📌 相关文章
- 语音识别(1)
- 语音识别 - 任何代码示例
- javascript 语音识别 - Javascript (1)
- 如何在 python 代码示例中使用语音识别
- javascript 语音识别 - Javascript 代码示例
- Python语音识别简介(1)
- Python语音识别简介
- 语音识别 github - CSS (1)
- 语音识别 github - CSS 代码示例
- 如何在 python 中修复语音识别(1)
- 如何在 python 代码示例中修复语音识别
- 带有Python的AI –语音识别(1)
- 带有Python的AI –语音识别
- 使用语音识别重新启动计算机(1)
- 使用语音识别重新启动计算机
- 使用Python进行印地语语音识别
- 使用Python进行印地语语音识别(1)
- Python中的文本到语音转换语音
- Python中的文本到语音转换语音(1)
- python chatbot 语音识别 - Python (1)
- python chatbot 语音识别 - Python 代码示例
- Python – 使用语音识别获取今天的当前日期(1)
- Python – 使用语音识别获取今天的当前日期
- 文本到语音 (1)
- 语音到文本 (1)
- Python |大型音频文件上的语音识别(1)
- Python |大型音频文件上的语音识别
- 网络安全中的语音生物识别技术
- 语音转文本 - Python (1)
📜 语音识别
📅 最后修改于: 2020-11-25 05:54:01 🧑 作者: Mango
语音识别生物特征识别方式是生理和行为方式的结合。语音识别不过是声音识别。它依赖于受-
-
生理成分-人声带以及嘴唇,牙齿,舌头和口腔的物理形状,大小和健康状况。
-
行为成分-说话时人的情绪状态,口音,语调,语调,说话速度,喃喃自语等。
语音识别系统
语音识别也称为说话者识别。在注册时,用户需要向麦克风说一个单词或短语。这是获取候选人的语音样本所必需的。
来自麦克风的电信号由模数(ADC)转换器转换为数字信号。它作为数字化样本记录到计算机内存中。然后,计算机比较并尝试将候选者的输入语音与存储的数字化语音样本进行匹配,并识别候选者。
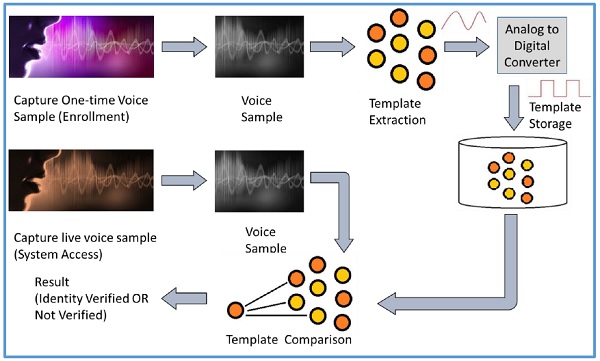
语音识别方式
语音识别有两种变体-取决于说话者和与说话者无关。
取决于说话者的语音识别依赖于候选人特定语音特征的知识。该系统通过语音训练(或注册)来学习那些特征。
-
该系统需要在使用之前接受用户培训,以使其习惯于特定的口音和语调,然后才能识别出所说的内容。
-
如果只有一个用户要使用该系统,则这是一个不错的选择。
独立于扬声器的系统能够通过限制语音上下文(例如单词和短语)来识别来自不同用户的语音。这些系统用于自动电话接口。
-
他们不需要在每个用户上培训系统。
-
在不需要识别每个候选人的语音特征的情况下,它们是供不同个人使用的好选择。
语音和语音识别之间的区别
说话人识别和语音识别被误认为是相同的;但是它们是不同的技术。让我们看看-
| Speaker Recognition (Voice Recognition) | Speech Recognition |
|---|---|
| The objective of voice recognition is to recognize WHO is speaking. | The speech recognition aims at understanding and comprehending WHAT was spoken. |
| It is used to identify a person by analyzing its tone, voice pitch, and accent. | It is used in hand-free computing, map, or menu navigation. |
语音识别的优点
- 易于实现。
语音识别的缺点
- 它容易受到麦克风质量和噪音的影响。
-
无法控制影响输入系统的因素会大大降低性能。
-
一些说话者验证系统还容易通过录制的语音进行欺骗攻击。
语音识别的应用
- 执行电话和互联网交易。
-
与基于交互式语音响应(IRV)的银行和卫生系统一起使用。
- 为数字文档应用音频签名。
- 在娱乐和紧急服务中。
- 在在线教育系统中。