数据以非常适合挖掘数据的方式进行转换。数据转换包括以下步骤:
1.平滑:
这是一个使用某些算法从数据集中去除噪声的过程,它允许突出显示数据集中存在的重要特征。它有助于预测模式。在收集数据时,可以对其进行操作以消除或减少任何差异或任何其他噪声形式。
数据平滑背后的概念是它能够识别简单的变化以帮助预测不同的趋势和模式。这对需要查看大量数据的分析师或交易员很有帮助,这些数据通常难以消化以找到他们不会看到的模式。
2. 聚合:
数据收集或聚合是以摘要格式存储和呈现数据的方法。可以从多个数据源中获取数据,以将这些数据源集成到数据分析描述中。这是至关重要的一步,因为数据分析洞察的准确性在很大程度上取决于所使用数据的数量和质量。收集高质量和足够大数量的准确数据对于产生相关结果是必要的。
数据的收集对于从有关产品的融资或业务策略、定价、运营和营销策略的决策等所有方面都很有用。
例如,销售数据可以汇总以计算每月和每年的总金额。
3. 离散化:
它是将连续数据转换为一组小区间的过程。现实世界中的大多数数据挖掘活动都需要连续的属性。然而,许多现有的数据挖掘框架无法处理这些属性。
此外,即使数据挖掘任务可以管理连续属性,它也可以通过用离散值替换恒定质量属性来显着提高其效率。
例如,(1-10, 11-20)(年龄:- 青年,中年,老年)。
4. 属性构建:
创建和应用新属性以帮助从给定属性集进行挖掘过程的地方。这简化了原始数据并使挖掘更高效。
5. 泛化:
它使用概念层次结构将低级数据属性转换为高级数据属性。例如,年龄最初以数字形式 (22, 25) 转换为分类值(年轻、年老)。
例如,类别属性(例如房屋地址)可以推广到更高级别的定义,例如城镇或国家/地区。
6. 归一化:数据归一化涉及将所有数据变量转换为给定范围。
用于规范化的技术有:
- 最小-最大归一化:
- 这将线性转换原始数据。
- 假设:min_A 是最小值,max_A 是属性的最大值,P
我们有公式:

- 其中 v 是您要在新范围内绘制的值。
- v’ 是对旧值进行归一化后得到的新值。
解决的例子:
假设属性利润(P)的最小值和最大值是 Rs。 10, 000 和卢比。 100, 000。我们想在 [0, 1] 范围内绘制利润。使用最小-最大归一化 Rs 的值。 20, 000 的属性利润可以绘制为: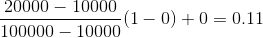
因此,我们得到 v’ 的值为 0.11
- Z-Score 归一化:
- 在 z 分数归一化(或零均值归一化)中,属性 (A) 的值根据 A 的均值及其标准差进行归一化
- 通过计算将属性 A 的值 v 归一化为 v’

例如:
假设属性 P 的平均值为 P = 60, 000,标准偏差 = 10, 000,对于属性 P。使用 z-score 归一化,P 的值 85000 可以转换为: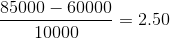
因此我们得到 v’ 的值为 2.5
-
十进制缩放:
- 它通过改变属性的小数点位置来规范化属性的值
- 小数点移动的点数可以由属性A的绝对最大值决定。
- 通过计算将属性 A 的值 v 归一化为 v’
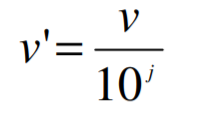
- 其中 j 是满足 Max(|v’|) < 1 的最小整数。
例如:
- 假设:属性 P 的值在 -99 到 99 之间变化。
- P 的最大绝对值为 99。
- 为了对值进行标准化,我们将数字除以 100(即 j = 2)或(最大数字中的整数数),以便得出的值为 0.98、0.97 等。