在本文中,我们将讨论 Cassandra 中的数据分布以及数据如何在集群上分布。那么,让我们来看看。
在 Cassandra 中,数据分发和复制一起进行。在 Cassandra 中分发和复制取决于三件事,例如分区键、键值和令牌范围。
卡桑德拉表:
在此表中有两行,其中一行包含四列及其值。第二行包含两列(第 1 列和第 3 列)及其值。在此表中,第 1 列具有主键。

现在,让我们举一个例子来说明用户数据如何在集群上分布。
| E_id | E_name | E_sal |
|---|---|---|
| 101 | Ashish | 90000 |
| 102 | Aayush | 95000 |
| 103 | Rahul | 70000 |
| 104 | Abi | 60000 |
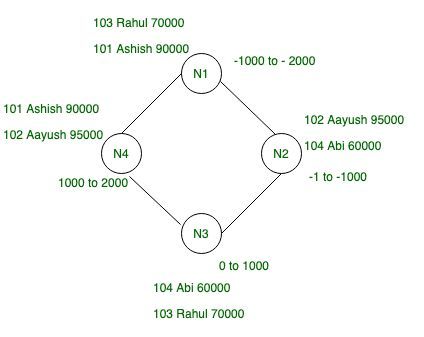
下面给定的四个节点的给定环架构具有令牌范围,每一行都有自己的令牌 ID,因此,在分区器的帮助下,我们将生成令牌值并分配它们并相应地分布在集群上。
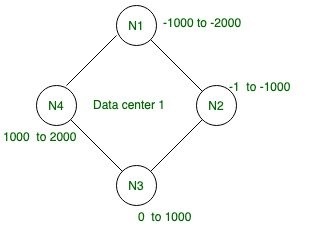
令牌:令牌是散列值,Murmur3 散列算法用于 Cassandra 中的散列,分区器使用它来确定在环中的每个节点上存储行的位置。
例如:让我们为上表中给定数据的每一行取随机哈希值。
| Partition key | Murmur3 Hash value |
|---|---|
| Ashish | 1500 |
| Aayush | -800 |
| Rahul | -1500 |
| Abi | 700 |
让我们来看看更好的理解。
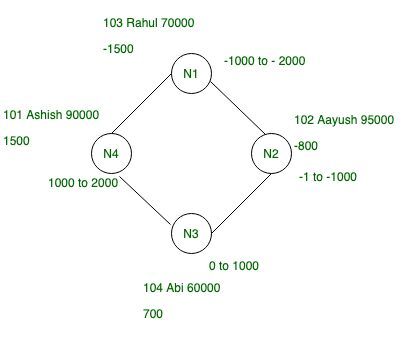
复制因子:在 Cassandra 中,复制因子非常重要,它表示集群中的副本总数。
让我们取 RF = 2,这意味着每行有两个副本。 Cassandra 中没有主副本或主副本。