自然语言处理 |拆分和合并块
SplitRule 类:它根据指定的分割模式分割一个块。它被指定为
MergeRule 类:它基于第一个块的结束和第二个块的开始将两个块合并在一起。它被指定为
如何执行这些步骤的示例
- 从句子树开始。

- 分块完成句子。
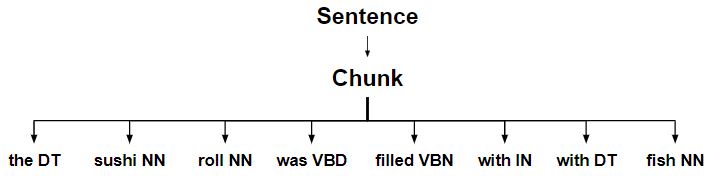
- 块被分成多个块。
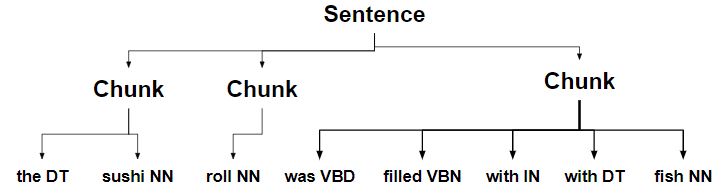
- 带有确定符的块被分成单独的块。
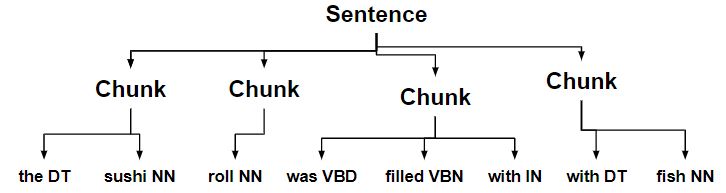
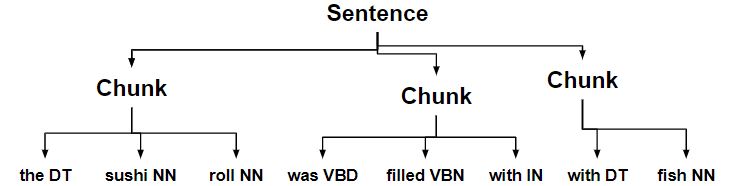
- 以名词结尾的块与下一个块合并。
代码 #1 – 构建树
from nltk.chunk import RegexpParser
chunker = RegexpParser(r'''
NP:
{<.*>*}
}{<.*>
<.*>}{
{}
''')
sent = [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN'), ('was', 'VBD'),
('filled', 'VBN'), ('with', 'IN'), ('the', 'DT'), ('fish', 'NN')]
chunker.parse(sent)
输出:
Tree('S', [Tree('NP', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Tree('NP', [('was', 'VBD'), ('filled', 'VBN'), ('with', 'IN')]),
Tree('NP', [('the', 'DT'), ('fish', 'NN')])])
代码 #2 – 拆分和合并
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk.regexp import MergeRule, SplitRule
# Chunk String
chunk_string = ChunkString(Tree('S', sent))
print ("Chunk String : ", chunk_string)
# Applying Chunk Rule
ur = ChunkRule('<.*>*', 'chunk determiner to noun')
ur.apply(chunk_string)
print ("\nApplied ChunkRule : ", chunk_string)
# Splitting
sr1 = SplitRule('', '<.*>', 'split after noun')
sr1.apply(chunk_string)
print ("\nSplitting Chunk String : ", chunk_string)
sr2 = SplitRule('<.*>', '', 'split before determiner')
sr2.apply(chunk_string)
print ("\nFurther Splitting Chunk String : ", chunk_string)
# Merging
mr = MergeRule('', '', 'merge nouns')
mr.apply(chunk_string)
print ("\nMerging Chunk String : ", chunk_string)
# Back to Tree
chunk_string.to_chunkstruct()
输出:
Chunk String :
Applied ChunkRule : { }
Splitting Chunk String : { }{}{ }
Further Splitting Chunk String : { }{}{ }{ }
Merging Chunk String : { }{ }{ }
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Tree('CHUNK', [('was', 'VBD'), ('filled', 'VBN'), ('with', 'IN')]),
Tree('CHUNK', [('the', 'DT'), ('fish', 'NN')])])