多类分类是监督机器学习中的一个流行问题。
问题——给定一个包含m 个训练示例的数据集,每个示例都包含各种特征和标签形式的信息。每个标签对应一个类,训练样本所属的类。在多类分类中,我们有一个有限的类集。每个训练示例也有n 个特征。
例如,在识别不同类型水果的情况下,“形状”、“颜色”、“半径”可以是特征,而“苹果”、“橙子”、“香蕉”可以是不同的类别标签。
在多类分类中,我们使用我们的训练数据训练分类器,并使用该分类器对新示例进行分类。
本文的目的 –我们将使用不同的多类分类方法,例如 KNN、决策树、SVM 等。我们将比较它们在测试数据上的准确性。我们将使用 sci-kit learn (Python) 执行所有这些操作。有关如何安装和使用 sci-kit learn 的信息,请访问 http://scikit-learn.org/stable/
方法 –
- 从源加载数据集。
- 将数据集拆分为“训练”和“测试”数据。
- 在训练数据上训练决策树、SVM 和 KNN 分类器。
- 使用上述分类器来预测测试数据的标签。
- 测量准确性并可视化分类。
决策树分类器——决策树分类器是一种多类分类的系统方法。它向数据集提出了一组问题(与其属性/特征相关)。决策树分类算法可以在二叉树上可视化。在根节点和每个内部节点上,提出一个问题,然后将该节点上的数据进一步拆分为具有不同特征的单独记录。树的叶子是指数据集被拆分的类。在以下代码片段中,我们在 scikit-learn 中训练决策树分类器。
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a DescisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
dtree_model = DecisionTreeClassifier(max_depth = 2).fit(X_train, y_train)
dtree_predictions = dtree_model.predict(X_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, dtree_predictions)
SVM(支持向量机)分类器 –
当特征向量为高维时,SVM(支持向量机)是一种有效的分类方法。在 sci-kit learn 中,我们可以指定核函数(这里是线性的)。要了解有关内核函数和 SVM 的更多信息,请参阅 – 内核函数| sci-kit 学习和 SVM。
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a linear SVM classifier
from sklearn.svm import SVC
svm_model_linear = SVC(kernel = 'linear', C = 1).fit(X_train, y_train)
svm_predictions = svm_model_linear.predict(X_test)
# model accuracy for X_test
accuracy = svm_model_linear.score(X_test, y_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, svm_predictions)
KNN(k-nearest neighbor)分类器 – KNN 或 k-nearest neighbor 是最简单的分类算法。这种分类算法不依赖于数据的结构。每当遇到新示例时,都会检查它与训练数据中的 k 个最近邻。两个示例之间的距离可以是它们的特征向量之间的欧几里德距离。 k 个最近邻中的多数类被认为是遇到的示例的类。
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a KNN classifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 7).fit(X_train, y_train)
# accuracy on X_test
accuracy = knn.score(X_test, y_test)
print accuracy
# creating a confusion matrix
knn_predictions = knn.predict(X_test)
cm = confusion_matrix(y_test, knn_predictions)
朴素贝叶斯分类器——朴素贝叶斯分类方法基于贝叶斯定理。它被称为“朴素”,因为它假设数据中的每对特征之间都是独立的。设(x 1 , x 2 , …, x n )为特征向量, y为对应于该特征向量的类标签。
应用贝叶斯定理,
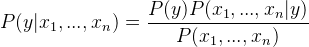
由于x 1 , x 2 , …, x n相互独立,
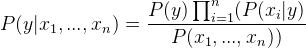
通过删除P(x 1 , …, x n ) 来插入比例性(因为它是常数)。
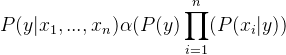
因此,类标签由以下因素决定,
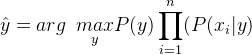
P(y)是训练数据集中类别标签y的相对频率。
在高斯朴素贝叶斯分类器的情况下, P(x i | y)计算为,
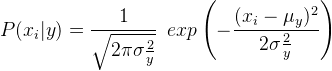
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a Naive Bayes classifier
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB().fit(X_train, y_train)
gnb_predictions = gnb.predict(X_test)
# accuracy on X_test
accuracy = gnb.score(X_test, y_test)
print accuracy
# creating a confusion matrix
cm = confusion_matrix(y_test, gnb_predictions)
参考 –
- http://scikit-learn.org/stable/modules/naive_bayes.html
- https://en.wikipedia.org/wiki/Multiclass_classification
- http://scikit-learn.org/stable/documentation.html
- http://scikit-learn.org/stable/modules/tree.html
- http://scikit-learn.org/stable/modules/svm.html#svm-kernels
- https://www.analyticsvidhya.com/blog/2015/10/understaing-support-vector-machine-example-code/