语音识别是家庭自动化、人工智能等应用中的一个重要功能。本文旨在介绍如何使用Python 的语音识别库。这很有用,因为它可以在外部麦克风的帮助下用于微控制器,例如 Raspberri Pis。
所需安装
必须安装以下内容:
- Python语音识别模块:
sudo pip install SpeechRecognition - PyAudio: Linux 用户使用以下命令
sudo apt-get install python-pyaudio python3-pyaudio如果存储库中的版本太旧,请使用以下命令安装 pyaudio
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev && sudo pip install pyaudio对于 python3,使用 pip3 而不是 pip。
Windows 用户可以通过在终端中执行以下命令来安装 pyaudiopip install pyaudio
使用麦克风的语音输入和语音到文本的翻译
- 配置麦克风(对于外部麦克风):建议在程序期间指定麦克风以避免任何故障。
在终端中输入lsusb 。将显示已连接设备的列表。麦克风名称如下所示USB Device 0x46d:0x825: Audio (hw:1, 0)记下这一点,因为它将在程序中使用。
- 设置块大小:这主要涉及指定我们要一次读取多少字节的数据。通常,此值以 2 的幂指定,例如 1024 或 2048
- 设置采样率:采样率定义了记录值进行处理的频率
- 将设备 ID 设置为选定的麦克风:在此步骤中,我们指定我们希望使用的麦克风的设备 ID,以避免在有多个麦克风的情况下产生歧义。这也有助于调试,从某种意义上说,在运行程序时,我们将知道是否正在识别指定的麦克风。在程序中,我们指定了一个参数 device_id。如果无法识别麦克风,程序会说找不到 device_id。
- 允许调整环境噪声:由于周围的噪声会发生变化,我们必须让程序一秒或太多来调整记录的能量阈值,以便根据外部噪声水平进行调整。
- 语音到文本翻译:这是在 Google Speech Recognition 的帮助下完成的。这需要有效的互联网连接才能工作。但是,有某些离线识别系统,例如 PocketSphinx,但是安装过程非常严格,需要多个依赖项。谷歌语音识别是最容易使用的之一。
以上步骤已实现如下:
#Python 2.x program for Speech Recognition import speech_recognition as sr #enter the name of usb microphone that you found #using lsusb #the following name is only used as an example mic_name = "USB Device 0x46d:0x825: Audio (hw:1, 0)" #Sample rate is how often values are recorded sample_rate = 48000 #Chunk is like a buffer. It stores 2048 samples (bytes of data) #here. #it is advisable to use powers of 2 such as 1024 or 2048 chunk_size = 2048 #Initialize the recognizer r = sr.Recognizer() #generate a list of all audio cards/microphones mic_list = sr.Microphone.list_microphone_names() #the following loop aims to set the device ID of the mic that #we specifically want to use to avoid ambiguity. for i, microphone_name in enumerate(mic_list): if microphone_name == mic_name: device_id = i #use the microphone as source for input. Here, we also specify #which device ID to specifically look for incase the microphone #is not working, an error will pop up saying "device_id undefined" with sr.Microphone(device_index = device_id, sample_rate = sample_rate, chunk_size = chunk_size) as source: #wait for a second to let the recognizer adjust the #energy threshold based on the surrounding noise level r.adjust_for_ambient_noise(source) print "Say Something" #listens for the user's input audio = r.listen(source) try: text = r.recognize_google(audio) print "you said: " + text #error occurs when google could not understand what was said except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e))将音频文件转录为文本
如果我们有一个音频文件要翻译成文本,我们只需要用音频文件而不是麦克风替换源文件。
为方便起见,将音频文件和程序放在同一文件夹中。这适用于 FLAC 文件的 WAV、AIFF。
下面显示了一个实现#Python 2.x program to transcribe an Audio file import speech_recognition as sr AUDIO_FILE = ("example.wav") # use the audio file as the audio source r = sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: #reads the audio file. Here we use record instead of #listen audio = r.record(source) try: print("The audio file contains: " + r.recognize_google(audio)) except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e))
故障排除
常见的有以下问题
- 静音麦克风:这会导致无法接收到输入。要检查这一点,您可以使用 alsamixer。
它可以使用安装sudo apt-get install libasound2 alsa-utils alsa-oss输入混合器。输出看起来有点像这样
Simple mixer control 'Master', 0 Capabilities: pvolume pswitch pswitch-joined Playback channels: Front Left - Front Right Limits: Playback 0 - 65536 Mono: Front Left: Playback 41855 [64%] [on] Front Right: Playback 65536 [100%] [on] Simple mixer control 'Capture', 0 Capabilities: cvolume cswitch cswitch-joined Capture channels: Front Left - Front Right Limits: Capture 0 - 65536 Front Left: Capture 0 [0%] [off] #switched off Front Right: Capture 0 [0%] [off]如您所见,捕获设备当前已关闭。要打开它,请输入alsamixer
正如您在第一张图片中看到的,它正在显示我们的播放设备。按 F4 切换到捕获设备。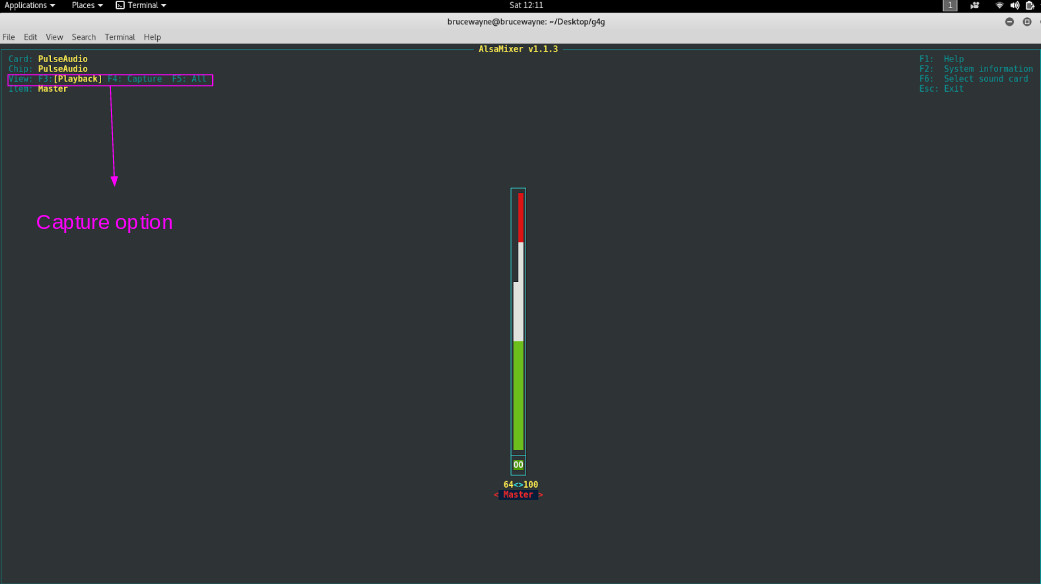
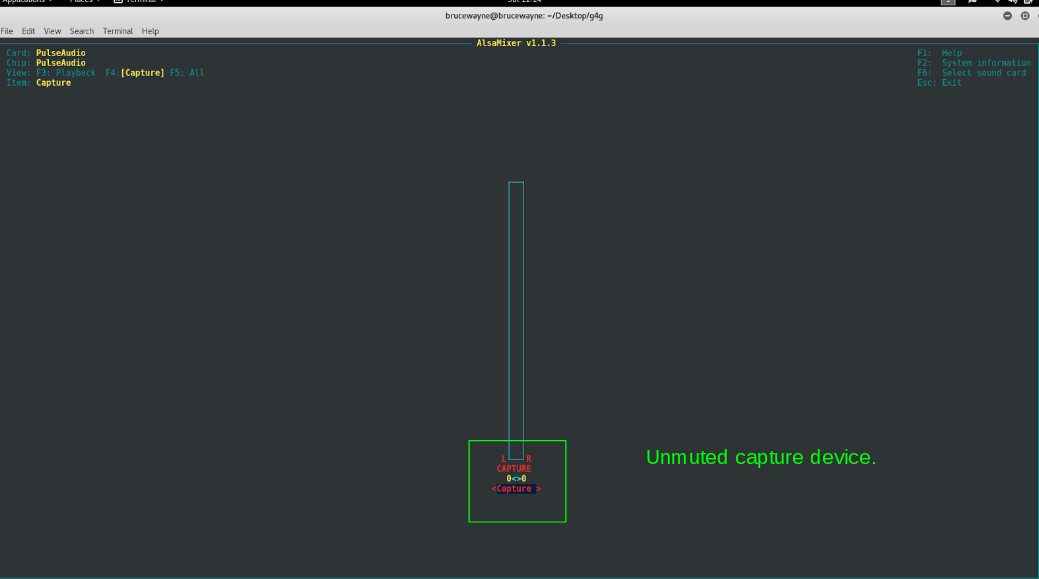
在第二张图片中,突出显示的部分显示捕获设备已静音。要取消静音,请按空格键

正如您在最后一张图片中看到的,突出显示的部分确认捕获设备未静音。
- 当前麦克风未被选为捕获设备:
在这种情况下,可以通过键入alsamixer并选择声卡来设置麦克风。在这里,您可以选择默认麦克风设备。
如图,突出显示的部分是您必须选择声卡的地方。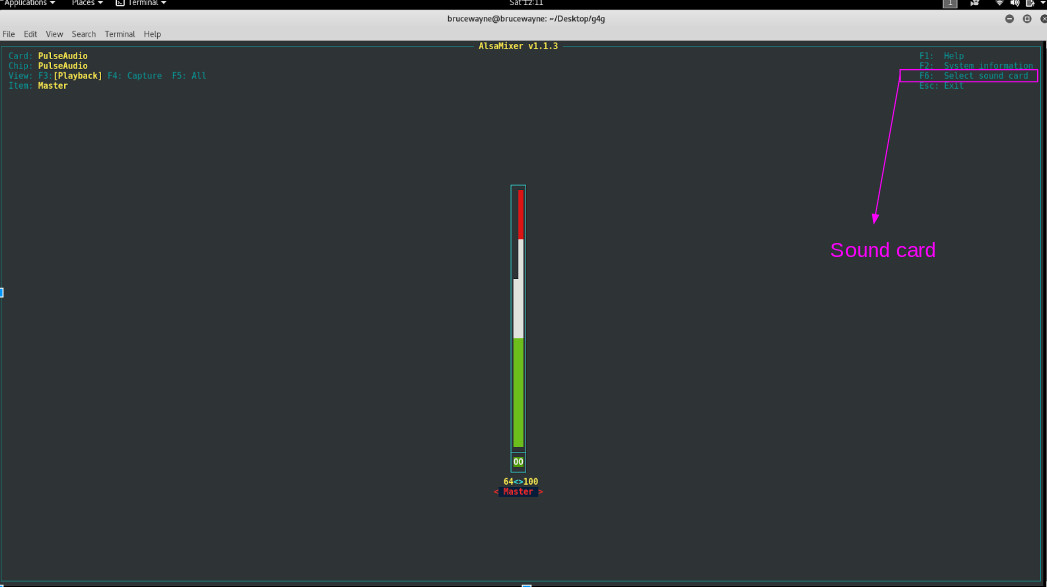
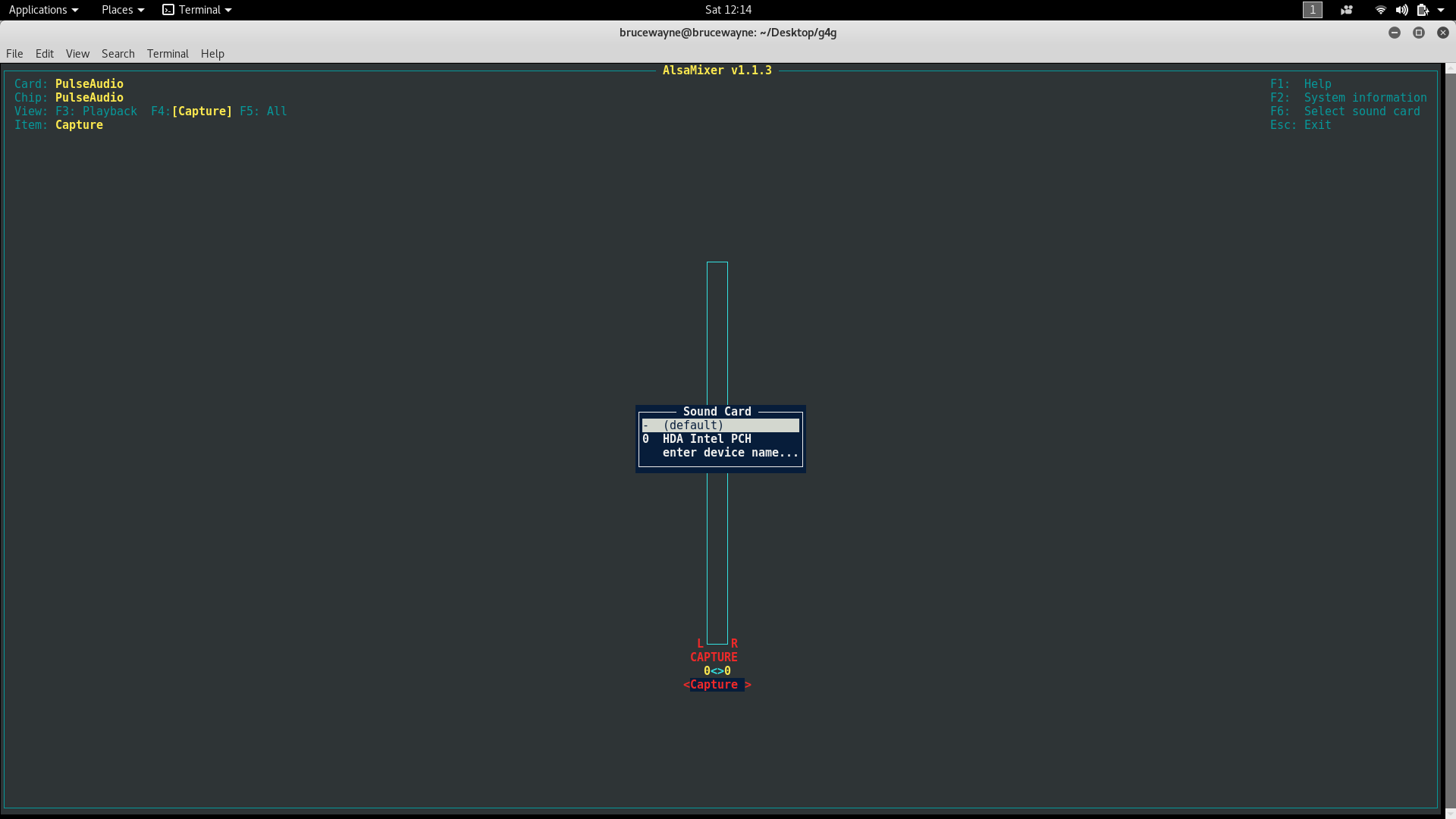
第二张图为声卡选择画面
- 无 Internet 连接:语音到文本的转换需要有效的 Internet 连接。