- 使用 scikit-learn 进行多类分类
- 使用 scikit-learn 进行多类分类(1)
- scikit learn - Python (1)
- 使用Scikit-learn进行癌细胞分类(1)
- 使用Scikit-learn进行癌细胞分类
- scikit learn - Python 代码示例
- ML |使用Scikit-learn进行癌细胞分类(1)
- ML |使用Scikit-learn进行癌细胞分类
- scikit learn 的版本 - Python (1)
- scikit learn 的版本 - Python 代码示例
- scikit learn 介绍 - Python (1)
- scikit-learn 教程 (1)
- 如何安装 scikit learn python 库 - Shell-Bash (1)
- scikit learn 介绍 - Python 代码示例
- 管道Python和 scikit-learn
- 管道Python和 scikit-learn(1)
- 安装 scikit learn - Shell-Bash (1)
- scikit learn 介绍 (1)
- 如何安装 scikit learn python 库 - Shell-Bash 代码示例
- 安装 scikit learn - Shell-Bash 代码示例
- 如何在 Linux 上安装 Scikit-Learn?
- 如何在 Linux 上安装 Scikit-Learn?(1)
- scikit learn k mean - Python (1)
- scikit-learn 教程 - 任何代码示例
- 如何在 Windows 中安装 Scikit-Learn?
- 如何在 Windows 中安装 Scikit-Learn?(1)
- scikit learn k mean - Python 代码示例
- 在 scikit learn 中编码标签 - Python 代码示例
- scikit learn 介绍 - 任何代码示例
📅 最后修改于: 2020-09-04 05:05:28 🧑 作者: Mango
介绍
集成分类模型可以是强大的机器学习工具,能够实现出色的性能并将其很好地推广到新的,看不见的数据集。
集成分类器的价值在于,将多个分类器的预测结合在一起,可以校正任何单个分类器所产生的错误,从而提高总体准确性。让我们看一下不同的集成分类方法,看看如何在Scikit-Learn中实现这些分类器。
机器学习中的集成模型是什么?

集成模型是将不同算法组合在一起的整体学习方法。从这个意义上讲,它是一个元算法,而不是算法本身。集成学习方法非常有价值,因为它们可以提高预测模型的性能。
集成学习方法的工作原理是,将多个分类器的预测联系在一起,可以通过提高预测准确性或减少偏差和方差等方面来提高性能。
通常,集成模型属于两类之一:顺序方法和并行方法。(需要科学上网)
甲顺序合奏模型由具有在序列中产生的碱学习者/模型工作。顺序集成方法通常用于尝试提高整体性能,因为集成模型可以通过对以前错误分类的示例重新加权来补偿不正确的预测。一个明显的例子是AdaBoost。
一个并行模型,正如你可能会猜到,依赖于创造和并行训练基地学习方法。并行方法旨在通过并行训练许多模型并将结果平均在一起来降低错误率。并行方法的一个显着示例是随机森林分类器。
思考这个的另一种方法是区别同质和异质的学习者。尽管大多数集成学习方法都使用同质基础学习器(许多相同类型的学习器),但某些集成方法却使用异类学习器(将不同的学习算法结合在一起)。
回顾一下:
- 顺序模型试图通过对示例重新加权来提高性能,并且模型是按顺序生成的。
- 并行模型通过同时训练许多模型后将结果平均在一起来工作。
现在,我们将介绍使用这些模型来解决机器学习分类问题的不同方法。
不同的合奏分类方法
打包
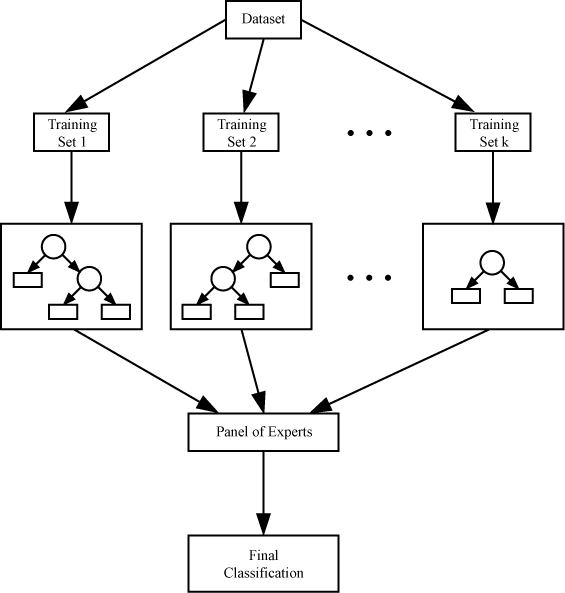
Bagging,也称为引导聚合,是一种分类方法,旨在通过将多个估计值平均在一起来减少估计值的方差。套袋从学习者的主要数据集中创建子集。
为了汇总不同分类器的预测,可以将平均值用于回归,也可以将表决方法用于分类(基于多数决策)。
Bagging分类方法的一个示例是“ 随机森林分类器”。对于随机森林分类器,所有单独的树木都在数据集的不同样本上训练。
还使用特征的随机选择来训练树。当将结果平均在一起时,总体方差减小,结果模型表现更好。
提升
Boosting算法能够采用性能较弱的弱模型并将其转换为强模型。增强算法背后的想法是,您为数据集分配了许多弱学习模型,然后在随后的学习回合中调整了错误分类示例的权重。
汇总分类器的预测,然后通过加权和(在回归的情况下)或加权多数投票(在分类的情况下)做出最终预测。
AdaBoost是增强分类器方法的一个示例,它是从上述算法派生的Gradient Boosting。
如果您想了解有关Gradient Boosting及其背后的理论的更多信息,我们已经在上一篇文章中进行了介绍。
Boosting
Boosting算法能够采用性能较弱的弱模型并将其转换为强模型。增强算法背后的想法是,您为数据集分配了许多弱学习模型,然后在随后的学习回合中调整了错误分类示例的权重。
汇总分类器的预测,然后通过加权和(在回归的情况下)或加权多数投票(在分类的情况下)做出最终预测。
AdaBoost是增强分类器方法的一个示例,它是从上述算法派生的Gradient Boosting。
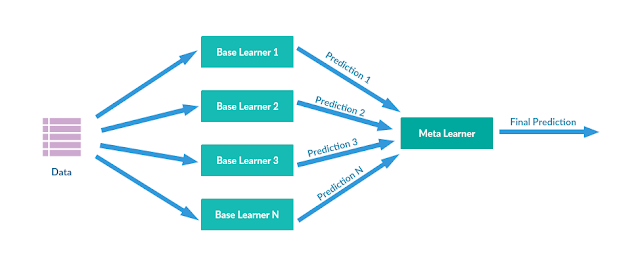
堆叠算法是一种综合学习方法,结合了不同回归算法或分类算法的决策。在整个训练数据集上训练组件模型。在训练了这些组件模型之后,从不同的模型组装一个元模型,然后在组件模型的输出上对其进行训练。由于组件模型通常是不同的算法,因此该方法通常会创建异构集合。
示例实现
现在,我们探索了可用于创建集成模型的不同方法,下面让我们看一下如何使用不同的方法实现分类器。
不过,在我们研究实现集合分类器的不同方法之前,我们需要选择要使用的数据集并对数据集进行一些预处理。
我们将使用Titanic数据集,可在此处下载。让我们对数据进行一些预处理,以消除缺失值并将数据缩放到统一范围。然后,我们可以开始设置集成分类器。
数据预处理
首先,我们将从它们各自的库中导入所需的所有函数开始。我们将使用Pandas和Numpy来加载和转换数据以及LabelEncoder和StandardScaler工具。
我们还需要机器学习指标和train_test_split功能。最后,我们需要要使用的分类器:
import pandas as pd
import numpy as np
import warnings
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import accuracy_score, f1_score, log_loss
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier, ExtraTreesClassifier我们将从加载训练和测试数据开始,然后创建一个函数来检查是否存在任何空值:
training_data = pd.read_csv("train.csv")
testing_data = pd.read_csv("test.csv")
def get_nulls(training, testing):
print("Training Data:")
print(pd.isnull(training).sum())
print("Testing Data:")
print(pd.isnull(testing).sum())
get_nulls(training_data, testing_data) 碰巧的是,Age和Cabin类别中有很多缺失值。
Training Data:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Testing Data:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
我们将从删除一些可能无用的Cabin列开始-该列和该Ticket列。该Cabin列缺少太多值,并且该Ticket列仅包含太多有用的类别。
之后,我们需要估算一些缺失的值。这样做时,我们必须说明数据集如何稍微偏斜(年轻人比年龄稍大一些)。插补数据时,将使用中位数,因为由于离群值较大,取平均值会使我们得出的插补值远离数据集的中心:
# Drop the cabin column, as there are too many missing values
# Drop the ticket numbers too, as there are too many categories
# Drop names as they won't really help predict survivors
training_data.drop(labels=['Cabin', 'Ticket', 'Name'], axis=1, inplace=True)
testing_data.drop(labels=['Cabin', 'Ticket', 'Name'], axis=1, inplace=True)
# Taking the mean/average value would be impacted by the skew
# so we should use the median value to impute missing values
training_data["Age"].fillna(training_data["Age"].median(), inplace=True)
testing_data["Age"].fillna(testing_data["Age"].median(), inplace=True)
training_data["Embarked"].fillna("S", inplace=True)
testing_data["Fare"].fillna(testing_data["Fare"].median(), inplace=True)
get_nulls(training_data, testing_data)现在我们可以看到不再缺少任何值:
Training Data:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
Testing Data:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
现在,我们需要对非数字数据进行编码。让我们设置a LabelEncoder并将其拟合到Sex特征上,然后使用编码器转换数据。然后,我们将Sex特征中的值替换为已编码的值,然后对Embarked特征进行相同的操作。
最后,让我们使用来缩放数据StandardScaler,这样值就不会有太大的波动。
encoder_1 = LabelEncoder()
# Fit the encoder on the data
encoder_1.fit(training_data["Sex"])
# Transform and replace training data
training_sex_encoded = encoder_1.transform(training_data["Sex"])
training_data["Sex"] = training_sex_encoded
test_sex_encoded = encoder_1.transform(testing_data["Sex"])
testing_data["Sex"] = test_sex_encoded
encoder_2 = LabelEncoder()
encoder_2.fit(training_data["Embarked"])
training_embarked_encoded = encoder_2.transform(training_data["Embarked"])
training_data["Embarked"] = training_embarked_encoded
testing_embarked_encoded = encoder_2.transform(testing_data["Embarked"])
testing_data["Embarked"] = testing_embarked_encoded
# Any value we want to reshape needs be turned into array first
ages_train = np.array(training_data["Age"]).reshape(-1, 1)
fares_train = np.array(training_data["Fare"]).reshape(-1, 1)
ages_test = np.array(testing_data["Age"]).reshape(-1, 1)
fares_test = np.array(testing_data["Fare"]).reshape(-1, 1)
# Scaler takes arrays
scaler = StandardScaler()
training_data["Age"] = scaler.fit_transform(ages_train)
training_data["Fare"] = scaler.fit_transform(fares_train)
testing_data["Age"] = scaler.fit_transform(ages_test)
testing_data["Fare"] = scaler.fit_transform(fares_test)现在我们的数据已经过预处理,我们可以选择功能和标签,然后使用该train_test_split功能将整个培训数据划分为培训和测试集:
# Now to select our training/testing data
X_features = training_data.drop(labels=['PassengerId', 'Survived'], axis=1)
y_labels = training_data['Survived']
print(X_features.head(5))
# Make the train/test data from validation
X_train, X_val, y_train, y_val = train_test_split(X_features, y_labels, test_size=0.1, random_state=27)现在,我们准备开始实施集成分类方法。
简单平均法
在介绍之前介绍的三大集成方法之前,让我们介绍一种使用集成方法的平均方法,该方法非常快捷简便。我们只需将所选分类器的不同预测值加在一起,然后除以分类器总数即可,使用下限除法得到一个完整的值。
在这个测试案例中,我们将使用逻辑回归,决策树分类器和支持向量分类器。我们将分类器拟合到数据上,然后将预测保存为变量。然后,我们将预测简单地相加并除以:
LogReg_clf = LogisticRegression()
DTree_clf = DecisionTreeClassifier()
SVC_clf = SVC()
LogReg_clf.fit(X_train, y_train)
DTree_clf.fit(X_train, y_train)
SVC_clf.fit(X_train, y_train)
LogReg_pred = LogReg_clf.predict(X_val)
DTree_pred = DTree_clf.predict(X_val)
SVC_pred = SVC_clf.predict(X_val)
averaged_preds = (LogReg_pred + DTree_pred + SVC_pred)//3
acc = accuracy_score(y_val, averaged_preds)
print(acc)
这是通过此方法获得的准确性:
0.8444444444444444投票\堆叠分类示例
在创建堆叠/投票分类器时,Scikit-Learn为我们提供了一些方便的功能,可以用来完成此任务。
该VotingClassifier发生在不同的估计作为参数和投票方法的列表。该hard投票方式使用预测的标签和多数规则体系,而soft投票的方法预测基于预测概率的总和的argmax /最大预测值的标签。
提供所需的分类器后,我们需要对结果分类器对象进行拟合。然后,我们可以获得预测并使用准确性指标:
voting_clf = VotingClassifier(estimators=[('SVC', SVC_clf), ('DTree', DTree_clf), ('LogReg', LogReg_clf)], voting='hard')
voting_clf.fit(X_train, y_train)
preds = voting_clf.predict(X_val)
acc = accuracy_score(y_val, preds)
l_loss = log_loss(y_val, preds)
f1 = f1_score(y_val, preds)
print("Accuracy is: " + str(acc))
print("Log Loss is: " + str(l_loss))
print("F1 Score is: " + str(f1))以下是有关效果的指标VotingClassifier:
Accuracy is: 0.8888888888888888
Log Loss is: 3.8376684749044165
F1 Score is: 0.8484848484848486bagging分类实例
这是我们如何使用Scikit-Learn实施装袋分类的方法。Sklearn的BaggingClassifier接受选定的分类模型以及您要使用的估计量的数量-您可以使用Logistic回归或决策树之类的模型。
Sklearn还提供对RandomForestClassifier和的访问ExtraTreesClassifier,这是对决策树分类的修改。这些分类器也可以与K折交叉验证工具一起使用。
在这里,我们将比较几种不同的装袋分类方法,打印出K折交叉验证得分的平均结果:
logreg_bagging_model = BaggingClassifier(base_estimator=LogReg_clf, n_estimators=50, random_state=12)
dtree_bagging_model = BaggingClassifier(base_estimator=DTree_clf, n_estimators=50, random_state=12)
random_forest = RandomForestClassifier(n_estimators=100, random_state=12)
extra_trees = ExtraTreesClassifier(n_estimators=100, random_state=12)
def bagging_ensemble(model):
k_folds = KFold(n_splits=20, random_state=12)
results = cross_val_score(model, X_train, y_train, cv=k_folds)
print(results.mean())
bagging_ensemble(logreg_bagging_model)
bagging_ensemble(dtree_bagging_model)
bagging_ensemble(random_forest)
bagging_ensemble(extra_trees)这是我们从分类器中得到的结果:
0.7865853658536585
0.8102439024390244
0.8002439024390245
0.7902439024390244提升分类示例
最后,我们将研究如何使用增强分类方法。如前所述,还有另一篇关于梯度增强的文章,您可以在这里阅读。
Scikit-Learn具有内置的AdaBoost分类器,该分类器将给定数量的估计器作为第一个参数。我们可以尝试使用for循环来查看分类性能在不同值下如何变化,也可以将其与K折交叉验证工具结合使用:
k_folds = KFold(n_splits=20, random_state=12)
num_estimators = [20, 40, 60, 80, 100]
for i in num_estimators:
ada_boost = AdaBoostClassifier(n_estimators=i, random_state=12)
results = cross_val_score(ada_boost, X_train, y_train, cv=k_folds)
print("Results for {} estimators:".format(i))
print(results.mean())这是我们得到的结果:
Results for 20 estimators:
0.8015243902439024
Results for 40 estimators:
0.8052743902439025
Results for 60 estimators:
0.8053048780487805
Results for 80 estimators:
0.8040243902439024
Results for 100 estimators:
0.8027743902439024总结
我们已经介绍了三种不同的集成分类技术背后的思想:投票\堆叠,套袋和增强。
Scikit-Learn使您可以轻松创建不同集合分类器的实例。这些合奏对象可以与其他Scikit-Learn工具结合使用,例如K-folds交叉验证。