标记算法由编译器在代码生成阶段使用。基本上,该算法用于找出程序完成其执行所需的寄存器数量。标记算法以自下而上的方式工作。我们将首先标记子节点,然后标记内部节点。标记算法的规则是:
- 如果“n”是叶节点——
- 一种。如果“n”是左孩子,则其值为 1。
- 湾如果 ‘n’ 是一个右孩子,那么它的值为 0。
- 如果“n”是一个内部节点——
让我们假设 L1 和 L2 分别是内部节点的左子节点和右子节点。- 一种。如果 L1 == L2 那么 ‘n’ 的值是 L1 + 1 或 L2 + 1
- 湾如果 L1 != L2 那么 ‘n’ 的值是 MAX(L1, L2)
例子:
考虑以下三个地址代码:
t1 = a + b
t2 = c + d
t3 = t1 + t2 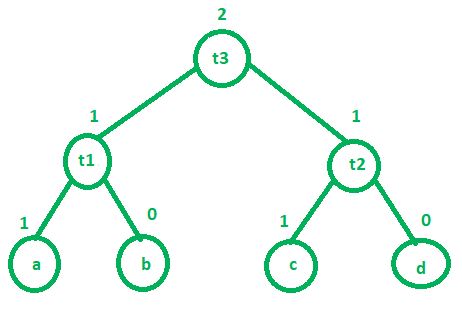
以上三个地址代码最多需要2个寄存器来完成它的执行。
有一个名为 getregister() 的函数,编译器使用它来决定将结果存储在哪里。这个函数有4种情况,如下:
- 如果有一个寄存器 R 没有保存多个值,那么我们可以使用这个寄存器来存储我们的结果的值(在上面的例子中,我们可以将 t3 存储在 R 中,前提是 R 中的当前值没有在任何地方使用该程序。)。
- 如果不满足第一个条件,则编译器将搜索任何空寄存器来存储我们的结果 (t3) 的值。
- 如果没有空寄存器,则将任何寄存器的内容交换到内存中并将结果 (t3) 存储在该寄存器中,前提是这些内容没有任何下次使用。
- 如果所有 3 个条件都不成立,则将结果存储在任何空闲内存位置。