1912 年 4 月 14 日发生的那场灾难我们都耳熟能详。这艘 46000 吨重的巨轮在北大西洋沉没到 13000 英尺深。我们的目标是分析这次灾难后获得的数据。 Hadoop MapReduce 可用于有效处理这些大型数据集,以找到针对特定问题的任何解决方案。
问题陈述:分析泰坦尼克号灾难数据集,用 MapReduce Hadoop 找出在这次灾难中死亡的男性和女性的平均年龄。
第1步:
我们可以从此链接下载泰坦尼克号数据集。下面是我们泰坦尼克号数据集的列结构。它由 12 列组成,每行描述一个特定人的信息。

第2步:
数据集的前 10 条记录如下所示。

第 3 步:
使用以下步骤在 Eclipse 中创建项目:
- 首先打开Eclipse -> 然后选择File -> New -> Java Project -> 将其命名为Titanic_Data_Analysis -> 然后选择使用执行环境-> 选择JavaSE-1.8然后下一步-> Finish 。
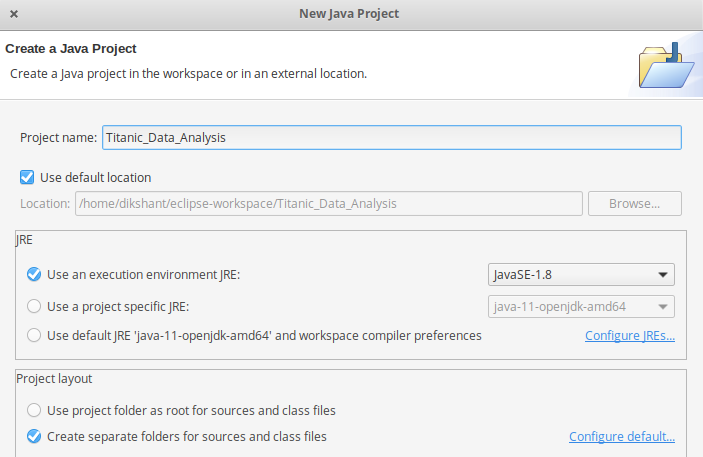
- 在此项目中创建名为Average_age 的Java类 -> 然后单击完成
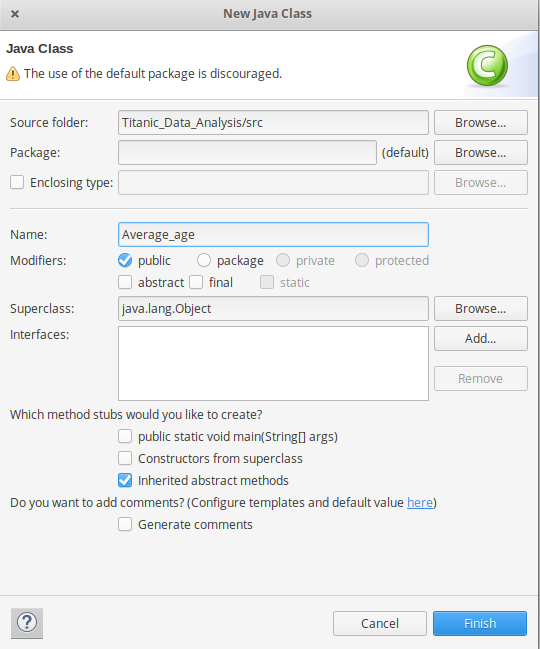
- 将下面的源代码复制到这个Average_age Java类
Java
// import libraries
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
// Making a class with name Average_age
public class Average_age {
public static class Map extends Mapper {
// private text gender variable which
// stores the gender of the person
// who died in the Titanic Disaster
private Text gender = new Text();
// private IntWritable variable age will store
// the age of the person for MapReduce. where
// key is gender and value is age
private IntWritable age = new IntWritable();
// overriding map method(run for one time for each record in dataset)
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
// storing the complete record
// in a variable name line
String line = value.toString();
// spliting the line with ', ' as the
// values are separated with this
// delimiter
String str[] = line.split(", ");
/* checking for the condition where the
number of columns in our dataset
has to be more than 6. This helps in
eliminating the ArrayIndexOutOfBoundsException
when the data sometimes is incorrect
in our dataset*/
if (str.length > 6) {
// storing the gender
// which is in 5th column
gender.set(str[4]);
// checking the 2nd column value in
// our dataset, if the person is
// died then proceed.
if ((str[1].equals("0"))) {
// checking for numeric data with
// the regular expression in this column
if (str[5].matches("\\d+")) {
// converting the numeric
// data to INT by typecasting
int i = Integer.parseInt(str[5]);
// storing the person of age
age.set(i);
}
}
}
// writing key and value to the context
// which will be output of our map phase
context.write(gender, age);
}
}
public static class Reduce extends Reducer {
// overriding reduce method(runs each time for every key )
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException
{
// declaring the variable sum which
// will store the sum of ages of people
int sum = 0;
// Variable l keeps incrementing for
// all the value of that key.
int l = 0;
// foreach loop
for (IntWritable val : values) {
l += 1;
// storing and calculating
// sum of values
sum += val.get();
}
sum = sum / l;
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
@SuppressWarnings("deprecation")
Job job = new Job(conf, "Averageage_survived");
job.setJarByClass(Average_age.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
Path out = new Path(args[1]);
out.getFileSystem(conf).delete(out);
job.waitForCompletion(true);
}
} - 现在我们需要为我们导入的包添加外部 jar。根据你的Hadoop版本下载Hadoop Common和Hadoop MapReduce Core的jar包。
检查 Hadoop 版本:
hadoop version
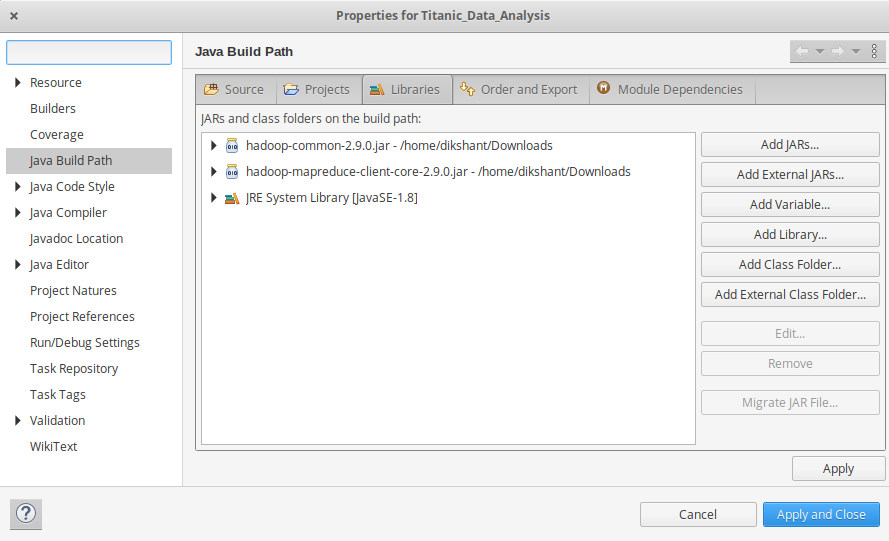
- 现在我们将这些外部 jar 添加到我们的Titanic_Data_Analysis项目中。右键单击Titanic_Data_Analysis -> 然后选择Build Path -> 单击Configue Build Path并选择Add External jars…。并从它的下载位置添加 jars 然后单击 -> Apply and Close 。
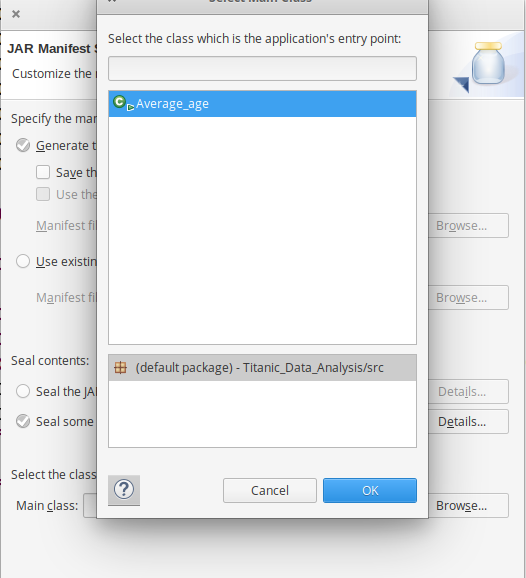
- 现在将项目导出为 jar 文件。右键单击Titanic_Data_Analysis选择Export..并转到Java -> JAR 文件单击 -> Next并选择您的导出目的地,然后单击 -> Next 。通过单击 -> Browse选择 Main Class 作为Average_age ,然后单击 -> Finish -> Ok 。
第四步:
启动 Hadoop 守护进程
start-dfs.sh start-yarn.sh然后,检查正在运行的 Hadoop 守护进程。
jps 
第 5 步:
将您的数据集移动到 Hadoop HDFS。
句法:
hdfs dfs -put /file_path /destination在下面的命令中/显示了我们 HDFS 的根目录。
hdfs dfs -put /home/dikshant/Documents/titanic_data.txt /检查发送到我们 HDFS 的文件。
hdfs dfs -ls /
第 6 步:
现在使用以下命令运行您的 Jar 文件并在Titanic_Output文件中生成输出。
句法:
hadoop jar /jar_file_location /dataset_location_in_HDFS /output-file_name命令:
hadoop jar /home/dikshant/Documents/Average_age.jar /titanic_data.txt /Titanic_Output 
第 7 步:
现在移至localhost:50070/ ,在实用程序下选择Browse the file system并在/MyOutput目录中下载part-r-00000以查看结果。
注意:我们也可以使用以下命令查看结果
hdfs dfs -cat /Titanic_Output/part-r-00000 
在上图中,我们可以看到,根据我们在泰坦尼克号灾难中死亡的数据集,女性的平均年龄为 28 岁,男性为 30 岁。