SQL 中的 GROUP BY 语句用于借助一些函数将相同的数据分组。即,如果特定列在不同行中具有相同的值,那么它会将这些行排列在一个组中。
要点:
- GROUP BY 子句与 SELECT 语句一起使用。
- 在查询中,GROUP BY 子句放在 WHERE 子句之后。
- 在查询中,GROUP BY 子句放在 ORDER BY 子句之前(如果有的话)。
语法:
SELECT column1, function_name(column2)
FROM table_name
WHERE condition
GROUP BY column1, column2
ORDER BY column1, column2;
function_name: Name of the function used for example, SUM() , AVG().
table_name: Name of the table.
condition: Condition used.
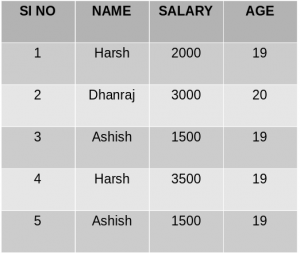
示例表:
员工
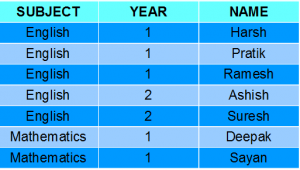
学生
例子:
- 按单列分组:按单列分组是指将所有具有相同值的行放在一个组中。考虑如下所示的查询:
SELECT NAME, SUM(SALARY) FROM Employee GROUP BY NAME;上述查询将产生以下输出:
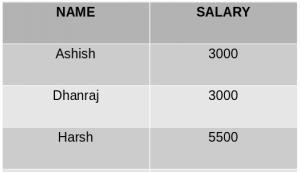
正如您在上面的输出中看到的,具有重复 NAME 的行被分组在相同的 NAME 下,它们对应的 SALARY 是重复行的 SALARY 的总和。这里使用 SQL 的 SUM()函数来计算总和。 - 按多列分组:按多列分组,例如, GROUP BY column1, column2 。这意味着将列column1和column2具有相同值的所有行放在一个组中。考虑以下查询:
SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;输出:
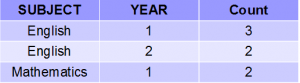
正如您在上面的输出中看到的,具有相同 SUBJECT 和 YEAR 的学生被放置在同一组中。而那些只有 SUBJECT 相同但不是 YEAR 的则属于不同的组。所以这里我们根据两列或多于一列对表格进行了分组。
有条款
我们知道 WHERE 子句用于在列上放置条件但是如果我们想在组上放置条件怎么办?
这就是使用 HAVING 子句的地方。我们可以使用 HAVING 子句来放置条件来决定哪个组将成为最终结果集的一部分。我们也不能使用带有 WHERE 子句的 SUM()、COUNT() 等聚合函数。所以如果我们想在条件中使用这些函数中的任何一个,我们必须使用 HAVING 子句。
语法:
SELECT column1, function_name(column2)
FROM table_name
WHERE condition
GROUP BY column1, column2
HAVING condition
ORDER BY column1, column2;
function_name: Name of the function used for example, SUM() , AVG().
table_name: Name of the table.
condition: Condition used.
示例:
SELECT NAME, SUM(SALARY) FROM Employee
GROUP BY NAME
HAVING SUM(SALARY)>3000;
输出: 
正如你在上面的输出中看到的,三组中只有一组出现在结果集中,因为它是唯一一个 SALARY 总和大于 3000 的组。所以我们在这里使用 HAVING 子句将此条件作为需要将条件放在组而不是列上。