使用 R 编程的完全随机化设计
实验设计是统计学中方差分析的一部分。它们是预定义的算法,可帮助我们分析实验单元中组均值之间的差异。完全随机设计 (CRD) 是 Anova 类型的一部分。
完全随机设计:
设计实验的三个基本原则是复制、封闭和随机化。在这种类型的设计中,阻塞不是算法的一部分。实验样本是随机的,重复分配到不同的实验单元。让我们考虑下面的一些实验,并在 R 编程中实现该实验。
实验一
在蛋糕中加入更多的发酵粉会增加蛋糕的高度。让我们用 CRD 看看如何分析实验。
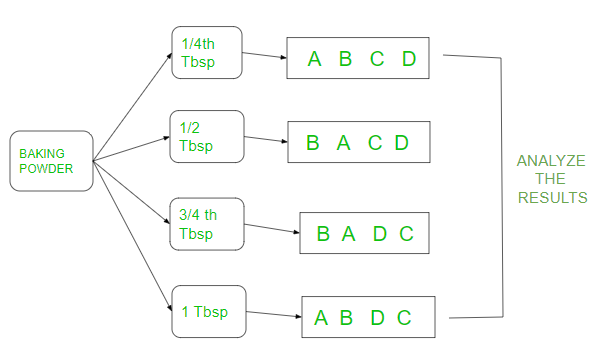
如上图所示,发酵粉被分成 4 个不同的汤匙(tbsp),并以随机顺序制作每个 tbsp 的四个复制蛋糕高度(分别为 A、B、C、D)。然后比较tbsp的结果,看看实际上高度是否受到发酵粉的影响。复制只是分别为A,B,C,D的不同蛋糕高度的排列。让我们看看上面的R语言示例。每个蛋糕的高度都是随机标注的。
tbsp 0.25 0.5 0.75 1
1.4 7.8 7.6 1.6
#(A,B,C,D)
2.0 9.2 7.0 3.4
#(A,B,D,C)
2.3 6.8 7.3 3.0
#(B,A,D,C)
2.5 6.0 5.5 3.9 #(B,A,C,D)
# the randomization is done directly by the program
蛋糕的复制是通过以下代码完成的:
R
treat <- rep(c("A", "B", "C", "D"), each = 4)
fac <- factor(rep(c(0.25, 0.5, 0.75, 1), each = 4))
treatR
height <- c(1.4, 2.0, 2.3, 2.5,
7.8, 9.2, 6.8, 6.0,
7.6, 7.0, 7.3, 5.5,
1.6, 3.4, 3.0, 3.9)
exp <- data.frame(treat, treatment = fac, response = height)
mod <- aov(response ~ treatment, data = exp)
summary(mod)R
rocks<- rep(c("four", "six", "eight"), each = 3)
rocks
fac <- factor(rep(c(500, 600, 700), each = 3))
facR
height <- c(5, 5.5, 4.8,
5.3, 5, 4.3,
4.8, 4.3, 3.4)
exp1 <- data.frame(rocks, treatment = fac,
response = height)
mod <- aov(response ~ treatment, data = exp1)
summary(mod)输出:
[1] A A A A B B B B C C C C D D D D
Levels: A B C D
创建数据框:
电阻
height <- c(1.4, 2.0, 2.3, 2.5,
7.8, 9.2, 6.8, 6.0,
7.6, 7.0, 7.3, 5.5,
1.6, 3.4, 3.0, 3.9)
exp <- data.frame(treat, treatment = fac, response = height)
mod <- aov(response ~ treatment, data = exp)
summary(mod)
输出:
Df Sum Sq Mean Sq F value Pr(>F)
treatment 3 88.46 29.486 29.64 7.85e-06 ***
Residuals 12 11.94 0.995
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
解释:
对于每个实验,显着性是 0.05 或 0.01,这是由进行实验的人给出的。对于此示例,让我们将显着性视为 5%,即 0.05。我们应该看到 Pr(>F) 的值为 7.85e-06 ,即 < 0.05。因此拒绝假设。如果值 > 0.05,则接受假设。对于此示例,由于 Pr < 0.05,拒绝假设。让我们再考虑一个例子:
实验二
在水中加入石块会增加容器中水的高度。我们看图中的这个实验如下:
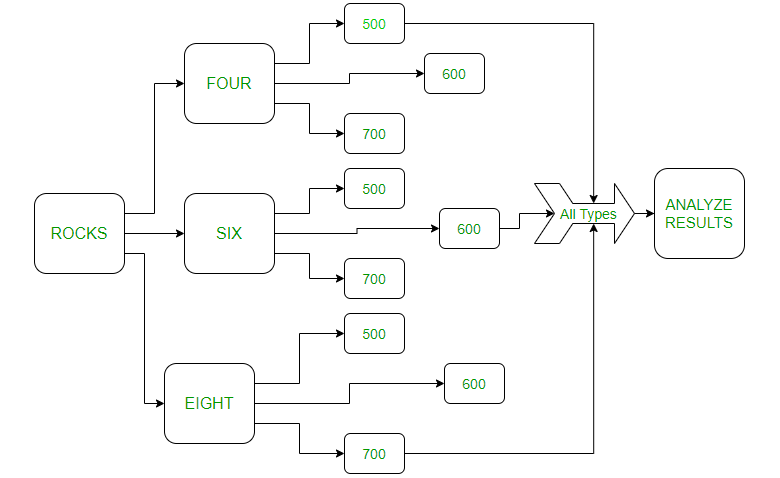
考虑到如果分别加入四块石头到500ml、600ml和700ml,水的高度会相应增加。例如:将 6 块岩石添加到 500 m 的水中会增加 7 ms 的高度。
rocks four six eight
5 5.3 6.2 [500 600 700]
5.5 5 5.7 [600 500 700]
4.8 4.3 3.4 [700 600 500]
让代码:
电阻
rocks<- rep(c("four", "six", "eight"), each = 3)
rocks
fac <- factor(rep(c(500, 600, 700), each = 3))
fac
输出:
[1] "four" "four" "four" "six" "six" "six" "eight" "eight" "eight"
[1] 500 500 500 600 600 600 700 700 700
Levels: 500 600 700
创建数据框:
电阻
height <- c(5, 5.5, 4.8,
5.3, 5, 4.3,
4.8, 4.3, 3.4)
exp1 <- data.frame(rocks, treatment = fac,
response = height)
mod <- aov(response ~ treatment, data = exp1)
summary(mod)
输出:
Df Sum Sq Mean Sq F value Pr(>F)
treatment 2 1.416 0.7078 2.368 0.175
Residuals 6 1.793 0.2989
解释:
这里 0.175>>0.05 因此假设被接受。