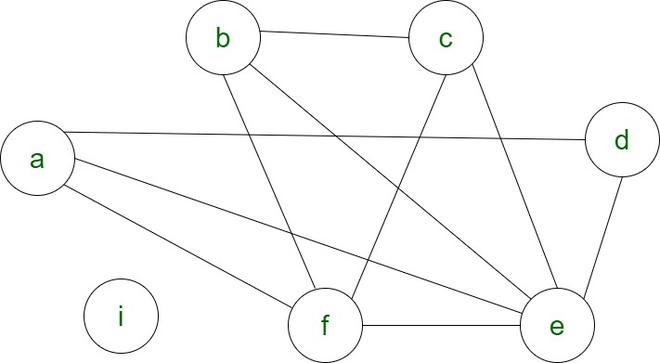
上色前
进行图形着色后,最终图形如下
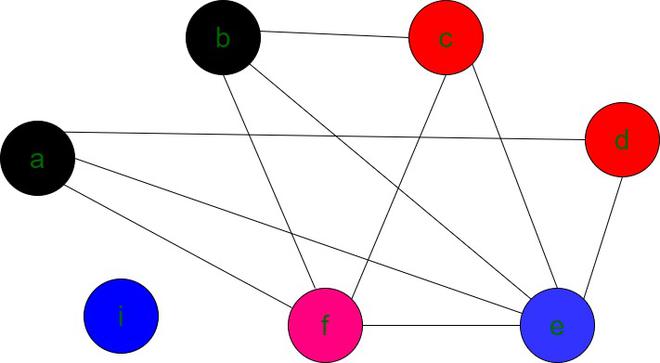
具有k(4)种颜色的最终图形
注意:可以将任何颜色(寄存器)分配给’i’,因为它没有任何其他节点的边缘。