先决条件 – 散列
分布式系统是由使用分布式中间件连接的自治计算机组成的网络。它们有助于共享不同的资源和功能,为用户提供单一且集成的连贯网络。
在分布式系统中可以实现散列的方法之一是对多个节点进行散列取模。
散列函数可以定义为node_number = hash(key)mod_N ,其中 N 是节点数。
为了向/从节点添加/检索密钥,客户端计算该密钥的哈希值,并使用结果通过查找其 IP 地址来联系适当的节点。如果找到密钥,则检索它,否则将其添加到节点的池中。
例如,客户端要检索 1。它的哈希值 = 7739。它将转到节点号 (7739%3)。因此,它将联系节点 2。如果未找到密钥,则将其添加到池中。

缺点:Rehashing 问题。
假设节点数发生了变化。由于密钥是根据节点数量分配的,由于节点数量发生了变化,散列函数的值将发生变化,因此密钥将被重新分配。
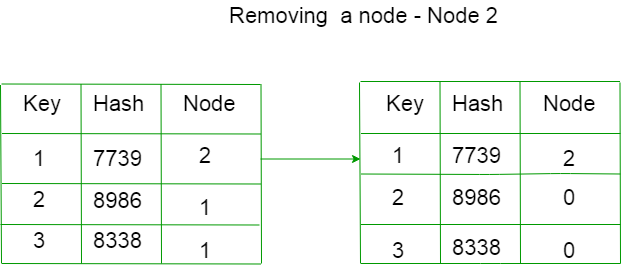
例如,让我们删除 C
每个键的分配节点已更改。
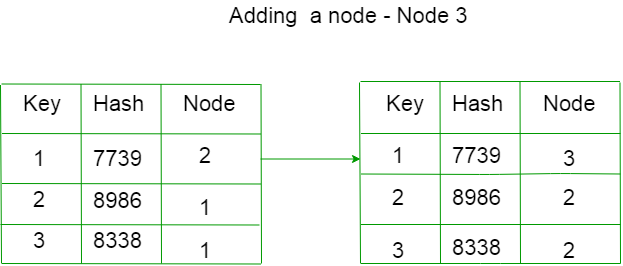
例如,让我们添加一个新节点 D
每个键的分配节点已更改。
因此,每当我们更改节点数量时,分布就会发生变化。
发生的情况是重新分配的次数越多,未命中的次数就越多,内存获取的次数就越多,这会给节点带来额外的负载,从而降低性能。
一致性哈希。
上述问题可以通过Consistent Hashing解决。
由于散列函数不依赖于节点数,因此该方法的操作与节点数无关。这里我们假设形成了一个链/环,我们将密钥和节点放在环上并分发它们。
哈希值可以计算为position_on_chain = hash(key)mod_360
(选择 360 是因为我们用圆圈表示事物。圆圈有 360 度。)
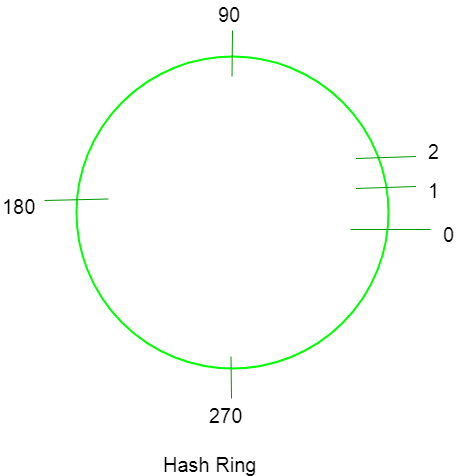
安排步骤——
1) 找到key的Hash值,根据Hash值放在环上。
2) 找到各个节点的Hash值,根据Hash值放在环上。
3)现在将每个键与逆时针方向最接近它的节点映射。
4) 如果节点和键的位置相同,则将该键分配给该节点。
所以,现在要定位一个节点,我们只需从键的位置点开始遍历环,直到我们在逆时针方向找到一个节点。
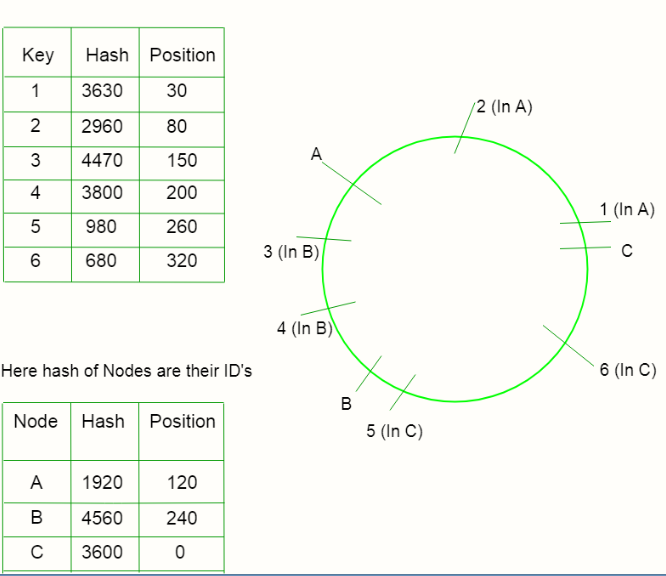
运营——
案例1)添加一个节点——
假设我们通过计算哈希在环中添加一个新节点 D。只有那些值位于 D 和 C 之间的键才会被重新分配。 现在它们不会指向 A,而是指向 D。
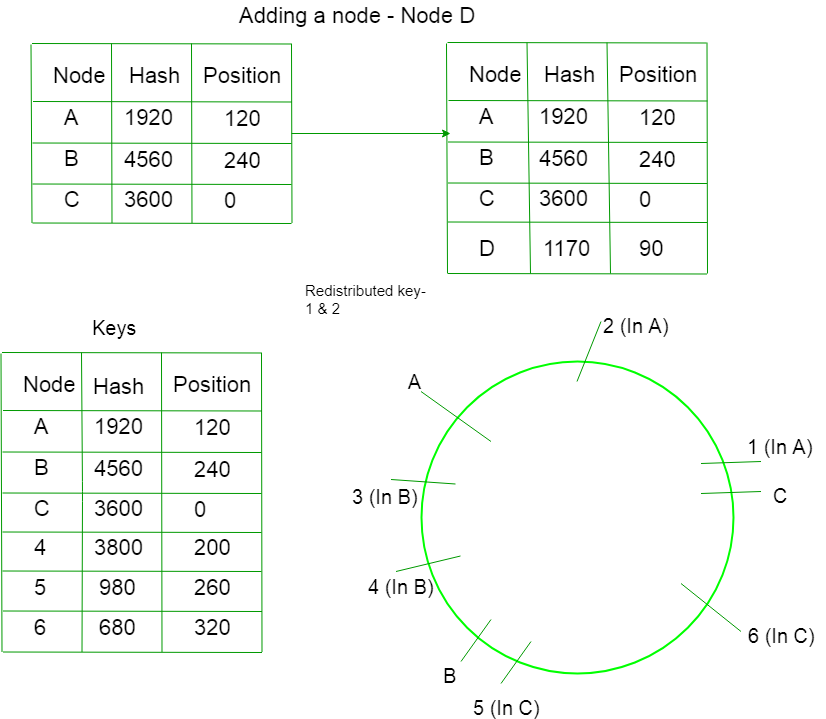
案例 2) 删除节点 –
假设我们删除了环中的一个节点 C。只有那些值位于 C 和 B 之间的键才会被重新分配。 现在它们不会指向 C,而是指向 A。
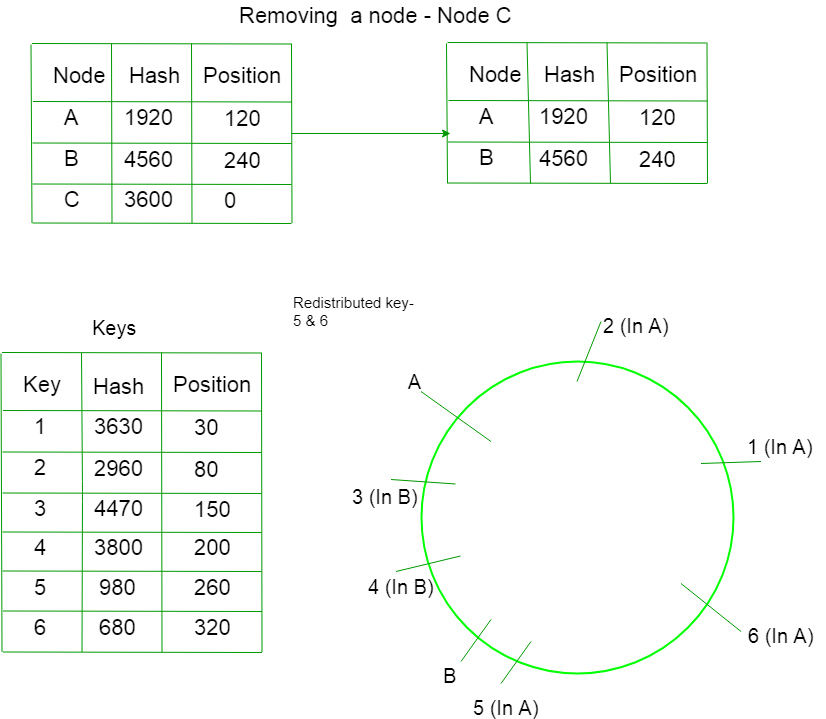
这就是一致性散列如何解决重新散列问题。最小化重新散列后需要重新分配的密钥数量。因此,更少的内存获取。因此,性能得到优化。