先决条件 – 散列数据结构
在数据库管理系统中,当我们想要检索特定数据时,搜索所有索引值并到达所需数据变得非常低效。在这种情况下,哈希技术应运而生。
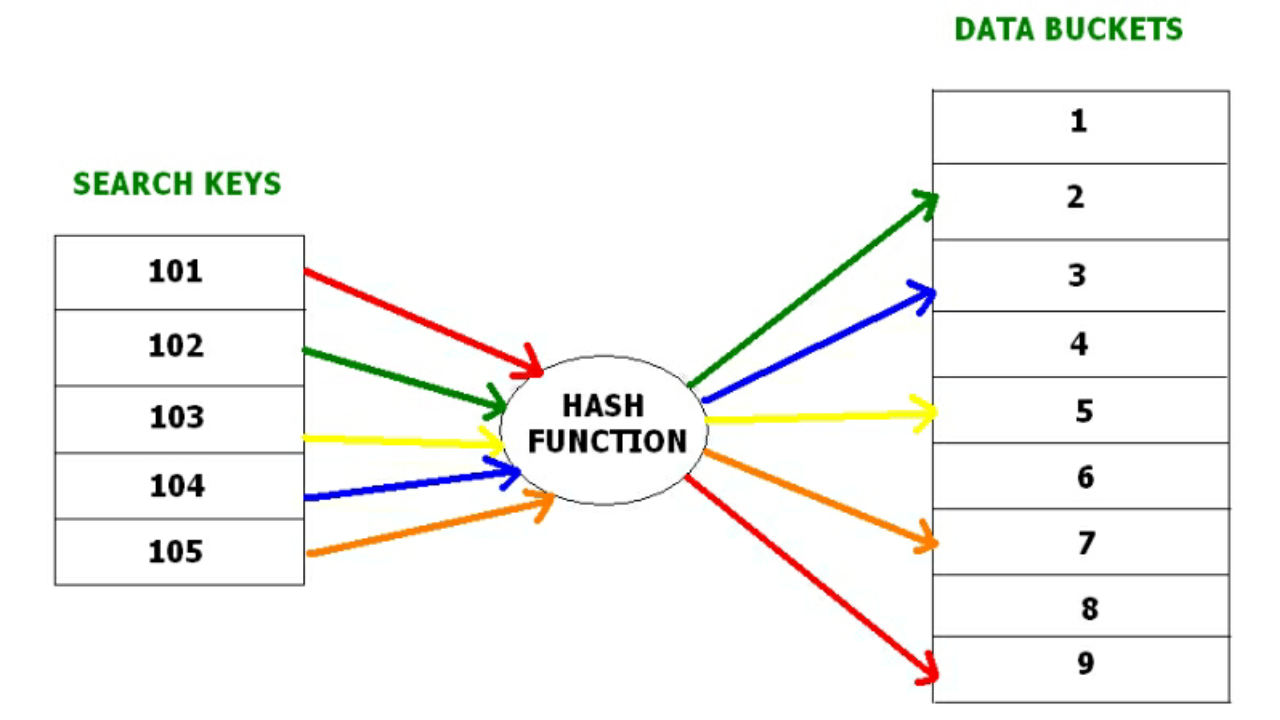
散列是一种无需使用索引结构直接搜索所需数据在磁盘上的位置的有效技术。数据存储在地址由散列函数生成的数据块中。存储这些记录的内存位置称为数据块或数据桶。
哈希文件组织:
- 数据桶——数据桶是存储记录的内存位置。这些存储桶也被视为存储单元。
- 哈希函数–哈希函数是一种映射函数,它将所有搜索键集映射到实际记录地址。通常,哈希函数使用主键生成哈希索引——数据块的地址。哈希函数可以是简单的数学函数,也可以是任何复杂的数学函数。
- 整个散列值的散列索引-前缀被作为散列索引。每个散列索引都有一个深度值来表示有多少位用于计算散列函数。这些位可以寻址 2n 个桶。什么时候消耗所有这些位?然后深度值线性增加并分配两倍的桶。
下面给出的图表清楚地描述了哈希函数的工作原理:
散列进一步分为两个子类别:
静态散列 –
在静态散列中,当提供搜索键值时,散列函数总是计算相同的地址。例如,如果我们想使用 mod (5) 哈希函数为 STUDENT_ID = 76 生成地址,它总是导致相同的桶地址 4。这里的桶地址不会有任何变化。因此,用于此静态散列的内存中数据桶的数量始终保持不变。
运营——
- 插入——当一条新记录插入到表中时,散列函数h 根据其散列键 K 为新记录生成一个桶地址。
桶地址 = h(K) - Searching –当需要搜索记录时,使用相同的哈希函数来检索记录的桶地址。例如,如果我们要检索 ID 76 的整个记录,并且如果该 ID 的哈希函数是 mod(5),则生成的桶地址将为 4。然后我们将直接到地址 4 并检索整个记录ID 104。这里 ID 充当散列键。
- 删除 –如果我们想删除一条记录,我们将首先使用哈希函数获取应该删除的记录。然后我们将删除内存中该地址的记录。
- 更新用-数据记录需要首先使用散列函数找遍进行更新,然后将数据记录被更新。
现在,如果我们想在文件中插入一些新的记录但是哈希函数生成的数据桶地址不为空或者该地址中已经存在数据。这成为需要处理的危急情况。静态散列中的这种情况称为桶溢出。
在这种情况下我们将如何插入数据?
提供了多种方法来克服这种情况。下面讨论一些常用的方法:
- 开放散列 –
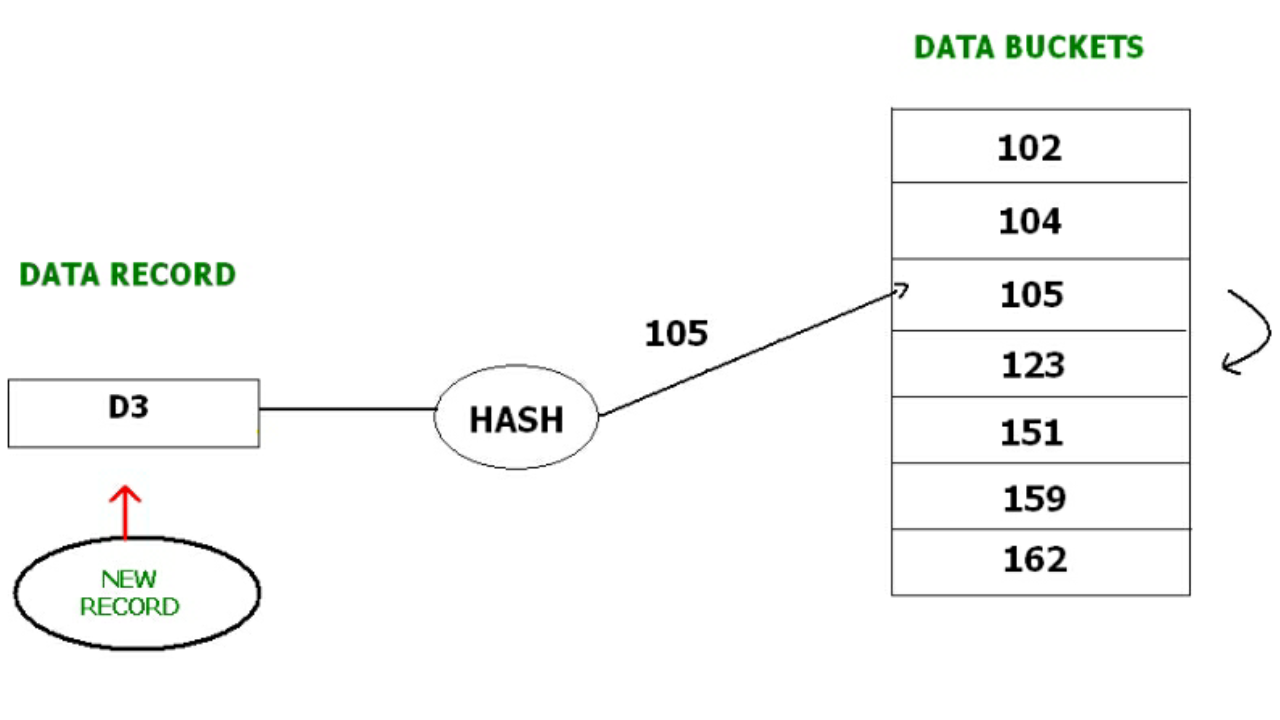
在开放散列方法中,下一个可用数据块用于输入新记录,而不是覆盖旧记录。这种方法也称为线性探测。例如,D3 是一个需要插入的新记录,哈希函数生成地址为 105。但它已经满了。因此,系统搜索下一个可用数据桶 123 并将 D3 分配给它。
- 封闭散列 –
在封闭散列方法中,一个新的数据桶被分配了相同的地址,并在完整的数据桶之后链接它。这种方法也称为溢出链接。
例如,我们必须在表中插入一条新记录 D3。静态散列函数生成的数据桶地址为105。但这个桶已满,无法存储新数据。在这种情况下,在 105 个数据桶的末尾添加了一个新的数据桶并链接到它。然后将新记录 D3 插入到新存储桶中。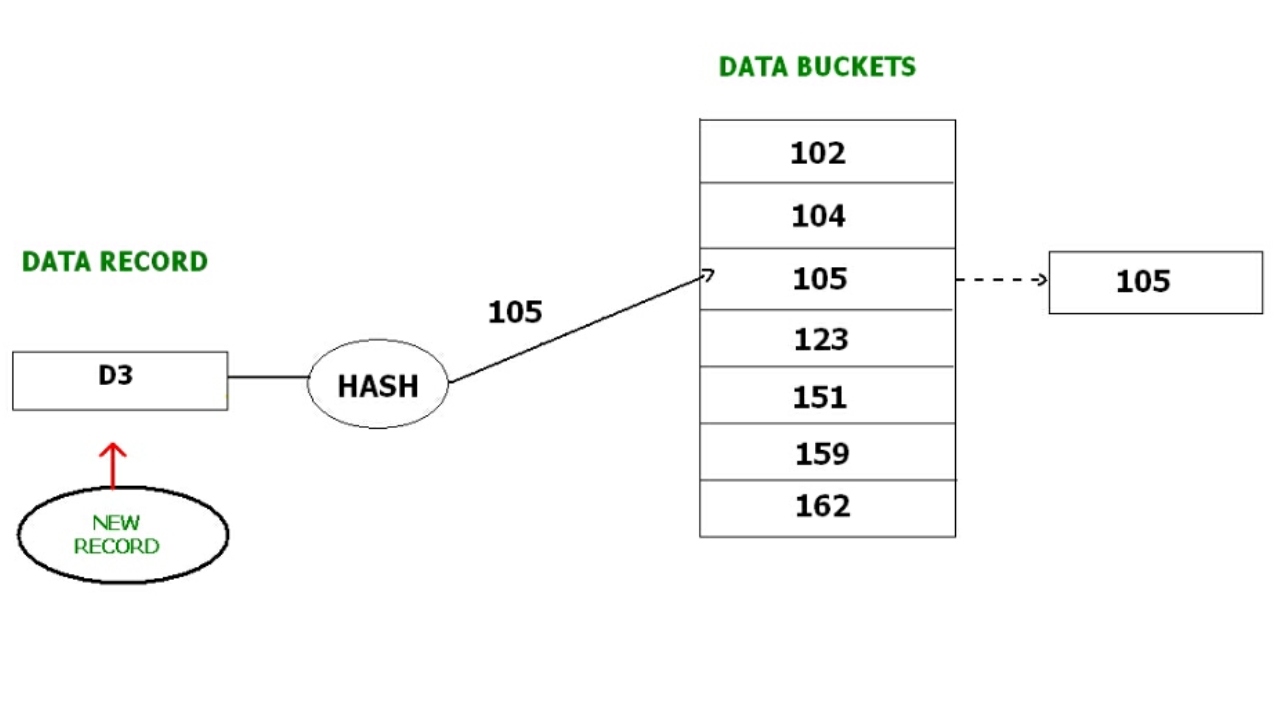
- 二次探测:
二次探测与开放散列或线性探测非常相似。在这里,新旧桶之间的唯一区别是线性的。二次函数用于确定新的桶地址。 - 双哈希:
双哈希是另一种类似于线性探测的方法。这里的差异与线性探测一样是固定的,但是这个固定的差异是通过使用另一个散列函数来计算的。这就是名称是双重散列的原因。
- 二次探测:
动态散列 –
静态散列的缺点是它不会随着数据库大小的增长或缩小而动态扩展或缩小。在动态散列中,数据桶随着记录的增加或减少而增长或缩小(动态添加或删除)。动态散列也称为扩展散列。
在动态散列中,散列函数被用来产生大量的值。例如,存在三个数据记录 D1、D2 和 D3。哈希函数生成三个地址 1001、0101 和 1010。这种存储方法仅考虑该地址的一部分——尤其是仅存储数据的前一位。所以它尝试在地址 0 和 1 加载其中三个。
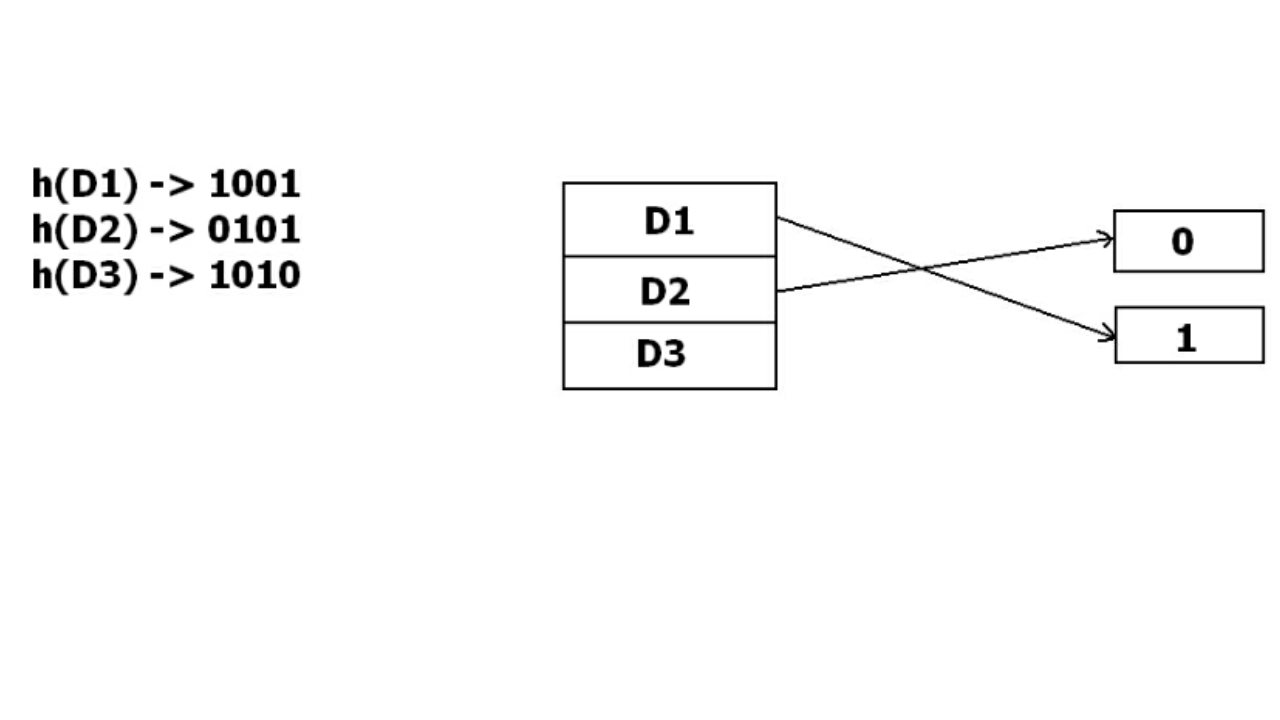
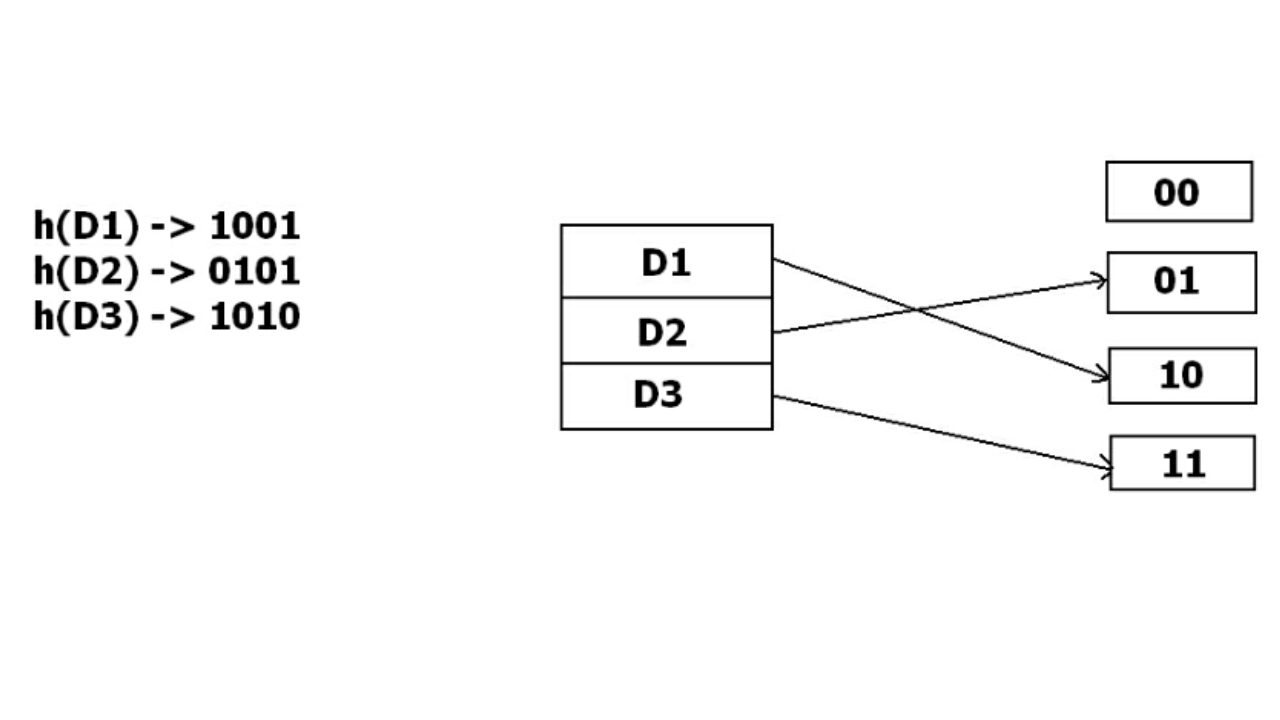
但问题是 D3 没有剩余的桶地址。存储桶必须动态增长以适应 D3。因此它将地址更改为 2 位而不是 1 位,然后将现有数据更新为 2 位地址。然后它尝试容纳 D3。
参考 –
cse.iitb.ac.in