数据挖掘可能是应用科学中的一个术语。通常,它还被称为数据库中的数据发现(KDD)。数据处理涉及在大量知识中查找新信息。希望从数据处理中获得的数据是每一个新的和有用的。
在职的:
在某些情况下,信息会保留下来;因此,可能会在以后使用。数据随目标一起保存。例如,商店需要保存大量已购买的商品。他们需要尝试执行此操作以掌握应购买的数量,以拥有足够的数量供以后出售。保存此信息会带来很多知识。有时,信息会被保留为超出信息。为何保留信息的解释被称为主要用途。
以后,常量信息也可能不会获得主要用途不需要的替代信息。商店可能需要掌握当前个人在商店购物后会合理购买的东西。 (例如,许多购买食物的人还额外购买了蘑菇。)这类{信息|信息|}在数据之内并且是有益的,但是,这并不是解释为什么保存该数据的原因。此信息是新信息,可能会有所帮助。这是常量信息的第二种用法。查找新信息甚至可以从信息中获得帮助,这被称为数据处理。
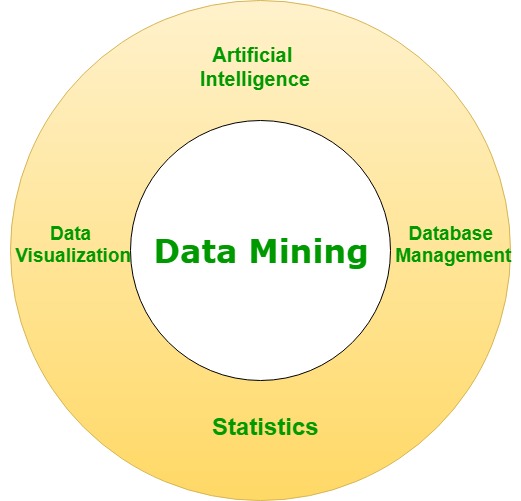
对于数据,有大量各种数据处理可用于获取新信息。通常情况下,预测是有关的;预期结果中存在不确定性。随后的观察结果是,我们有一点经验不足的苹果可以在结构上更改我们的信息。多种数据处理方式包括:
模式识别(试图在报表的行内,规则类型内寻找相似之处。tiny->经验不足。(小苹果方形通常为绿色)
使用一个定理网络(尝试创建一件事,这将说明各种信息属性平方度量相互关联/相互影响。尺寸和颜色平方度量相关。因此,如果您认识到涉及方面的一件事,则可以猜猜颜色。)
使用神经网络(试图创建模型模型的大脑,这很难掌握;但是,一台PC会告诉您,如果苹果经验不足,那么如果我们倾向于对PC说,那是下一个可能会很痛苦的可能性。苹果是没有经验的。因此,这通常是一种记录器模型,我们倾向于不精打细算,但是它仍然有效。)
使用分类树(由于所有替代数据都试图提及与此问题相关的一个替代问题,因此我们倾向于平方测量观察。这是将苹果与大小,颜色和光泽相关联的方式,它的风格如何? )
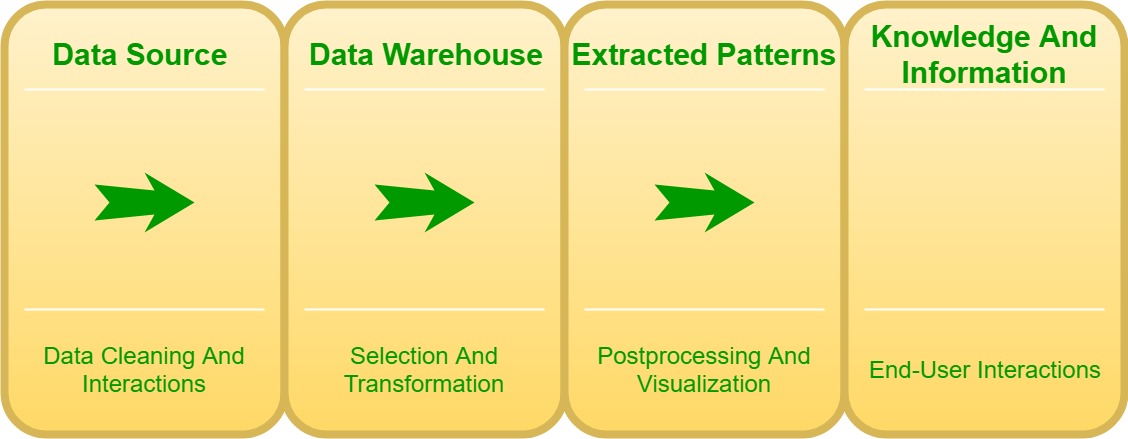
数据挖掘需要信息准备,这可能会发现可能损害机密性和隐私义务的信息或模式。发生这种情况的标准方法是通过信息聚合。信息聚合涉及以一种有助于分析的非常有效的方式(可能来自多个来源)组合信息(但另外可能会建立对个人,个人级别的演绎信息或其他明显信息的识别)。这可能不是本质上的数据处理,而是分析之前(并根据需要)准备数据的结果。
一旦信息被编译,导致信息体力劳动者或任何联合国机构可以使用最近编译的信息集,以准备确定特定人员,对人格隐私的威胁就开始发挥作用,尤其是一旦信息是先前的信息。匿名的。
数据也可能会改变;因此,要成为匿名者,这样人们可能不会立即被认识。但是,即使“去标识” /“匿名”的信息集也无疑会包含足够的信息以进行身份识别,就像记者准备好意识到许多人支持由AOL不知情地释放的一组搜索历史记录一样。