进程:进程是一个正在执行的程序,称为程序。
但是将程序转换为过程涉及到本文中明确定义的各个阶段。此外,在程序转换为进程内存后,必须将内存分配给主内存中的这些进程,这些内存分配由操作系统使用本文末尾解释的各种方法和算法进行处理。
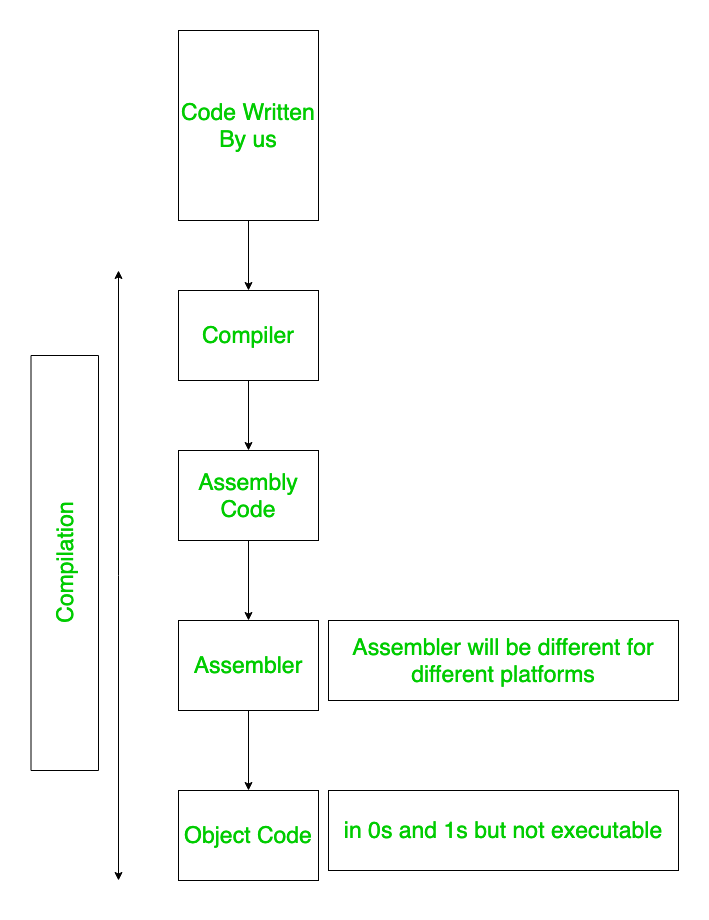
最初,当我们在文本编辑器中编写代码时(无论是任何语言)都存储在主内存中。当我们调用编译器时,它会将这些代码转换为汇编代码,即将高级代码转换为低级代码。然后汇编器将这个编译后生成的汇编代码转换成目标代码。这个目标代码是0和1的,但是这个代码不能直接执行。
为了执行代码,按顺序采用以下解释的步骤。高级代码到低级代码的转换过程由编译器完成,这些步骤在编译器设计课程中明确定义,其余所有步骤由操作系统处理。不同平台的汇编程序不同。
在现代,编译器为我们完成了下面列出的所有工作。因此我们不会面临单独编译的麻烦,然后链接和加载到主内存。
在代码编译过程中,它遵循以下定义的步骤:
上述所有步骤后产生的目标代码有以下部分:
1. Header
2. Text/Code Segment
3. Data Segment
4. Relocation Information
5. Symbol Table
6. Debugging Information 这些解释如下。
- 标题:
它说明目标代码中可用的部分是什么,以及各个部分在主存储器中的位置是什么。就像它保留了一个指向所有部分位置的指针。 - 文本/代码段:
它是包含实际编写代码的目标代码部分。 - 数据段:
它是包含数据成员的目标代码的一部分。 - 搬迁信息:
有两种地址 –- 一世。可搬迁地址 –
该地址相对于 0,因为在编译时不知道要加载程序的实际位置。 - ii.绝对地址 –
当程序最终加载到主内存中时,可重定位地址被转换为绝对地址,因为该点将知道程序加载的确切位置。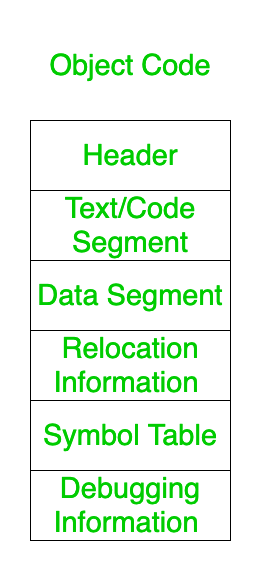
- 一世。可搬迁地址 –
- 符号表:
包含所有符号,即所有使用的变量和所有使用的函数。它还跟踪我们定义的函数或默认函数的地址。符号表包含我们定义的函数的地址,但它可能缺少默认函数的地址,因为在我们的程序中,我们不会一次又一次地定义默认函数。因此,默认函数的地址将在符号表中保持未解析状态。
现在这个未解析的地址将由链接器在后面的步骤中解析。
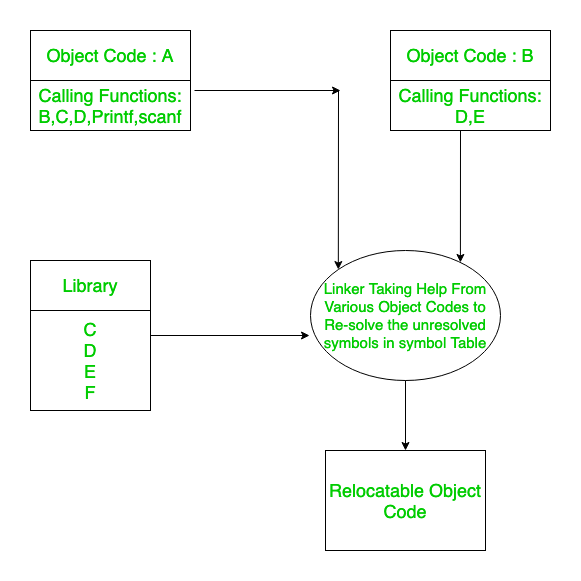
这些程序的设计方式是,从来没有一个单一的目标代码是自给自足的,而是采用各种目标代码来计算以转换为正确的可执行代码。因此,每个目标代码都需要其他几个目标代码的帮助。
现在是链接器通过从定义特定函数的各种其他目标代码中获取帮助来重新解析符号表中的所有未解析地址。查找源以解析地址的链接器最初会查看相同的程序的目录,然后如果找不到将转到编译器指定的目录。
链接器分 2 个阶段工作:
一、第一阶段:
在这里它可以找到存在的段以及要加载的段。它使用 2 个表:段表和符号表。
- 1. 段表 –用于查找要加载的段。
- 2. 符号表——用于查找符号表中未解析的符号和待解析的符号。
二、第二阶段:
在这个阶段,链接器实际上解析了符号表中所有未解析的符号。
笔记:
如上所述,仍然有一些符号被故意留下未解析,因为这些符号通常被程序使用,因此它直接保存在主内存中。因此,当我们需要解析时,我们直接询问存在于主内存中的地址,而不是重复保持相同的代码。这部分代码称为Stub Code 。
因此,链接器将所有目标代码组合在一起以生成单个目标代码,其中所有地址都将被解析(除了一些常用的地址)。因此,链接器执行的主要功能是:-
1. Relocation
2. Symbol Resolution 因此链接器输出一个可重定位代码。
现在装载机将进入画面。加载器的函数是将程序放入主内存。加载器知道程序要加载到哪里。现在,当进程加载到主内存上时,内存分配可以是:-
1. 连续内存分配:
i. Static allocation
ii. Dynamic allocation 2. 非连续内存分配:
i. Paging
ii. Segmentation
iii. Segmented Paging