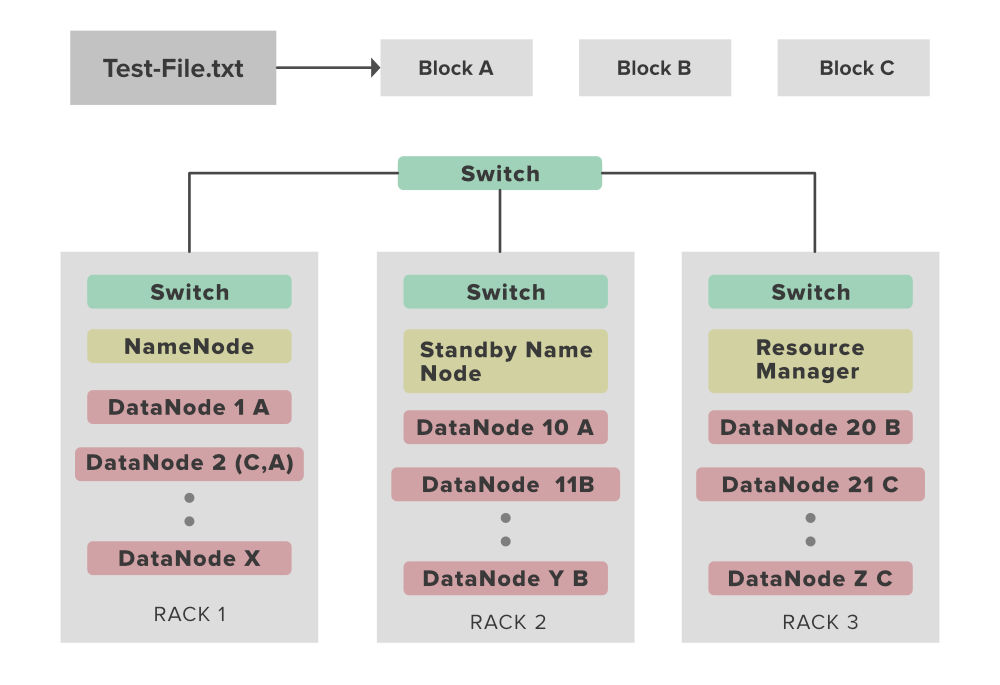
我们大多数人都熟悉术语Rack 。机架是我们 Hadoop 集群中节点的物理集合(可能是 30 到 40 个)。一个大型 Hadoop 集群由许多机架组成。在此机架信息的帮助下,Namenode 选择最近的 Datanode 以实现最大性能,同时执行减少网络流量的读/写信息。
一个机架可以有多个数据节点来存储文件块及其副本。 Hadoop 本身非常聪明,它会自动在 Rack 的 2 个不同数据节点中写入特定的文件块。如果您想将该数据块存储到 2 个以上的机架中,那么您可以这样做。此外,由于此功能是可配置的,因此您可以手动更改它。
集群中的机架示例:
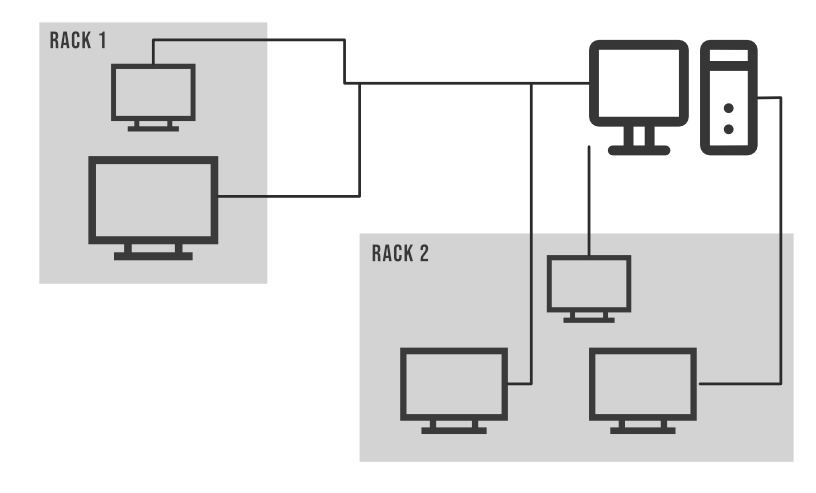
众所周知,一个大型的Hadoop集群包含多个Racks,每个Racks中都有大量的数据节点可用。存在于同一机架上的数据节点之间的通信比存在于 2 个不同机架上的数据节点之间的通信要快得多。
名称节点具有查找最近的数据节点以提高性能的功能,该名称节点保存 Hadoop 集群中存在的所有机架的 ID。选择最近的数据节点用于服务目的的概念是机架感知。
让我们通过一个例子来理解这一点。
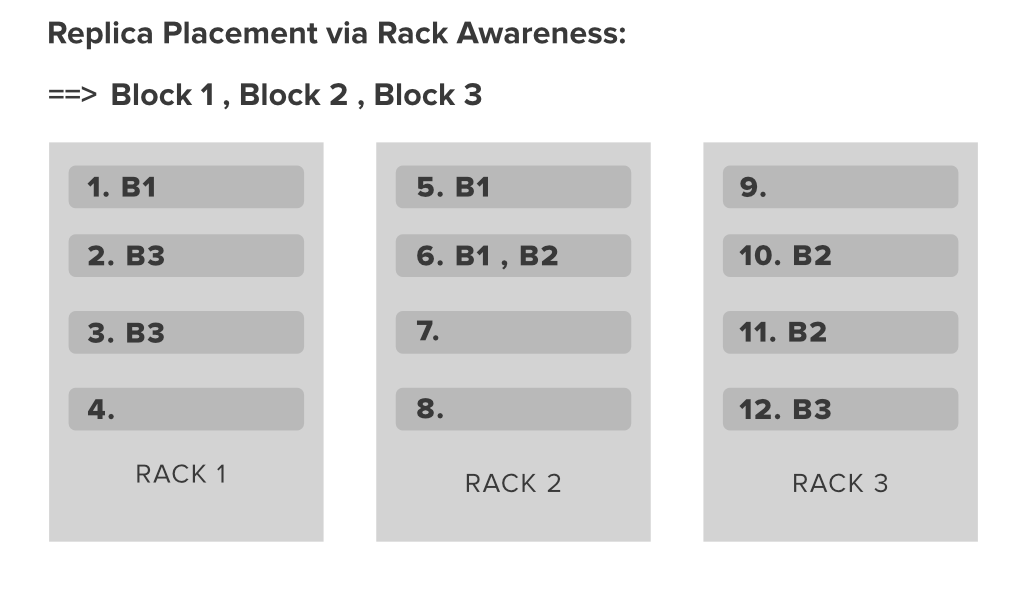
在上图中,我们的 Hadoop 集群中有 3 个不同的机架,每个机架包含 4 个数据节点。现在假设您有 3 个文件块(块 1、块 2、块 3)要放入此数据节点。众所周知,Hadoop 有一个 Feature 来制作文件块的副本,以提供高可用性和容错性。默认情况下,复制因子是 3,所以 Hadoop 非常聪明,它会将块的副本放在机架中,这样我们就可以获得良好的网络带宽。为此,Hadoop 有一些机架意识策略。
- 同一个 Datanode 上不应有超过 1 个副本。
- 同一个机架上不允许有超过 2 个单个块的副本。
- Hadoop 集群内使用的机架数必须小于副本数。
现在让我们继续上面的例子。在图中,我们可以很容易地发现,我们在 Rack 1 的第一个 Datanode 中有块 1,在 Rack 的 5 和 6 个数据节点中有 2 个 Block 1 的副本,总和为 3。同样,我们也有一个副本分布不同机架中的其他 2 个块遵循上述策略。
在我们的 Hadoop 集群中实施机架感知的好处:
- 通过机架感知策略,我们将数据存储在不同的机架中,因此不会丢失我们的数据。
- 机架感知有助于最大化网络带宽,因为数据块在机架内传输。
- 它还提高了集群性能并提供了高数据可用性。
HDFS 机架感知示例: