处理分布式系统中的故障
分布式系统是一组独立的计算机,在客户看来它们是一个单一的内聚系统。任何分布式系统中都有多个组件协同工作以执行任务。随着系统变得更加复杂并包含更多组件,故障的可能性增加,导致可靠性降低。换句话说,我们可以说在分布式系统中,总会有一些系统出现故障,而其他系统则函数。它被称为部分故障。部分故障是不可预测的,因为消息通过网络传输的时间是不确定的,我们无法知道任何事情是成功还是失败。结果,我们不知道哪些系统在此期间发生了故障,也不知道系统是否发生了故障。因此,使用分布式系统很困难。分布式系统中可能出现部分故障,例如节点崩溃或通信连接故障。因此,进程间通信过程中的此类错误可能会导致以下问题:
- 请求消息丢失
- 响应消息丢失
- 请求执行不成功
- 您的请求可能被搁置。
- 远程节点已中断(用于垃圾收集)。
- 请求已由远程节点处理,但响应在网络中丢失。
- 因为我们的网络很拥挤,所以响应会延迟。
1. 请求消息丢失:这种丢失可能发生在发送方-接收方通信链路发生故障时,或者其他原因可能是接收方节点在请求消息到达时未启用。
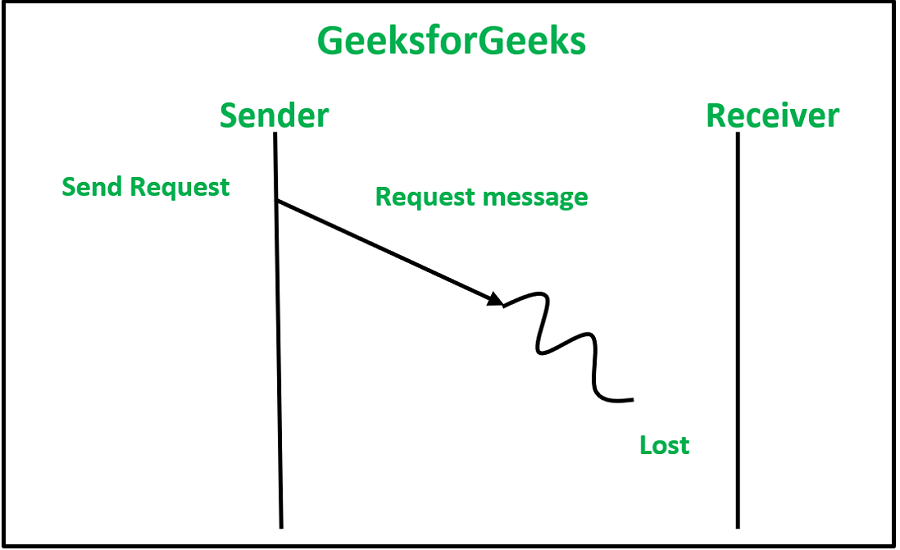
2. 响应消息丢失:这种丢失可能发生在发送方-接收方通信链路发生故障时,或者其他原因可能是发送方节点在响应消息到达时未启用。
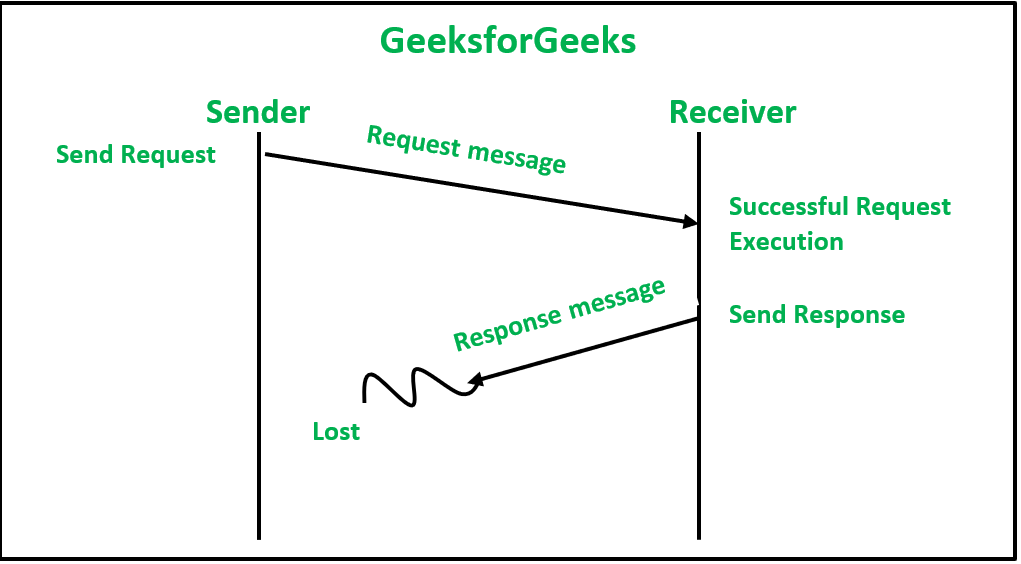
3. 请求执行不成功:当接收者的节点在请求处理过程中崩溃时会发生这种情况。
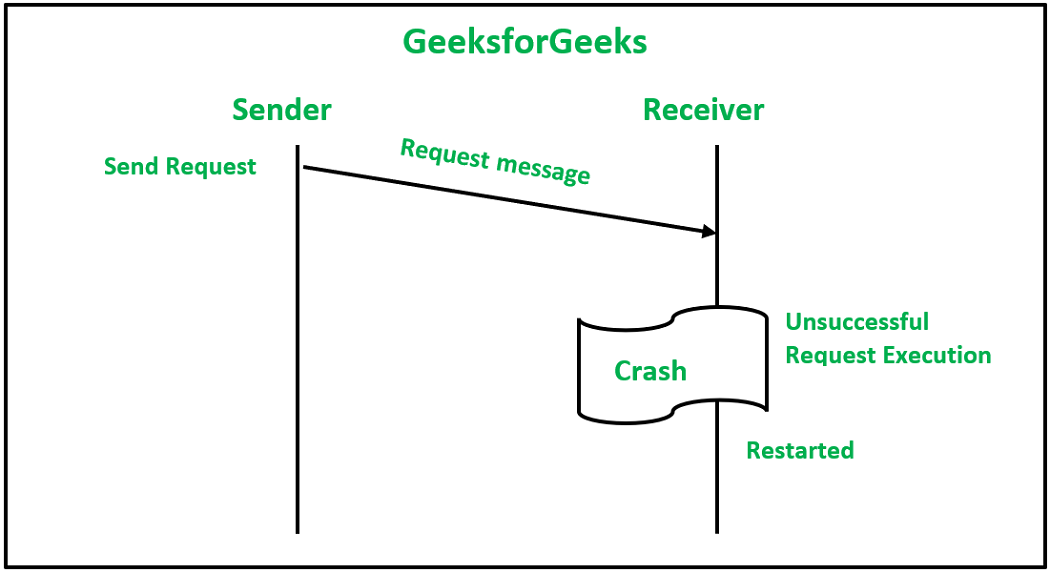
为了处理这些问题,消息传递系统采用可靠的 IPC 协议,该协议处理在固定时间间隔后在内部重新传输消息的概念,并且接收方的内核向发送机器上的内核返回确认消息。
以下可靠的 IPC 协议用于两个进程之间的客户端-服务器通信:
- 四消息可靠IPC协议
- 三消息可靠IPC协议
- 两消息可靠 IPC 协议
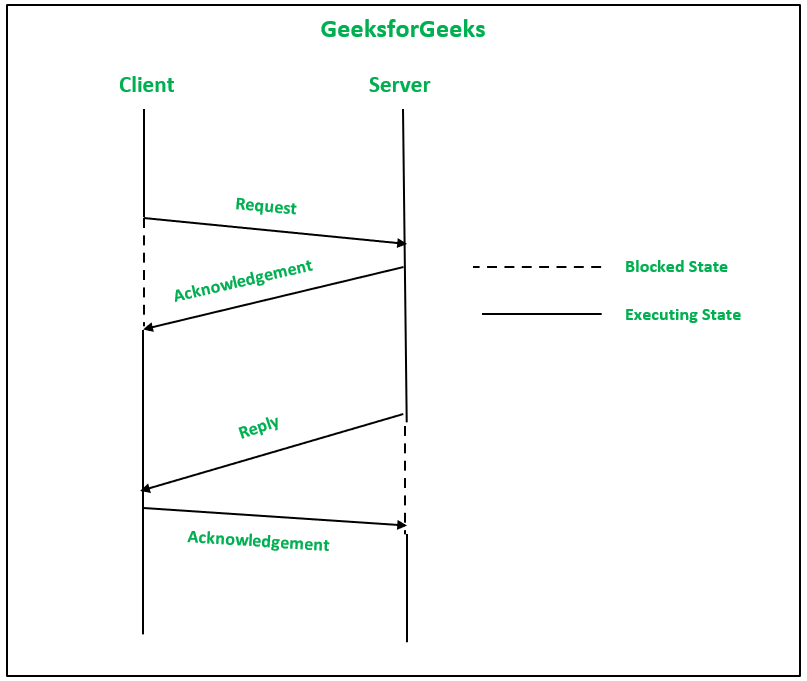
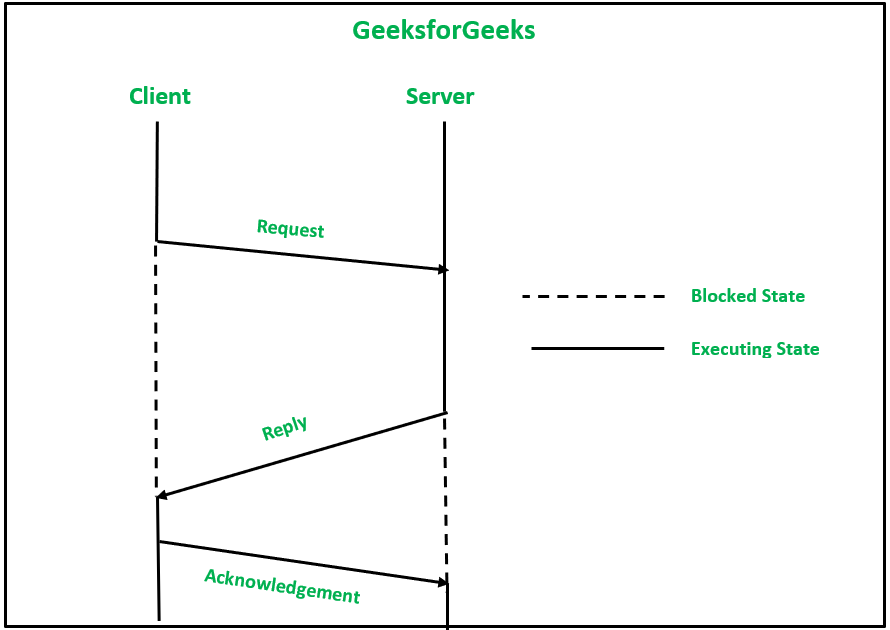
1. 四消息可靠 IPC 协议:在此客户端-服务器中,两个进程之间的通信以下列方式进行:
- 请求消息从客户端发送到服务器。
- 收到请求消息后,确认消息从服务器内核发送到客户端机器上的内核。请求消息的重传也由客户端机器的内核执行,以防在设定的时限内没有收到确认。
- 当服务器为客户端的请求提供服务时,会向客户端发送回复消息。该消息还保存处理结果。
- 现在,一个确认消息从客户端内核发送到服务器机器的内核,以确认响应的接收。如果在设定的时限内没有收到确认,回复消息的重传也由服务器机器的内核执行。
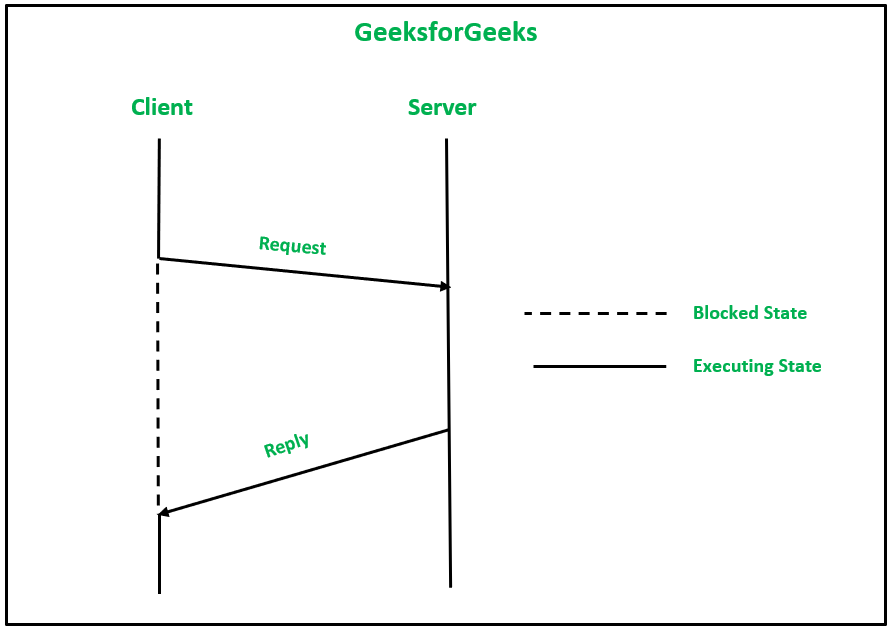
2、三消息可靠IPC协议:当客户端进程收到成功的响应时,它确保在客户端-服务器通信中服务器接收到请求消息。所以,它基于这个概念:
- 请求消息从客户端发送到服务器
- 服务器收到请求消息后,将包含处理结果的回复消息发送给客户端。请求消息的重传也由客户端机器的内核执行,以防在设定的时限内没有收到回复。
- 当服务器为客户端的请求提供服务时,会向客户端发送回复消息。该消息还保存处理结果。现在,客户端的内核向服务器端的内核发送确认。响应消息的重传也由服务器机器的内核执行,以防在设定的时限内没有收到确认。
如果请求需要很长时间来处理,则可能会出现问题。因为消息的重传只能在一组固定的时间间隔后进行,该时间间隔一般设置得很大,以避免浪费的重传。另一方面,如果没有为请求处理设置相当长的时间,则可能导致多次发送请求消息。要处理此问题,请使用以下协议:
- 客户端向服务器发送请求消息。
- 内核在服务器收到请求后立即启动计时器。当客户端在处理请求后收到来自服务器端的回复消息时,则它作为对请求消息的确认。否则,服务器发送一个单独的确认来确认请求消息。如果在超时期限内没有收到确认,也需要进行重传。
- 当客户端收到回复消息时,客户端的内核会向服务器的内核发送确认消息。只有在超时时间内没有收到确认消息,服务器内核才会重新发送回复消息。
3.两消息可靠IPC协议:两消息可靠IPC协议用于两个进程之间的客户端-服务器通信。为了实现它,可以开发一个消息传递系统:
- 客户端向服务器发送请求消息。当请求已经发送,然后 t, 被阻塞,直到服务器响应。
- 当服务器完成对客户端请求的处理后,它会向客户端发送一个回复消息(包括处理结果)。如果在超时间隔内没有收到响应,客户端机器的内核会重新发送请求消息。
幂等性:
幂等性本质上是指“可重复性”。这意味着使用相同的参数多次执行幂等操作,会产生相同的结果而没有副作用。
多数据报消息中需要跟踪丢失和乱序数据包:
完整传输意味着消息的所有数据包都已被发送到的进程接收到,因为每个数据包对于有效完成多数据报消息传输至关重要。因此,简单的方法是独立识别每个包(称为停止等待协议)。多数据报消息(称为爆炸协议)中的第二种方法是对所有数据包使用单个确认数据包。但是,使用此方法时,节点崩溃或通信链路故障可能会导致以下问题:
- 在通信过程中,多数据报消息的一个或多个数据包丢失。
- 数据包的无序接收。
为了处理这些问题,位图方法用于识别消息包。
分布式系统中还可能发生其他各种类型的故障:
- 应用服务器崩溃的原因多种多样,包括数据中心中断、CPU/内存利用率过高、应用程序代码缺陷、停电、自然灾害等等。
- 分布式系统中的服务可以使用 HTTP/TCP 直接通过网络进行通信。两个服务之间的通信不成功可能有多种原因,包括服务不可用、网络问题、依赖失败等。由于级联效应,其中一项服务可能无法完成其义务,从而可能导致整个系统发生故障。
- 这也可能发生在应用程序无法读取或写入数据库然后被称为不成功的情况下,这可能由于多种原因而发生,包括导致数据库不可用的网络问题、由于 CPU/内存使用过多而导致的数据库阻塞,以及数据库服务器宕机。因为数据是任何系统中最关键的组件,所以处理数据库故障至关重要。
- 消息和事件使用队列和流传递,这是至关重要的组件。基础架构问题、无法访问多个节点、未满足最小同步副本数等可能会导致这些故障
上述分布式系统中的其他故障问题可以通过以下方式处理:
- 如果应用程序服务器中的一个节点发生故障,则必须使用自动脚本或手动交互执行轮流替换它。如果整个集群或应用程序服务器出现故障,则可以使用备份集群。它是通过将流量路由到位于同一区域或不同区域内的单独数据中心的备份集群来完成的。
- 如果出现问题,请根据重试策略重试。重试缩短了间歇性故障的恢复时间,但它们可能会加剧问题,因为减少的系统可能需要一些时间来恢复。
- 缓存也可以用作回退来存储大量重复请求的数据,确保在下游发生故障时,最终提供来自缓存的一致数据。但是,由于缓存可能并非在所有使用场景中都有用,因此应温和处理故障,即不应发送错误,而应返回正确的降级答案。
- 处理数据库故障的方式因所处理数据的重要性而异:拥有一个备份数据库,其中包含从主数据库复制的所有数据,可降低单点故障的风险,并且该冗余数据库可用于满足数据需求直到主数据库恢复。在数据库准备好再次承担负载之前,应用程序可能会为即将到来的请求采用回退技术。可以从缓存或冗余数据库提供读取。
- 将消息推送到重复的流或队列以增加冗余。甚至交易通信也不会因此而丢失。在单独的数据中心和可用区中创建资源是实现冗余的最佳方式。如果消息是第 3 层,则可以将其短暂存储在事务日志中。应用程序可以定期重试将消息放入事务日志,直到流恢复。