先决条件 –数据挖掘
数据挖掘的动机是识别现有数据中有效、可能有利且可理解的联系和模式。数据库技术已经变得更加发达,大量数据需要存储在数据库中,而隐藏在这些数据集中的知识财富被业务人员收集,作为制定业务重要决策的可用工具。数据挖掘然后吸引更多的意识,因为它有义务从原始数据中提取有价值的信息,企业可以使用这些信息通过有利可图的决策过程来有利地扩大其规模。
数据挖掘用于描述数据库中的智能;它是使用数学、统计、人工智能和机器学习技术从数据库中提取和识别有用信息和后续知识的过程。数据挖掘整合了许多不同的算法来完成不同的任务。所有这些算法都将模型同化到数据中。算法检查数据并调制最接近被检查数据特征的数据。数据挖掘算法可以描述为由三部分组成。
模型——模型的目标是在数据中拟合模型。
偏好 –必须使用某些识别测试来拟合一个模型而不是另一个模型。
搜索 –所有算法都是处理查找数据所必需的。
数据挖掘模型的类型–
- 预测模型
- 描述性模型
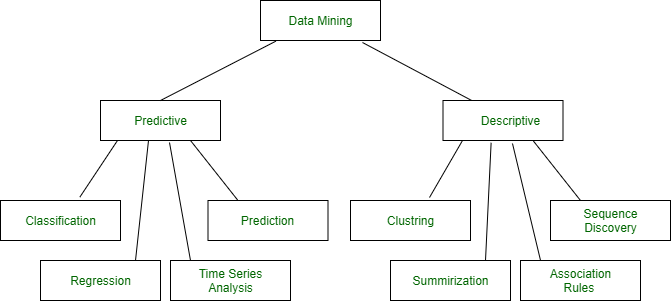
数据挖掘模型
预测模型:
预测模型使用从各种数据中发现的已知结果构成数据的预测关注值。可以基于变体历史数据的使用进行预测建模。预测模型数据挖掘任务包括回归、时间序列分析、分类、预测。
预测模型被称为统计回归。它是一种监控学习技术,它结合了类似项目中少数属性值对其他属性值的依赖性的解释以及可以预测这些属性值的模型的增长最近案例。
- 分类 –
它是将对象分配给几个预定义类别之一的行为。或者我们可以将分类定义为目标函数的学习函数,该函数将每个属性设置为预定义的类标签。 - 回归——
它用于适当的数据。它是一种验证函数数据值的技术。有两种类型的回归——
1.线性回归与寻找适合两个属性的最佳线相关联,以便可以应用一个属性来预测另一个。
2.多线性回归涉及两个或两个以上的属性,数据适合多维空间。 - 时间序列分析——
它是一组基于时间的数据。时间序列分析作为自变量来及时估计因变量。 - 预言 –
它预测一些缺失或未知的值。
描述型号:
描述性模型区分数据中的关系或模式。与预测模型不同,描述性模型作为一种探索被检查数据属性的方式,而不是预测新属性,聚类、汇总、关联规则和序列发现是描述性模型数据挖掘任务。
描述性分析 专注于将数据汇总和转换为用于监控和报告的重要信息。
- 聚类——
它是将一组抽象对象转换为相同对象类的技术。 - 总结——
它以更深入、更易于理解的形式保存一组数据。 - 关联规则 –
他们发现了大量数据对象之间令人兴奋的一致性或因果关系。 - 顺序 –
数据中有趣模式的发现与对数据有趣程度的客观或主观测量有关。