语法树 - 自然语言处理
自然语言处理 (NLP)是一个研究领域,涉及使用计算机理解、解释和操纵人类口语。
由于大多数重要信息都是用英语、法语、德语等自然语言写下来的,因此,NLP 可以帮助计算机以人类自己的语言与人类交流并执行其他与语言相关的任务。
总之,NLP 使计算机能够阅读文本、听到语音、解释和实现它、理解情感并识别文本或语音的重要部分。
什么是语法?
自然语言通常遵循层次结构,并包含以下组件:
- 句子
- 条款
- 短语
- 字
句法是指控制自然语言中句子结构的一组规则、原则和过程。句法的一个基本描述是不同的词,如主语、动词、名词、名词短语等如何在句子中排序。
自然语言的一些句法类别如下:
- 句子)
- 名词短语(NP)
- 限定词(Det)
- 动词短语(VP)
- 介词短语(PP)
- 动词(五)
- 名词(N)
语法树:
语法树或解析树是句子的不同句法类别的树表示。它帮助我们理解句子的句法结构。
例子:
下面给出的句子的语法树如下:
我开车去我的大学。
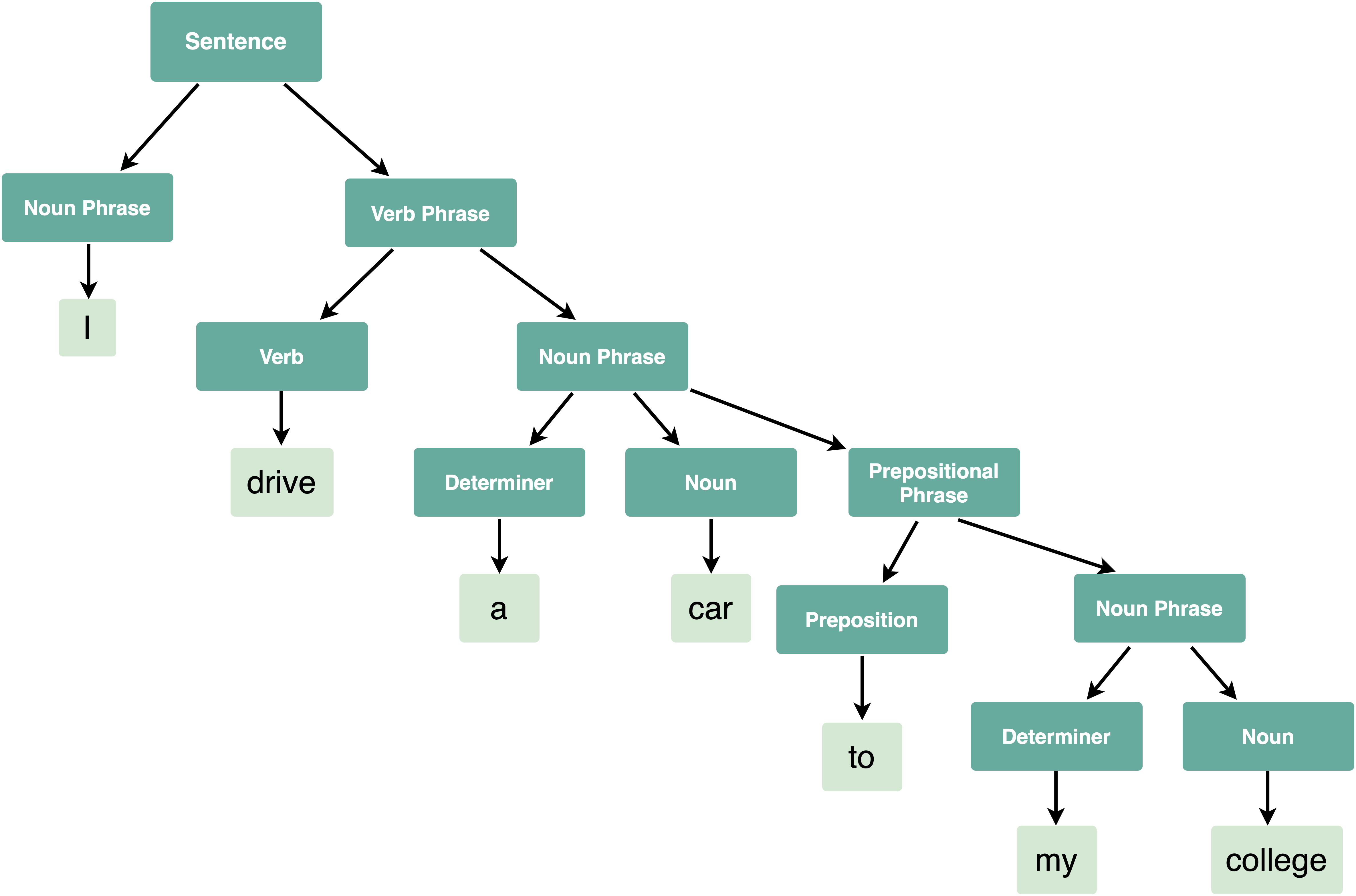
代码: Python中的语法树
Python3
# Import required libraries
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk import pos_tag, word_tokenize, RegexpParser
# Example text
sample_text = "The quick brown fox jumps over the lazy dog"
# Find all parts of speech in above sentence
tagged = pos_tag(word_tokenize(sample_text))
#Extract all parts of speech from any text
chunker = RegexpParser("""
NP: {?*} #To extract Noun Phrases
P: {} #To extract Prepositions
V: {} #To extract Verbs
PP: {
} #To extract Prepositional Phrases
VP: { *} #To extract Verb Phrases
""")
# Print all parts of speech in above sentence
output = chunker.parse(tagged)
print("After Extracting\n", output)
Python3
# To draw the parse tree
output.draw()输出:

代码:为上面的句子免费绘制语法
Python3
# To draw the parse tree
output.draw()
输出:
