MapReduce 是一种编程模型,用于在 Hadoop 集群中并行执行分布式处理,这使得 Hadoop 工作得如此之快。当您处理大数据时,串行处理没有任何用处。 MapReduce 主要有两个分阶段划分的任务:
- 地图任务
- 减少任务
让我们通过一个实时的例子来理解它,这个例子帮助你以故事的方式理解 Mapreduce 编程模型:
- 假设印度政府给你分配了计算印度人口的任务。你可以要求所有你想要的资源,但你必须在 4 个月内完成这项任务。计算这么大一个国家的人口,对于一个人(你)来说,并不是一件容易的事。那么你的方法是什么?
- 解决这个问题的方法之一是将国家按州划分,并为每个州分配个人负责人,以统计该州的人口。
- 每个人的任务:每个人都必须访问该州的每个家庭,并需要保留每个家庭成员的记录:
State_Name Member_House1 State_Name Member_House2 State_Name Member_House3 . . State_Name Member_House n . .对于简单性,我们只采用了三个状态。
这是一个简单的分而治之的方法,每个人都会遵循这个方法来计算他/她所在州的人数。
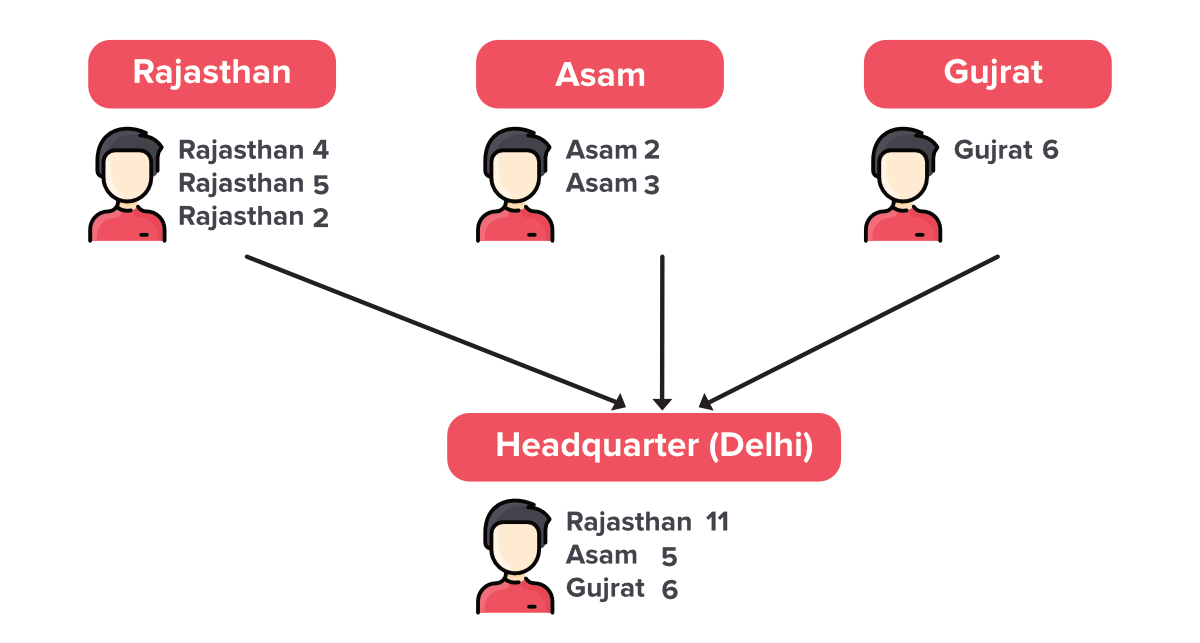
- 一旦他们计算了各自州的每个众议院成员。现在他们需要总结他们的结果,并需要将其发送到新德里的总部。
- 我们在总部有一名训练有素的官员,负责接收每个州的所有结果,并按每个州汇总它们以获得整个州的人口。现在,通过这种方法,您可以通过总结在总部获得的结果轻松计算印度的人口。
- 印度政府对你的工作很满意,明年他们要求你在 2 个月而不是 4 个月内做同样的工作。您将再次获得所需的所有资源。
- 由于政府。为您提供了所有资源,您只需将每个州的指定负责人数量从 1 倍增加到 2 倍。为此,将每个州分为 2 个部门,并为这两个部门分配不同的负责人:
State_Name_Incharge_division1 State_Name_Incharge_division2 - 同样,负责本部门的每个人都会从每个房屋中收集有关成员的信息并进行记录。
- 我们也可以在总部做同样的事情,所以我们也把总部分成两个部门:
Head-qurter_Division1 Head-qurter_Division2 - 现在使用这种方法,您可以在两个月内找到印度的人口。但这有一个小问题,我们永远不希望同一州的部门将结果发送到不同的总部,那么在这种情况下,我们在 Head-quarter_Division1 和 Head-quarter_Division2 中有该州的部分人口不一致,因为我们希望按国家统计合并人口,而不是部分计数。
- 一种简单的解决方法是我们可以指示一个州的所有个人将结果发送到 Head-quarter_Division1 或 Head-quarter_Division2。同样,对于所有状态。
- 我们的问题已经解决了,你两个月就成功解决了。
- 现在,如果他们让你在一个月内完成这个过程,你就知道如何解决这个问题了。
- 太好了,现在我们有一个很好的可扩展模型,效果很好。我们在这个例子中看到的模型类似于 MapReduce 编程模型。所以现在你必须意识到 MapReduce 是一种编程模型,而不是一种编程语言。
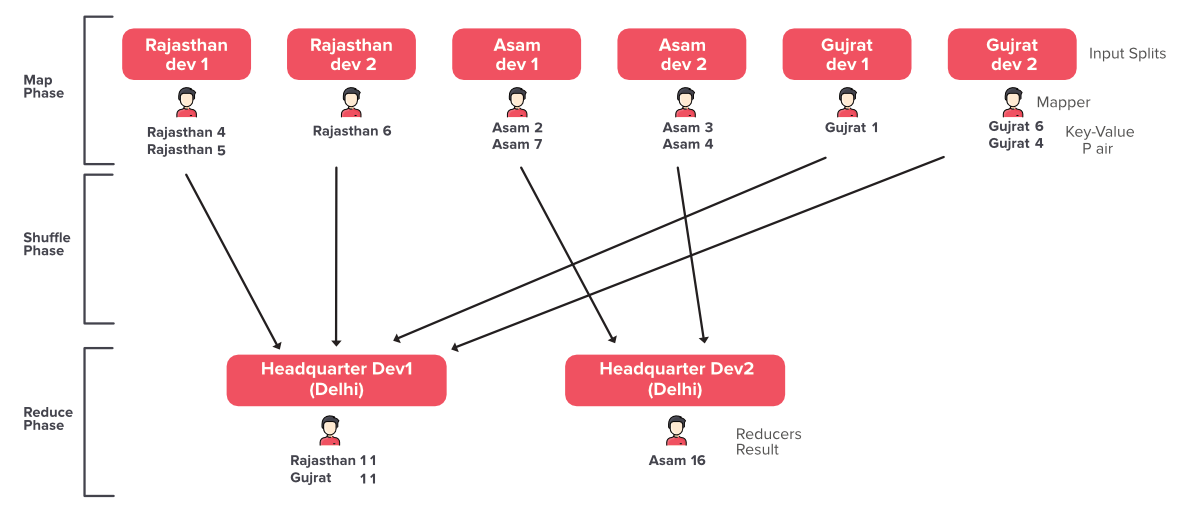
现在让我们讨论模型中涉及的阶段和重要事项。
1. 地图阶段:个别负责人正在收集他们部门内每个房屋的人口的阶段是地图阶段。
- Mapper:参与计算人口的个人负责人
- Input Splits:状态或状态的分割
- 键值对:每个映射器的输出,如键是拉贾斯坦邦,值是 2
2. 减少阶段:汇总结果的阶段
- Reducers:聚合实际结果的个体。在我们的例子中,训练有素的军官。每个 Reducer 将输出作为键值对产生
3、Shuffle阶段:数据从Mapper复制到Reducers的阶段是Shuffler的阶段。它介于 Map 和 Reduces 阶段之间。现在 Map 阶段、Reduce 阶段和 Shuffler 阶段是我们 Mapreduce 的三个主要阶段。