Python中进程的同步和池化
先决条件 - Python中的多处理 |第 1 组 , 第 2 组
本文讨论了与Python中的多处理相关的两个重要概念:
- 进程之间的同步
- 进程池化
进程之间的同步
进程同步被定义为一种机制,它确保两个或多个并发进程不会同时执行某些称为临界区的特定程序段。
Critical section refers to the parts of the program where the shared resource is accessed.
例如,在下图中,3 个进程尝试同时访问共享资源或临界区。 
对共享资源的并发访问会导致竞争条件。
A race condition occurs when two or more processes can access shared data and they try to change it at the same time. As a result, the values of variables may be unpredictable and vary depending on the timings of context switches of the processes.
考虑下面的程序来理解竞争条件的概念:
# Python program to illustrate
# the concept of race condition
# in multiprocessing
import multiprocessing
# function to withdraw from account
def withdraw(balance):
for _ in range(10000):
balance.value = balance.value - 1
# function to deposit to account
def deposit(balance):
for _ in range(10000):
balance.value = balance.value + 1
def perform_transactions():
# initial balance (in shared memory)
balance = multiprocessing.Value('i', 100)
# creating new processes
p1 = multiprocessing.Process(target=withdraw, args=(balance,))
p2 = multiprocessing.Process(target=deposit, args=(balance,))
# starting processes
p1.start()
p2.start()
# wait until processes are finished
p1.join()
p2.join()
# print final balance
print("Final balance = {}".format(balance.value))
if __name__ == "__main__":
for _ in range(10):
# perform same transaction process 10 times
perform_transactions()
如果你运行上面的程序,你会得到一些意想不到的值,如下所示:
Final balance = 1311
Final balance = 199
Final balance = 558
Final balance = -2265
Final balance = 1371
Final balance = 1158
Final balance = -577
Final balance = -1300
Final balance = -341
Final balance = 157
在上面的程序中,进行了 10000 笔提款和 10000 笔存款交易,初始余额为 100。预期的最终余额为 100,但我们在perform_transactions函数的 10 次迭代中得到一些不同的值。
这是由于进程对共享数据余额的并发访问而发生的。余额值的这种不可预测性只不过是竞争条件。
让我们尝试使用下面给出的序列图更好地理解它。这些是可以在上述示例中为单个取款和存款操作生成的不同序列。
- 这是一个可能的序列,它给出了错误的答案,因为两个进程读取相同的值并相应地写回它。
p1 p2 balance read(balance)
current=100100 read(balance)
current=100100 balance=current-1=99
write(balance)99 balance=current+1=101
write(balance)101 - 这是上述场景中需要的 2 个可能的序列。
p1 p2 balance read(balance)
current=100100 balance=current-1=99
write(balance)99 read(balance)
current=9999 balance=current+1=100
write(balance)100 p1 p2 balance read(balance)
current=100100 balance=current+1=101
write(balance)101 read(balance)
current=101101 balance=current-1=100
write(balance)100
使用锁
multiprocessing模块提供了一个Lock类来处理竞争条件。锁定是使用操作系统提供的信号量对象实现的。
A semaphore is a synchronization object that controls access by multiple processes to a common resource in a parallel programming environment. It is simply a value in a designated place in operating system (or kernel) storage that each process can check and then change. Depending on the value that is found, the process can use the resource or will find that it is already in use and must wait for some period before trying again. Semaphores can be binary (0 or 1) or can have additional values. Typically, a process using semaphores checks the value and then, if it using the resource, changes the value to reflect this so that subsequent semaphore users will know to wait.
考虑下面给出的示例:
# Python program to illustrate
# the concept of locks
# in multiprocessing
import multiprocessing
# function to withdraw from account
def withdraw(balance, lock):
for _ in range(10000):
lock.acquire()
balance.value = balance.value - 1
lock.release()
# function to deposit to account
def deposit(balance, lock):
for _ in range(10000):
lock.acquire()
balance.value = balance.value + 1
lock.release()
def perform_transactions():
# initial balance (in shared memory)
balance = multiprocessing.Value('i', 100)
# creating a lock object
lock = multiprocessing.Lock()
# creating new processes
p1 = multiprocessing.Process(target=withdraw, args=(balance,lock))
p2 = multiprocessing.Process(target=deposit, args=(balance,lock))
# starting processes
p1.start()
p2.start()
# wait until processes are finished
p1.join()
p2.join()
# print final balance
print("Final balance = {}".format(balance.value))
if __name__ == "__main__":
for _ in range(10):
# perform same transaction process 10 times
perform_transactions()
输出:
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
Final balance = 100
让我们试着一步一步理解上面的代码:
- 首先,使用以下命令创建一个Lock对象:
lock = multiprocessing.Lock() - 然后,锁定作为目标函数参数传递:
p1 = multiprocessing.Process(target=withdraw, args=(balance,lock)) p2 = multiprocessing.Process(target=deposit, args=(balance,lock)) - 在目标函数的关键部分,我们使用lock.acquire()方法应用锁。一旦获得锁,在使用lock.release()方法释放锁之前,没有其他进程可以访问其临界区。
lock.acquire() balance.value = balance.value - 1 lock.release()正如您在结果中看到的,每次的最终余额都是 100(这是预期的最终结果)。
进程之间的池化
让我们考虑一个在给定列表中查找数字平方的简单程序。
# Python program to find
# squares of numbers in a given list
def square(n):
return (n*n)
if __name__ == "__main__":
# input list
mylist = [1,2,3,4,5]
# empty list to store result
result = []
for num in mylist:
result.append(square(num))
print(result)
输出:
[1, 4, 9, 16, 25]
这是一个计算给定列表元素平方的简单程序。在多核/多处理器系统中,请考虑下图以了解上述程序将如何工作:
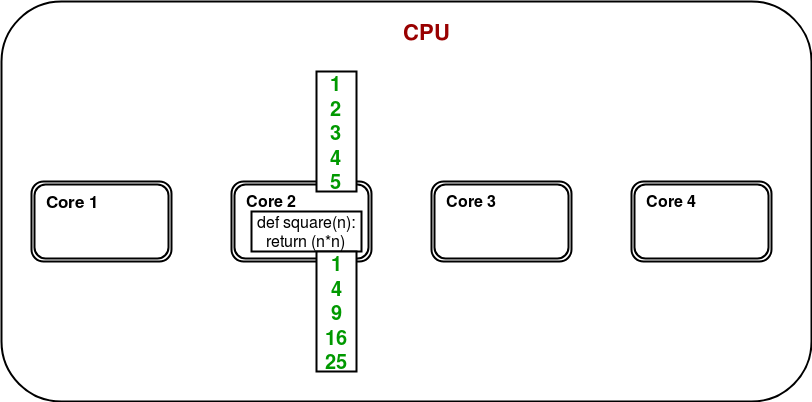
只有一个内核用于程序执行,其他内核很可能保持空闲状态。
为了利用所有内核,多处理模块提供了一个Pool类。 Pool类表示一个工作进程池。它具有允许以几种不同方式将任务卸载到工作进程的方法。考虑下图:
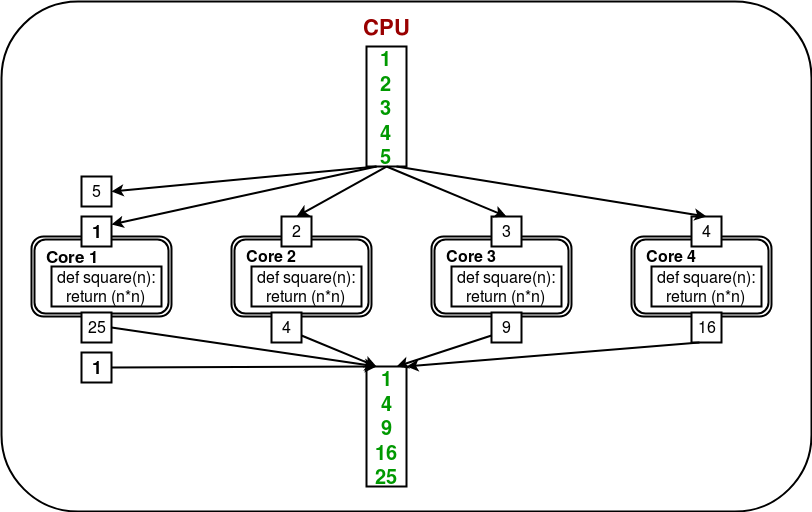
在这里,任务由Pool对象自动卸载/分配到内核/进程之间。用户无需担心显式创建流程。
考虑下面给出的程序:
# Python program to understand
# the concept of pool
import multiprocessing
import os
def square(n):
print("Worker process id for {0}: {1}".format(n, os.getpid()))
return (n*n)
if __name__ == "__main__":
# input list
mylist = [1,2,3,4,5]
# creating a pool object
p = multiprocessing.Pool()
# map list to target function
result = p.map(square, mylist)
print(result)
输出:
Worker process id for 2: 4152
Worker process id for 1: 4151
Worker process id for 4: 4151
Worker process id for 3: 4153
Worker process id for 5: 4152
[1, 4, 9, 16, 25]
让我们试着一步一步理解上面的代码:
- 我们使用以下方法创建一个Pool对象:
p = multiprocessing.Pool()有一些论据可以获得对任务卸载的更多控制。这些都是:
- processes:指定工作进程的数量。
- maxtasksperchild:指定每个孩子分配的最大任务数。
可以使用这些参数使池中的所有进程执行一些初始化:
- initializer:为工作进程指定一个初始化函数。
- initargs:要传递给初始化程序的参数。
- 现在,为了执行某些任务,我们必须将其映射到某个函数。在上面的示例中,我们将mylist映射到square 函数。这样一来, mylist的内容和square的定义就会分布在各个核心之间。
result = p.map(square, mylist) - 一旦所有工作进程完成他们的任务,就会返回一个包含最终结果的列表。