机器学习中最容易混淆的两个术语是模型参数和超参数。在这篇文章中,我们将尝试了解这些术语的含义以及它们之间的区别。
什么是模型参数?
模型参数是所选模型的变量,可以通过将给定数据拟合到模型来估计。
例子: 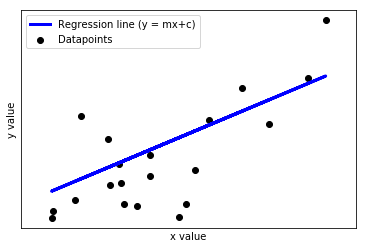
在上图中,x 是自变量,y 是因变量。目标是将回归线拟合到数据中。然后使用这条线(模型)来预测未见过的 x 值的 y 值。这里,m 是斜率,c 是线的截距。这两个参数(m 和 c)是通过最小化 RMSE(均方根误差)将直线拟合到数据来估计的。因此,这些参数被称为模型参数。
不同型号的型号参数:
- 线性回归中的 m(slope) 和 c(intercept)
- 神经网络中的权重和偏差
什么是模型超参数?
模型超参数是在模型开始训练之前设置其值的参数。它们不能通过将模型拟合到数据来学习。
例子: 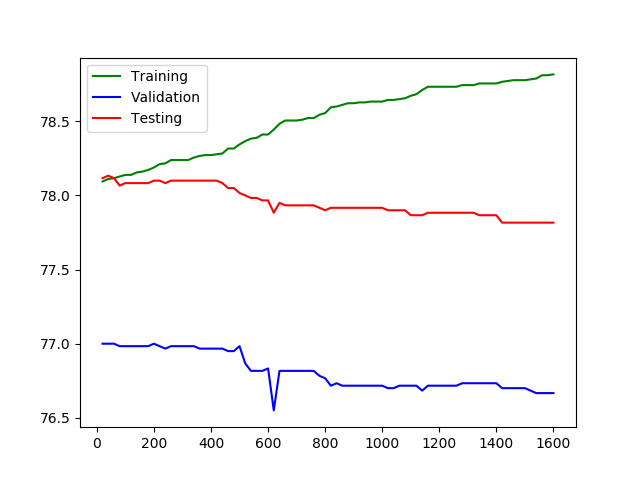
在上图中,x 轴代表 epoch 数,y 轴代表 epoch 数。我们可以看到在特定点之后,当 epochs 超过那个时候,虽然特征准确度增加,但验证和测试准确度开始下降。这是一个过度捕捞的案例。这里的时期数是一个超参数,是手动设置的。将此数字设置为较小的值可能会导致欠拟合,而较高的值可能会导致过拟合。
不同模型中的模型超参数:
- 梯度下降的学习率
- 梯度下降的迭代次数
- 神经网络中的层数
- 神经网络中每层的神经元数量
- k中的簇数(k)表示聚类
模型参数与超参数的区别表
| PARAMETERS | HYPERPARAMETER |
|---|---|
| They are required for making predictions | They are required for estimating the model parameters |
| They are estimated by optimization algorithms(Gradient Descent, Adam, Adagrad) | They are estimated by hyperparameter tuning |
| They are not set manually | They are set manually |
| The final parameters found after training will decide how the model will perform on unseen data | The choice of hyperparameters decide how efficient the training is. In gradient descent the learning rate decide how efficient and accurate the optimization process is in estimating the parameters |