先决条件 – 时间戳排序协议
各种并发控制方案使用不同的方法和每个单独的数据项作为执行同步的单位。这种技术的一个缺点是如果一个事务T i需要访问整个数据库,并且使用了锁定协议,那么T i必须锁定数据库中的每一项。这是低效率的,它会更简单,如果T I可以使用单个锁锁定整个数据库。但是,如果考虑第二个建议,实际上不应忽视所提出方法的某些缺陷。假设另一个事务只需要访问数据库中的几个数据项,那么锁定整个数据库似乎是不必要的,而且可能会导致我们失去并发性,这是我们最初的主要目标。在效率和并发之间讨价还价。使用粒度。
让我们首先了解什么是粒度。
粒度 –它是允许锁定的数据项的大小。现在多粒度意味着将数据库分层分解为可以锁定和可以跟踪的块,需要锁定的内容和方式。这样的层次结构可以用图形表示为树。
例如,考虑由四层节点组成的树。最高级别代表整个数据库。下面是类型area 的节点;数据库正是由这些区域组成。该区域具有称为文件的子节点。每个区域都有作为其子节点的文件。没有文件可以跨越多个区域。
最后,每个文件都有称为记录的子节点。和以前一样,该文件完全由作为其子节点的那些记录组成,并且任何记录都不能存在于多个文件中。因此,从顶层开始的级别是:
- 数据库
- 区域
- 文件
- 记录
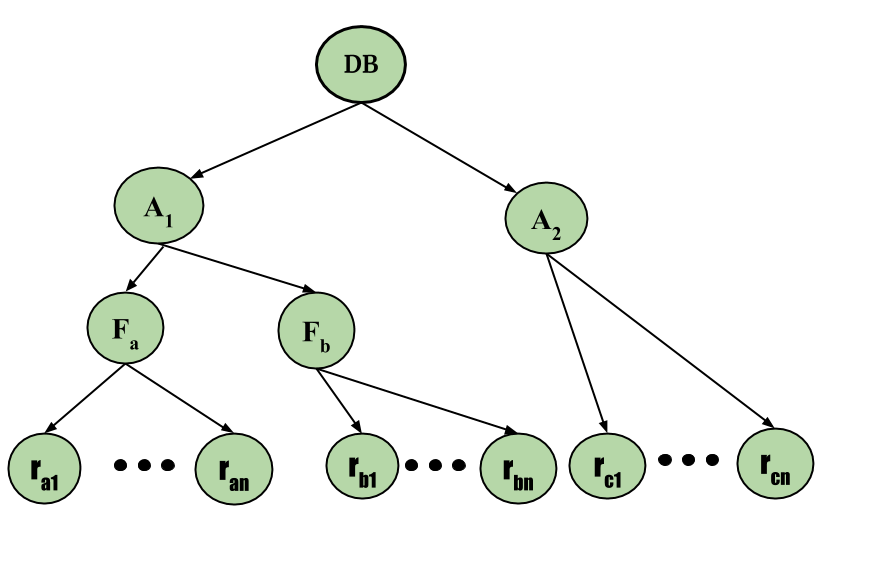
图 –多粒度树层次结构
考虑上面给出的示例图,树中的每个节点都可以单独锁定。与两阶段锁定协议一样,它应使用共享和独占锁定模式。当一个事务以共享或独占模式锁定一个节点时,该事务也会以相同的锁定模式隐式锁定该节点的所有后代。例如,如果事务 T i以独占模式获得文件 F c的显式锁定,那么它在属于该文件的所有记录上具有独占模式的隐式锁定。它不需要明确锁定 F c的各个记录。这是多粒度的基于树的锁定和分层锁定之间的主要区别。
现在,文件和记录的锁定变得简单了,系统如何确定是否可以锁定根节点?一种可能性是它搜索整个树,但该解决方案使多粒度锁定方案的全部目的无效。获得这些知识的更有效方法是引入一种新的锁定模式,称为意图锁定模式。
意向模式锁定 –
除了S和X锁模式,还有三种额外的多粒度的锁模式:
- 意图共享(IS):在树的较低级别显式锁定,但仅使用共享锁。
- Intention-Exclusive (IX):在较低级别的显式锁定,具有排他或共享锁。
- Shared & Intention-Exclusive (SIX):以该节点为根的子树在共享模式下被显式锁定,并且显式锁定正在使用排他模式锁在较低级别完成。
这些锁定模式的兼容性矩阵如下所述:
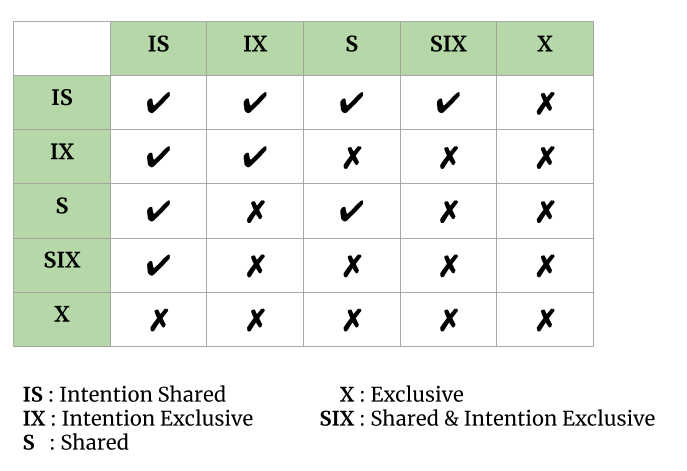
图 –多粒度树层次结构
多粒度锁定协议使用意图锁定模式来确保可串行化。它要求尝试锁定节点的事务 T i必须遵循以下协议:
- 事务 T i必须遵循锁兼容性矩阵。
- 事务T i必须先锁定树的根,它可以在任何模式下锁定。
- 事务T我可以锁定S中的节点或IS模式仅当T I当前具有节点锁定在任一IX或IS模式的父代。
- 仅当 T i当前在 IX 或 SIX 模式下锁定节点的父节点时,事务 T i才能以 X、SIX 或 IX 模式锁定节点。
- 仅当 T i之前没有解锁任何节点(即,T i是两阶段的)时,事务 T i 才能锁定节点。
- 仅当 T i当前没有节点锁定的子节点时,事务 T i 才能解锁节点。
请注意,多粒度协议要求以自上而下(从根到叶)的顺序获取锁,而必须以自下而上(从叶到根)的顺序释放锁。
作为协议的说明,考虑上面给出的树和交易:
- 说事务T 1文件F一读取记录R A2。然后,T 2需要在IS模式下(并按此顺序)锁定数据库、区域A 1和F a ,最后在S模式下锁定R a2 。
- 假设事务 T 2修改了文件 F a 中的记录 R a9 。然后,T 2需要在IX模式下锁定数据库、区域A 1和文件F a (并按此顺序),最后在X模式下锁定R a9 。
- 假设事务 T 3读取文件 F a 中的所有记录。然后,T 3需要在IS模式下锁定数据库和区域A 1 (并按此顺序),最后在S模式下锁定F a 。
- 假设事务 T 4读取整个数据库。它可以在 S 模式下锁定数据库后执行此操作。
请注意,事务 T 1 、T 3和 T 4可以同时访问数据库。事务 T 2可以与 T 1并发执行,但不能与 T 3或 T 4并发执行。
该协议增强了并发性并减少了锁开销。在多粒度协议中仍然可能出现死锁,就像在两阶段锁定协议中一样。这些可以通过使用某些死锁消除技术来消除。