服务定位器模式是一种在软件开发中使用的设计模式,用于用强抽象层封装获取服务所涉及的过程。此模式使用称为“服务定位器”的中央注册表,它根据请求返回执行特定任务所需的信息。
当服务消费者或服务客户端请求服务实例时,ServiceLocator 负责返回服务实例。
UML 图服务定位器模式

设计组件
- Service Locator : Service Locator 抽象了 API 查找服务、供应商依赖性、查找复杂性和业务对象创建,并为客户端提供了一个简单的接口。这降低了客户端的复杂性。此外,同一客户端或其他客户端可以重用服务定位器。
- InitialContext : InitialContext 对象是查找和创建过程的起点。服务提供者提供上下文对象,上下文对象因服务定位器的查找和创建服务提供的业务对象类型而异。
- ServiceFactory : ServiceFactory 对象表示为 BusinessService 对象提供生命周期管理的对象。企业 bean 的 ServiceFactory 对象是一个 EJBHome 对象。
- BusinessService : BusinessService 是由客户端寻求访问的服务实现的角色。 BusinessService 对象由 ServiceFactory 创建、查找或删除。 EJB 应用程序上下文中的 BusinessService 对象是一个企业 bean。
假设类依赖于其具体类型在编译时指定的服务。 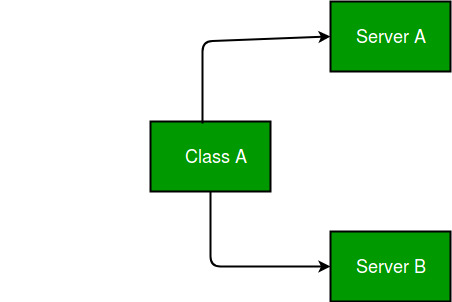
在上图中,ClassA 对ServiceA 和ServiceB 有编译时依赖。但是这种情况有缺点。
- 如果我们想要替换或更新依赖项,我们必须更改类源代码并重新编译解决方案。
- 依赖项的具体实现必须在编译时可用。
通过使用服务定位器模式:
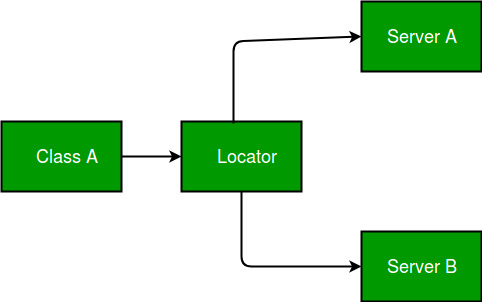
简单来说,服务定位器模式并没有描述如何实例化服务。它描述了一种注册服务并定位它们的方法。
让我们看一个服务定位器模式的例子。
// Java program to
// illustrate Service Design Service
// Locator Pattern
import java.util.ArrayList;
import java.util.List;
// Service interface
// for getting name and
// Executing it.
interface Service {
public String getName();
public void execute();
}
// Service one implementing Locator
class ServiceOne implements Service {
public void execute()
{
System.out.println("Executing ServiceOne");
}
@Override
public String getName()
{
return "ServiceOne";
}
}
// Service two implementing Locator
class ServiceTwo implements Service {
public void execute()
{
System.out.println("Executing ServiceTwo");
}
@Override
public String getName()
{
return "ServiceTwo";
}
}
// Checking the context
// for ServiceOne and ServiceTwo
class InitialContext {
public Object lookup(String name)
{
if (name.equalsIgnoreCase("ServiceOne")) {
System.out.println("Creating a new ServiceOne object");
return new ServiceOne();
}
else if (name.equalsIgnoreCase("ServiceTwo")) {
System.out.println("Creating a new ServiceTwo object");
return new ServiceTwo();
}
return null;
}
}
class Cache {
private List services;
public Cache()
{
services = new ArrayList();
}
public Service getService(String serviceName)
{
for (Service service : services) {
if (service.getName().equalsIgnoreCase(serviceName)) {
System.out.println("Returning cached "
+ serviceName + " object");
return service;
}
}
return null;
}
public void addService(Service newService)
{
boolean exists = false;
for (Service service : services) {
if (service.getName().equalsIgnoreCase(newService.getName())) {
exists = true;
}
}
if (!exists) {
services.add(newService);
}
}
}
// Locator class
class ServiceLocator {
private static Cache cache;
static
{
cache = new Cache();
}
public static Service getService(String name)
{
Service service = cache.getService(name);
if (service != null) {
return service;
}
InitialContext context = new InitialContext();
Service ServiceOne = (Service)context.lookup(name);
cache.addService(ServiceOne);
return ServiceOne;
}
}
// Driver class
class ServiceLocatorPatternDemo {
public static void main(String[] args)
{
Service service = ServiceLocator.getService("ServiceOne");
service.execute();
service = ServiceLocator.getService("ServiceTwo");
service.execute();
service = ServiceLocator.getService("ServiceOne");
service.execute();
service = ServiceLocator.getService("ServiceTwo");
service.execute();
}
}
输出:
Creating a new ServiceOne object
Executing ServiceOne
Creating a new ServiceTwo object
Executing ServiceTwo
Returning cached ServiceOne object
Executing ServiceOne
Returning cached ServiceTwo object
Executing ServiceTwo
好处 :
- 应用程序可以在运行时通过有选择地从服务定位器中添加和删除项目来优化自身。
- 库或应用程序的大部分可以完全分开。它们之间的唯一链接成为注册表。
缺点:
- 注册表使代码更难维护(与使用依赖注入相反),因为不清楚何时引入破坏性更改。
- 注册表隐藏导致运行时错误的类依赖项,而不是在缺少依赖项时出现编译时错误。
策略
以下策略用于实现服务定位器模式:
- EJB 服务定位器策略:此策略使用 EJBHome 对象作为企业 bean 组件,并且此 EJBHome 缓存在 ServiceLocator 中以备将来在客户端再次需要 home 对象时使用。
- JMS 队列服务定位器策略:此策略适用于点对点消息传递需求。以下是JMS Queue Service Locator Strategy 下的策略。
- JMS 队列服务定位器策略
- JMS 主题服务定位器策略
- 类型检查服务定位器策略:此策略具有权衡。它降低了在Services Property Locator 策略中查找的灵活性,但在ServiceLocator.getHome() 方法中添加了传入常量的类型检查。