只需轻按我们手机上的一个按钮,几分钟之内即可随时随地使用出租车,这真的很容易。
Uber/Ola/Lyft ……使用这些应用程序并获得无忧的交通服务真的很简单,但是构建这些拥有数百名软件工程师十年的巨大应用程序是否也很简单……?当然不。这些系统具有更复杂的架构,并且有许多组件在内部连接在一起,以在全球范围内提供骑行服务。设计 Uber(或 OLA 或 Lyft)是面试中系统设计回合中很常见的问题。许多候选人更害怕这一轮而不是编码轮,因为他们不知道在有限的时间内应该涵盖哪些主题和权衡。首先,请记住,系统设计回合是非常开放的,没有标准答案之类的东西。即使是同样的问题,不同的面试官也会有完全不同的讨论。

在本博客中,我们将讨论如何设计 Uber/Ola/Lyft 等叫车服务,但在我们进一步讨论之前,我们希望您阅读文章“如何在面试中破解系统设计?”。它会让你知道这一轮是什么样的,你应该做什么,以及在面试官面前应该避免哪些错误。
优步系统架构
我们都熟悉优步服务。用户可以通过应用程序叫车,几分钟内,司机就会到达他/她的位置附近,将他们带到目的地。早期的 Uber 是建立在“单体”软件架构模型上的。他们有一个后端服务、一个前端服务和一个数据库。他们使用Python及其框架和 SQLAlchemy 作为数据库的 ORM 层。这种架构适用于少数城市的少量出行,但当服务开始在其他城市扩展时,优步团队开始面临应用程序的问题。 2014年优步团队决定转向“面向服务的架构”,现在优步也处理外卖和货运。

1. 谈谈挑战
优步服务的主要任务之一是将乘客与出租车匹配,这意味着我们的架构中需要两种不同的服务,即
- 供应服务(出租车)
- 按需服务(针对乘客)
优步在其架构中有一个调度系统(调度优化/DISCO)来匹配供需。该调度系统使用手机,负责将司机与乘客相匹配(供需)。
2. 调度系统如何工作?
DISCO必须有这些目标……
- 减少额外的驾驶。
- 最短等待时间
- 最低总预计到达时间
调度系统完全适用于地图和位置数据/GPS,因此重要的第一件事是对我们的地图和位置数据进行建模。
- 地球是球形的,因此很难通过纬度和经度进行汇总和近似。为了解决这个问题,Uber 使用了Google S2 库。该库将地图数据划分为微小的单元格(例如 3km),并为每个单元格提供唯一 ID。这是一种在分布式系统中传播数据并轻松存储的简单方法。
- S2 库可以轻松覆盖任何给定形状。假设您想找出一个城市 3 公里半径范围内的所有可用供应品。使用 S2 库,您可以绘制一个半径为 3 公里的圆,它会过滤掉 ID 位于该特定圆内的所有单元格。通过这种方式,您可以轻松地将骑手与司机进行匹配,并且您可以轻松地找出特定地区可用的汽车(供应)数量。
3. 供应服务及其运作方式?
- 在我们的案例中,出租车是供应服务,它们将通过地理位置(纬度和经度)进行跟踪。所有活动的出租车每 4 秒通过 Web 应用程序防火墙和负载平衡器将位置发送到服务器。一旦通过负载均衡器,准确的 GPS 位置就会通过 Kafka 的 Rest API 发送到数据中心。这里我们使用Apache Kafka作为数据中心。
- 一旦 Kafka 更新了最新位置,它就会缓慢地通过各自的工作笔记主内存。
- 此外,位置的副本(状态机/出租车的最新位置)将发送到数据库和调度优化以保持最新位置更新。
- 我们还需要跟踪更多的事情,例如座位数量、儿童汽车座椅的存在、车辆类型、是否适合轮椅和分配(例如,出租车可能有四个座位,但其中两个已被占用.)
4. 按需服务及其运作方式?
- 需求服务通过网络套接字接收出租车的请求,并跟踪用户的 GPS 位置。它还收到不同类型的要求,例如座位数量、汽车类型或泳池车。
- 需求提供位置(小区 ID)和用户要求,以提供和请求出租车。
5. 调度系统如何匹配车手和司机?
- 我们已经讨论过 DISCO 将地图划分为具有唯一 ID 的小单元格。此 ID 在 DISCO 中用作分片键。当供应收到来自需求的请求时,使用单元 ID 作为分片键更新位置。这些微小的单元的职责将被划分到位于多个区域的不同服务器(一致性哈希)。例如,我们可以将 12 个小单元的职责分配给位于 6 个不同区域的 6 个不同的服务器(每个服务器 2 个单元)。
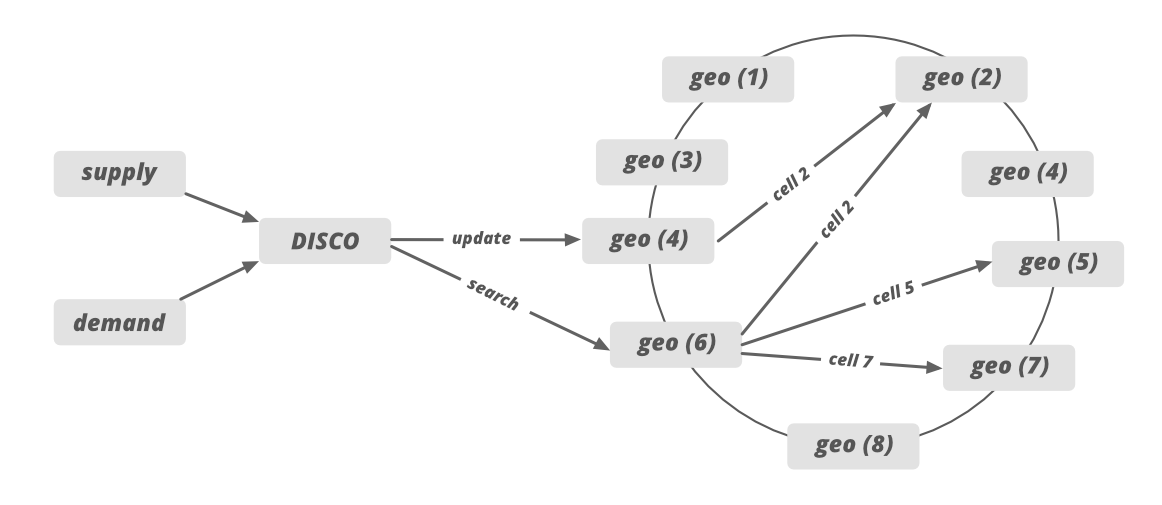
- Supply 根据 GPS 位置数据将请求发送到特定服务器。之后,系统绘制圆圈并过滤掉附近所有符合骑手要求的驾驶室。
- 之后,驾驶室列表被发送到 ETA 以计算骑手和驾驶室之间的距离,不是地理上而是道路系统。
- 然后将分类后的 ETA 发送回供应系统以将其提供给司机。
如果我们需要处理新增城市的流量,那么我们可以增加服务器的数量,并将新增城市小区 ID 的职责分配给这些服务器。
6.如何扩展调度系统?
- 调度系统(包括供应、需求和网络套接字)建立在NodeJS之上。 NodeJS 是一个异步和基于事件的框架,允许您随时通过 WebSockets 发送和接收消息。
- 优步使用开源ringpop使应用程序具有协作性和可扩展性,以应对高流量。 Ring pop 主要由三个部分组成,它执行以下操作来扩展调度系统。
- 它维护一致的散列以在工作人员之间分配工作。它有助于以可扩展和容错的方式对应用程序进行分片。
- Ringpop 使用RPC(远程过程调用)协议从一台服务器到另一台服务器进行调用。
- Ringpop 还使用SWIM 成员协议/八卦协议,允许独立的工作人员发现彼此的责任。这样每个服务器/节点都知道其他节点的责任和工作。
- Ringpop 检测集群中新添加的节点和从集群中删除的节点。它在添加或删除节点时均匀分配负载。
7. Uber 如何定义地图区域?
在新地区开展新业务之前,优步将新地区加入地图技术堆栈。在这个地图区域中,我们定义了标有 A、B、AB 和 C 等级的各个子区域。
A级:该次区域负责覆盖城市中心和通勤区。该次区域覆盖了大约 90% 的 Uber 流量,因此为次区域 A 构建最高质量的地图非常重要。
B 级:该次区域涵盖人口较少且 Uber 客户出行较少的农村和郊区。
AB 级: A 级和 B 级次区域的结合。
C 级:涵盖连接各个优步领地的一组高速公路走廊。
8. Uber 如何构建地图?
优步使用第三方地图服务提供商在他们的应用程序中构建地图。早些时候 Uber 使用 Mapbox 服务,但后来 Uber 改用 Google Maps API 来跟踪位置并计算 ETA。
1. 轨迹覆盖:轨迹覆盖发现缺失的路段或不正确的道路几何形状。轨迹覆盖计算基于两个输入:测试中的地图数据和特定时间段内所有 Uber 行程的历史 GPS 轨迹。它将这些 GPS 轨迹覆盖到地图上,将它们与路段进行比较和匹配。如果我们在 GPS 轨迹上发现缺失的路段(未显示道路),那么我们将采取一些步骤来修复缺陷。
2.首选访问(接送)点准确性:当我们在优步预订出租车时,我们会在我们的应用程序中获得接送点。上车点在 Uber 中非常重要,尤其是对于机场、大学校园、体育场、工厂或公司等大型场所。我们计算实际位置与司机使用的所有接送点之间的距离。

图片来源:https://eng.uber.com/maps-metrics-computation/
然后计算最短距离(最近的取货点),并将该位置的大头针设置为地图上的首选接入点。当骑手请求地图图钉指示的位置时,地图会将驾驶员引导至首选接入点。继续计算最新的实际接送地点,以确保建议的首选接入点的新鲜度和准确性。优步使用机器学习和不同的算法来确定首选接入点。
9. 如何计算 ETA?
ETA 是优步的一个极其重要的指标,因为它直接影响乘车匹配和收入。 ETA 是根据道路系统(而非地理)计算的,计算 ETA 涉及很多因素(如交通繁忙或道路建设)。当骑手从某个位置请求出租车时,该应用程序不仅可以识别空闲/空闲出租车,还包括即将完成乘车的出租车。有可能即将结束行程的驾驶室之一比远离用户的驾驶室更接近需求。路上有很多超级汽车每 4 秒发送一次 GPS 位置,因此为了预测交通,我们可以使用驾驶员应用程序的 GPS 位置数据。
我们可以在图表上表示整个道路网络来计算 ETA。我们可以使用 AI 模拟算法或简单的Dijkstra 算法来找出该图中的最佳路线。在该图中,节点表示交叉点(可用出租车),边表示路段。我们通过边权重表示路段距离或行驶时间。我们还在图中表示和建模了一些其他因素,例如单向街道、转弯成本、转弯限制和速度限制。
一旦确定了数据结构,我们就可以使用 Dijkstra 的搜索算法找到最佳路线,这是当今最好的现代路由算法之一。为了获得更快的性能,我们还需要使用基于收缩层次结构的 OSRM(开源路由机)。基于收缩层次结构的系统只需几毫秒即可通过对路由图进行预处理来计算路由。
10. 数据库
优步不得不考虑数据库的一些要求,以获得更好的客户体验。这些要求是……
- 数据库应该是水平可扩展的。您可以通过添加更多服务器来线性增加容量。
- 它应该能够处理大量读取和写入,因为每 4 秒一次,出租车将发送 GPS 位置,并且该位置将在数据库中更新。
- 系统不应为任何操作提供停机时间。无论您执行什么操作(扩展存储、备份、添加新节点等),它都应该是高度可用的。
早些时候 Uber 使用的是 RDBMS PostgreSQL 数据库,但由于可扩展性问题,Uber 切换到了各种数据库。 Uber 使用构建在 MySQL 数据库之上的 NoSQL 数据库(无模式)。
- Redis 用于缓存和排队。有些在 Twemproxy 后面(提供缓存层的可扩展性)。有些是在自定义集群系统后面。
- Uber 使用无模式(内部构建在 MySQL 之上)、Riak 和 Cassandra。 Schemaless 用于长期数据存储。 Riak 和 Cassandra 满足高可用性、低延迟的需求。
- MySQL 数据库。
- Uber 正在构建自己的分布式列存储,用于编排一堆 MySQL 实例。
11. 分析
为了优化系统,最大限度地降低运营成本,为了更好的客户体验,优步进行日志收集和分析。优步使用不同的工具和框架进行分析。对于日志分析,Uber 使用了多个 Kafka 集群。 Kafka 获取历史数据和实时数据。数据在从 Kafka 过期之前被存档到 Hadoop 中。数据还被索引到 Elastic 搜索堆栈中以进行搜索和可视化。弹性搜索使用 Kibana/Graphana 进行一些日志分析。优步使用不同工具和框架进行的一些分析是……
- 跟踪 HTTP API
- 管理个人资料
- 收集反馈和评级
- 促销和优惠券等
- 欺诈识别
- 付款欺诈
- 司机滥用奖励
- 被黑客入侵的帐户。优步使用客户的历史数据和一些机器学习技术来解决这个问题。
12. 如何处理数据中心故障?
数据中心故障并不经常发生,但 Uber 仍然维护着一个备份数据中心,以确保行程顺利进行。该数据中心包括所有组件,但优步从不将现有数据复制到备份数据中心。
那么优步是如何解决数据中心故障的呢??
它实际上使用驾驶员手机作为行程数据的来源来解决数据中心故障的问题。
当司机的手机应用程序与调度系统通信或它们之间发生 API 调用时,调度系统将加密的状态摘要(以跟踪最新信息/数据)发送到司机的手机应用程序。每次这个状态摘要都会被司机的手机应用程序收到。如果数据中心发生故障,备份数据中心(备份 DISCO)对行程一无所知,因此它会从司机的手机应用程序中询问状态摘要,并使用司机手机收到的状态摘要信息更新自己应用程序。
GeeksforGeeks 系统设计课程
想在领先的科技公司获得软件开发人员/工程师的工作吗?或 想要从 SDE I 平稳过渡到 SDE II 或高级开发人员配置文件?如果是,那么您需要深入了解系统设计世界!对系统设计概念的正确掌握非常重要,尤其是对于工作专业人士而言,要在技术面试中获得比其他人急需的优势。

这就是为什么 GeeksforGeeks 为您提供以深度面试为中心的系统设计直播课程,帮助您准备与 Google、亚马逊、Adobe、优步和其他基于产品的公司的系统设计相关的问题。