Hadoop 是一种开源软件编程框架,用于存储大量数据并执行计算。它的框架基于Java编程,带有一些用 C 和 shell 脚本编写的本机代码。
Hadoop 1 与 Hadoop 2
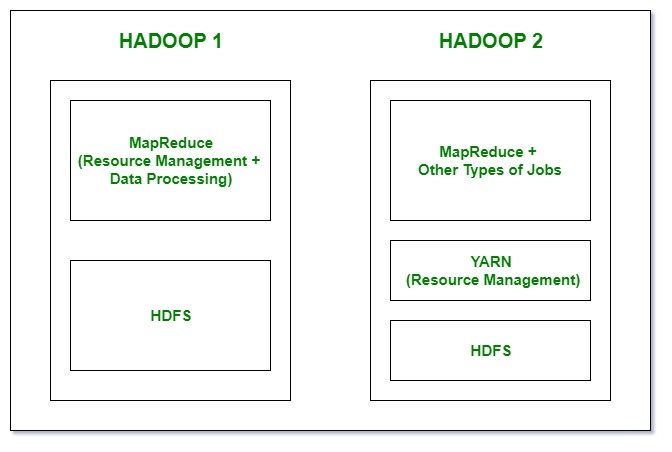
1. 组件:在 Hadoop 1 中,我们有 MapReduce,但 Hadoop 2 有 YARN(Yet Another Resource Negotiator)和 MapReduce 版本 2。
| Hadoop 1 | Hadoop 2
| HDFS |
HDFS |
Map Reduce |
YARN / MRv2 |
|
|---|
2. 守护进程:
| Hadoop 1 | Hadoop 2 |
|---|---|
| Namenode | Namenode |
| Datanode | Datanode |
| Secondary Namenode | Secondary Namenode |
| Job Tracker | Resource Manager |
| Task Tracker | Node Manager |
3. 工作:
- 在Hadoop 1 中,有用于存储和顶部的 HDFS,用作资源管理和数据处理的 Map Reduce。由于 Map Reduce 上的这种工作负载,它会影响性能。
- 在Hadoop 2 中,还有再次用于存储的 HDFS,在 HDFS 的顶部,还有用作资源管理的 YARN。它基本上分配资源并使所有事情继续进行。
4. 限制:
Hadoop 1是一种主从架构。它由一个主站和多个从站组成。假设如果主节点崩溃了,那么无论您的最佳从节点如何,您的集群都将被破坏。再次创建该集群意味着在另一个系统上复制系统文件、图像文件等非常耗时,这在当今的组织中是无法容忍的。
Hadoop 2也是一种主从架构。但这包括多个主节点(即活动名称节点和备用名称节点)和多个从节点。如果这里主节点崩溃,那么备用主节点将接管它。您可以进行多种主备节点组合。因此 Hadoop 2 将消除单点故障的问题。
5. 生态系统
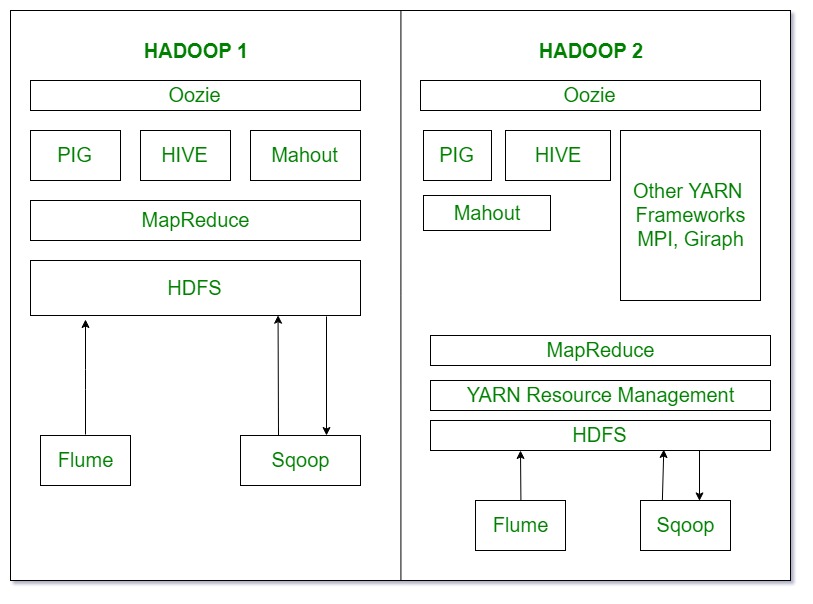
- Oozie基本上是工作流调度程序。它根据作业的依赖性决定作业的特定执行时间。
- Pig、 Hive和 Mahout是在 Hadoop 之上工作的数据处理工具。
- Sqoop用于导入和导出结构化数据。您可以使用 SQL 数据库直接将数据导入和导出到 HDFS。
- Flume用于非结构化数据和流数据的导入导出。