考虑以下两个Java程序,第一个程序产生的输出为“Yes”,而第二个程序产生的输出为“No”。你能猜出原因吗?
// Program 1: Comparing two references to objects
// created using literals.
import java.util.*;
class GFG {
public static void main(String[] args)
{
String s1 = "abc";
String s2 = "abc";
// Note that this == compares whether
// s1 and s2 refer to same object or not
if (s1 == s2)
System.out.println("Yes");
else
System.out.println("No");
}
}
Yes
// Program 2: Comparing two references to objects
// created using new operator.
import java.util.*;
class GFG {
public static void main(String[] args)
{
String s1 = new String("abc");
String s2 = new String("abc");
// Note that this == compares whether
// s1 and s2 refer to same object or not
if (s1 == s2)
System.out.println("Yes");
else
System.out.println("No");
}
}
No
让我们通过下面的解释来理解为什么我们得到不同的输出。
字符串是一个字符序列。 Java字符串最重要的特性之一是它们是不可变的。换句话说,一旦创建,字符串的内部状态在整个程序执行过程中保持不变。这种不变性是通过在堆中使用一个特殊的字符串常量池来实现的。在本文中,我们将了解字符串的存储。
字符串常量池是堆内存中的一个单独位置,用于存储程序中定义的所有字符串的值。当我们声明一个字符串,在栈中创建一个 String 类型的对象,而在堆中创建一个具有字符串值的实例。在将值标准分配给字符串变量时,变量被分配到堆栈中,而值存储在字符串常量池的堆中。例如,让我们为字符串str1 分配一些值。在Java,定义了一个字符串并将其赋值为:
String str1 = "Hello";
下图解释了上述声明的内存分配:
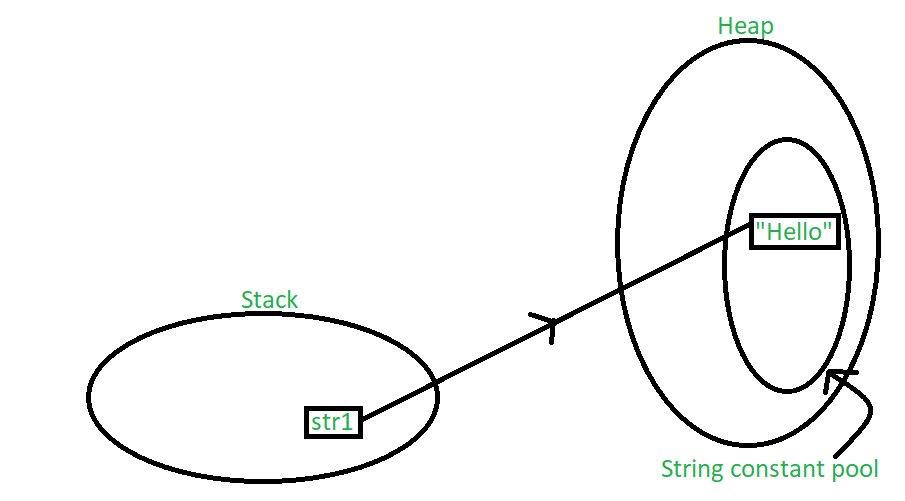
在上面的场景中,在栈中创建了一个字符串对象,在堆中创建并存储了值“Hello”。由于我们已经正常赋值了,所以它存储在堆的常量池区域中。一个指针从堆栈中的对象指向存储在堆中的值。现在,让我们以具有相同值的多个字符串变量为例,如下所示:
String str1 = "Hello";
String str2 = "Hello";
下图解释了上述声明的内存分配:
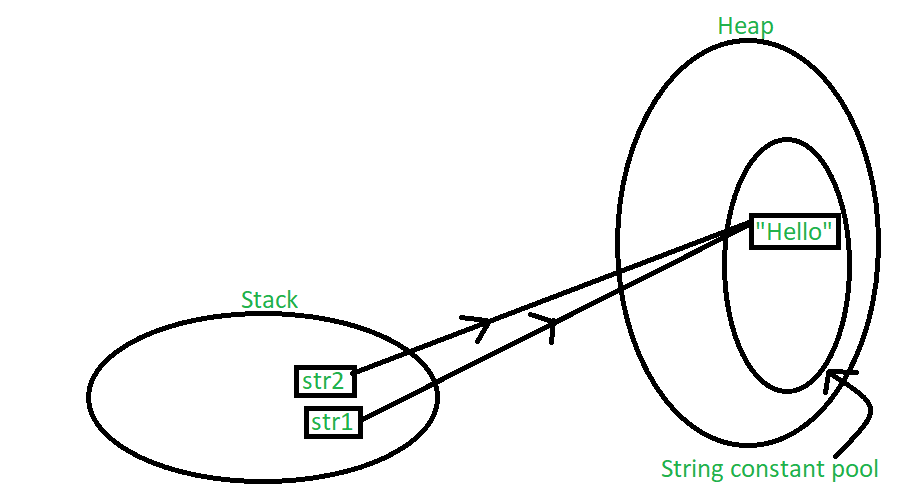
在这种情况下,两个字符串对象都在堆栈中创建,但在堆中没有创建值“Hello”的另一个实例。相反,会重新使用先前的“Hello”实例。字符串常量池是驻留在堆中的一个小缓存。 Java在直接分配时将所有值存储在字符串常量池中。这样,如果需要再次访问类似的值,堆栈中创建的新字符串对象可以借助指针直接引用。换句话说,字符串常量池的存在主要是为了减少内存使用,提高内存中现有实例的重用率。当一个字符串对象被分配一个不同的值时,新值将作为一个单独的实例在字符串常量池中注册。让我们通过以下示例来理解这一点:
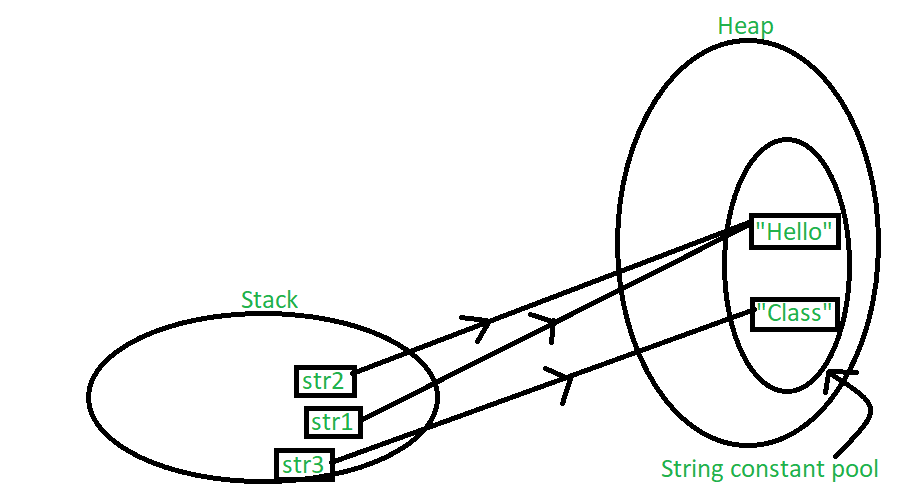
String str1 = "Hello";
String str2 = "Hello";
String str3 = "Class";
下图解释了上述声明的内存分配:
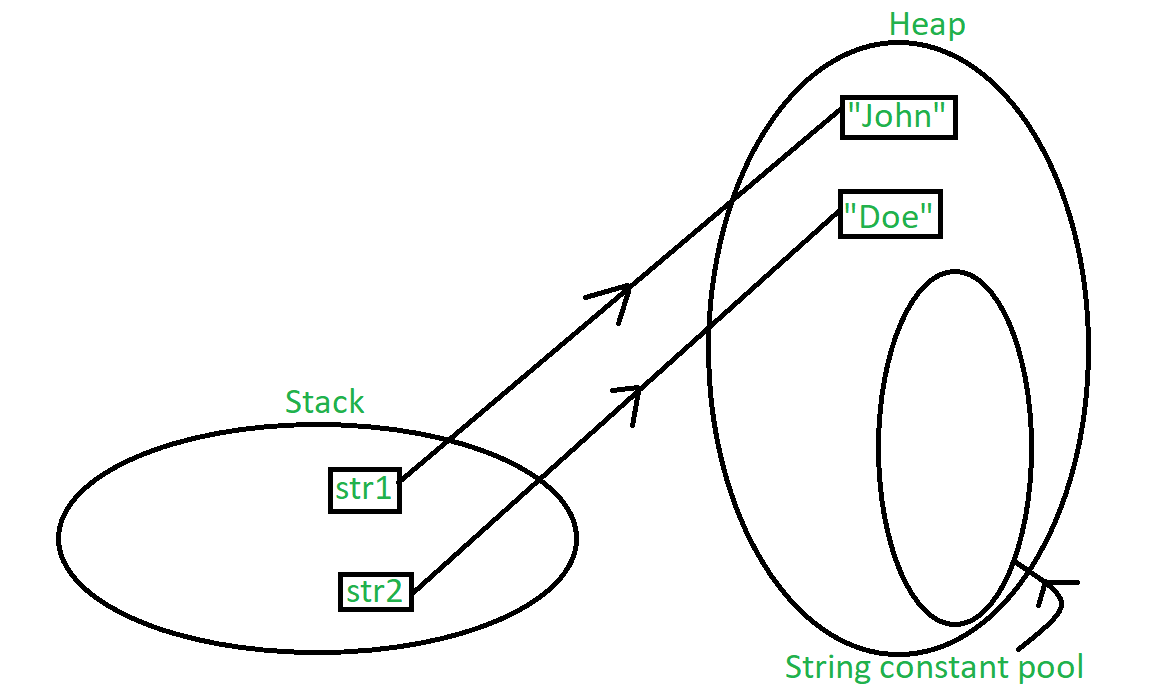
跳过此内存分配的一种方法是在创建新字符串对象时使用 new 关键字。 ‘new’ 关键字强制总是创建一个新实例,无论之前是否使用过相同的值。使用“new”强制在字符串常量池外的堆中创建实例,这很清楚,因为这里不允许缓存和重用实例。让我们通过一个例子来理解这一点:
String str1 = new String("John");
String str2 = new String("Doe");
下图解释了上述声明的内存分配: