数据集成是一种数据预处理技术,涉及将来自多个异构数据源的数据组合到一个一致的数据存储中,并提供数据的统一视图。这些源可能包括多个数据多维数据集,数据库或平面文件。
数据集成方法正式定义为三元组
G代表整体架构,
S代表模式的异构源,
M代表源查询和全局架构查询之间的映射。
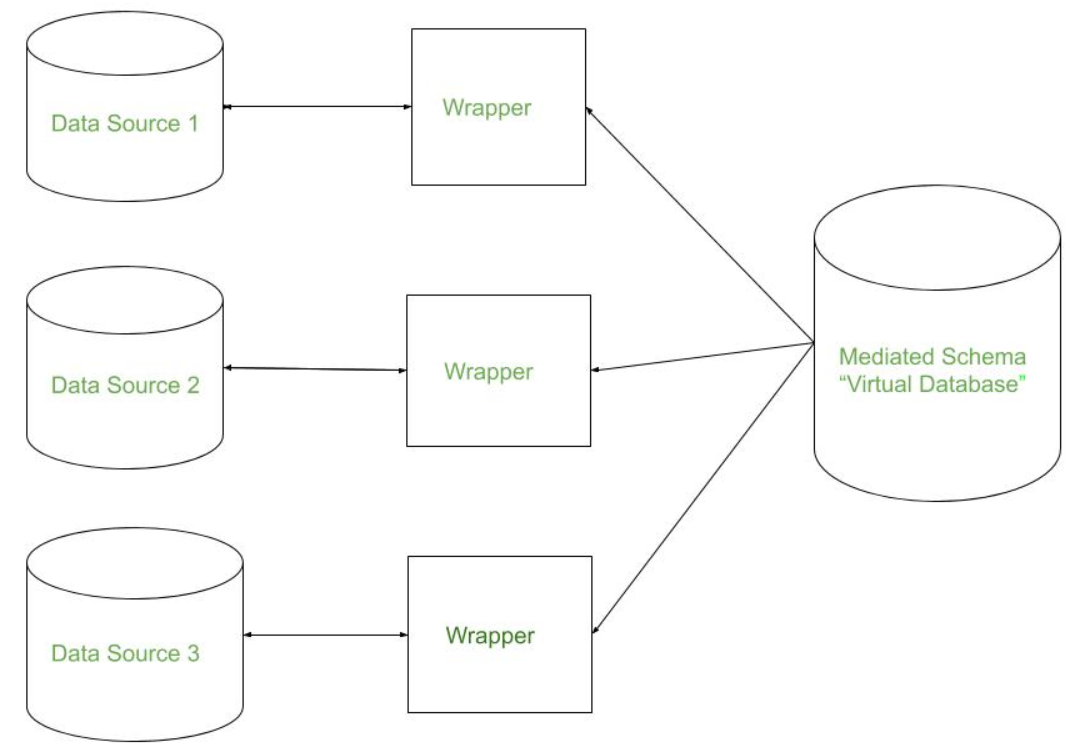
数据集成主要有2种主要方法-一种是“紧密耦合方法”,另一种是“松散耦合方法”。
紧耦合:
- 在这里,数据仓库被视为信息检索组件。
- 在这种耦合中,通过ETL(提取,转换和加载)过程将数据从不同源组合到单个物理位置。
松耦合:
- 这里,提供了一个接口,该接口从用户那里获取查询,以源数据库可以理解的方式对其进行转换,然后将查询直接发送到源数据库以获取结果。
- 并且数据仅保留在实际的源数据库中。
数据集成中的问题:
数据集成期间没有要考虑的问题:模式集成,冗余,数据值冲突的检测和解决。简要解释如下。
1.模式集成:
- 集成来自不同来源的元数据。
- 来自多个源的现实世界实体被匹配称为实体标识问题。
例如,数据分析师和计算机如何确保一个数据库中的客户ID和另一引用中的客户编号引用同一属性。
2.冗余:
- 如果某个属性可以从另一个属性或一组属性中派生或获取,则它可能是多余的。
- 属性不一致还会导致结果数据集中出现冗余。
- 相关分析可以检测出一些冗余。
3.检测和解决数据值冲突:
- 这是数据集成中的第三个重要问题。
- 对于同一真实世界实体,来自其他不同来源的属性值可能会有所不同。
- 一个系统中的属性可以记录在比另一个系统中的“相同”属性更低的抽象级别上。