探索数据分布 |设置 1
每当我们从事数据科学和机器学习工作时,我们处理数据并从中找到有用信息的方法都是基于数据的分布。
分布意味着数据如何以不同的可能方式呈现,特定数据的百分比,识别异常值。所以,数据分布就是用图形化的方法来组织和展示有用信息的方式。
与探索数据分布相关的术语
-> Boxplot
-> Frequency Table
-> Histogram
-> Density Plot
- 箱线图:它基于数据的百分位数,如下图所示。箱线图的顶部和底部分别是数据的第 75 和第 25 个百分位数。延长线称为须线,包括其余数据的范围。

要获取所使用的
csv文件的链接,请单击此处。代码 #1:加载库
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt代码 #2:加载数据
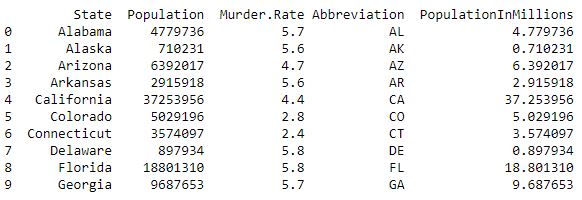
data = pd.read_csv("../data/state.csv") # Adding a new column with derived data data['PopulationInMillions'] = data['Population']/1000000 print (data.head(10))输出 :
代码#3:箱线图
# BoxPlot Population In Millions fig, ax1 = plt.subplots() fig.set_size_inches(9, 15) ax1 = sns.boxplot(x = data.PopulationInMillions, orient ="v") ax1.set_ylabel("Population by State in Millions", fontsize = 15) ax1.set_title("Population - BoxPlot", fontsize = 20)输出 :

- 频率表:它是一种将数据分布到等距范围、段中的工具,并告诉我们每个段中有多少值。
代码 #1:添加一列以执行交叉表和分组功能。
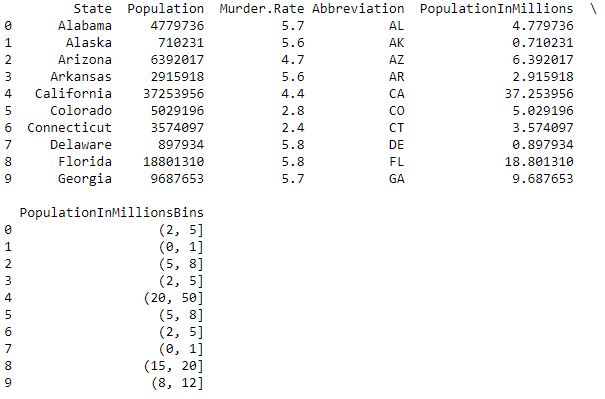
# Perform the binning action, the bins have been # chosen to accentuate the output for the Frequency Table data['PopulationInMillionsBins'] = pd.cut( data.PopulationInMillions, bins =[0, 1, 2, 5, 8, 12, 15, 20, 50]) print (data.head(10))输出 :
代码#2:交叉表——一种频率表
# Cross Tab - a type of Frequency Table pd.crosstab(data.PopulationInMillionsBins, data.Abbreviation, margins = True)输出 :

代码#3: GroupBy——一种频率表
# Groupby - a type of Frequency Table data.groupby(data.PopulationInMillionsBins)['Abbreviation'].apply(', '.join)输出 :
