Apache Pig是一种数据操作工具,它构建在 Hadoop 的 MapReduce 之上。 Pig 为我们提供了一种脚本语言,可以更轻松、更快速地进行数据操作。这种脚本语言称为 Pig Latin。
Apache Pig 脚本可以通过以下 3 种方式执行:
- 使用 Grunt Shell(交互模式)——在 grunt shell 中编写命令并使用 DUMP 命令在那里获取输出。
- 使用 Pig 脚本(批处理模式)——将 pig latin 命令写入一个扩展名为 .pig 的文件中,并在提示符下执行脚本。
- 使用用户定义的函数(嵌入式模式)——用Java等语言编写自己的函数,然后在脚本中使用它们。
猪安装:
在继续之前,您需要确保您具备以下所有这些先决条件。
- Hadoop 生态系统安装在您的系统上,所有四个组件,即 DataNode、NameNode、ResourceManager、TaskManager 都在工作。如果其中任何一个随机关闭,那么您需要在继续之前修复它。
- 在 Windows 中解压 .tar.gz 文件需要 7-Zip。
下面我们来看看如何在Windows上安装Pig版本(0.17.0)。
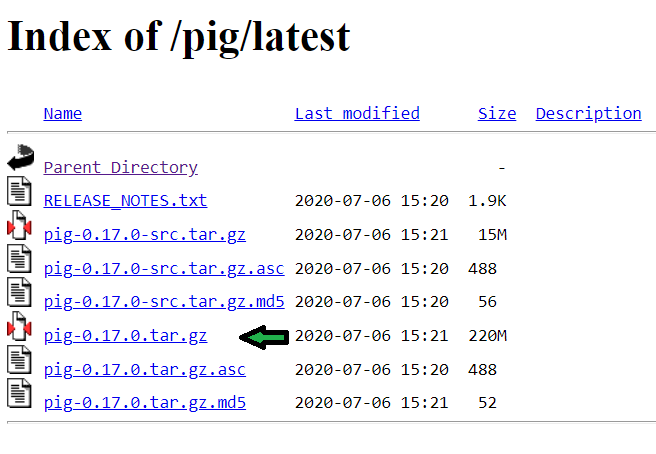
步骤 1:从官方 Apache pig 站点下载 Pig 0.17.0 版 tar 文件。导航到网站 https://downloads.apache.org/pig/latest/。从网站下载文件“pig-0.17.0.tar.gz”。
然后使用 7-Zip 工具提取这个 tar 文件(使用 7-Zip 以加快提取速度。首先我们通过右键单击它并单击“7-Zip → Extract Here”来提取 .tar.gz 文件。然后我们提取.tar 文件以同样的方式)。要获得与图中相同的路径,则需要在C:驱动器中提取。
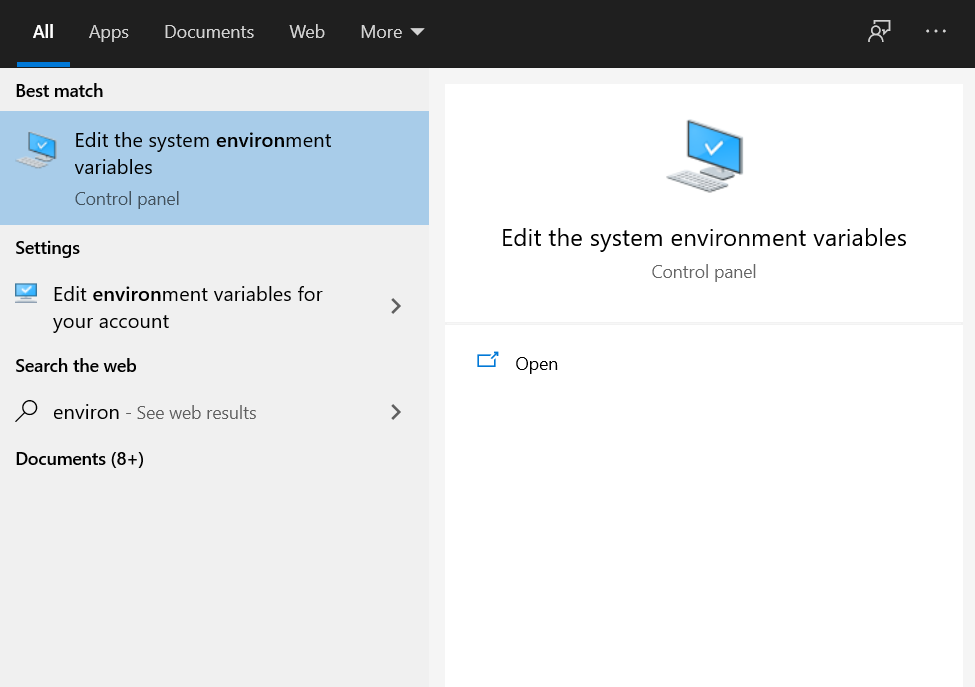
第二步:添加PIG_HOME和PIG_HOME\bin的路径变量
单击 Windows 按钮并在搜索栏中键入“环境变量”。然后单击“编辑系统环境变量”。
然后单击选项卡底部的“环境变量”。在新打开的选项卡中,单击用户变量部分中的“新建”按钮。
点击 new 在字段中添加以下值。
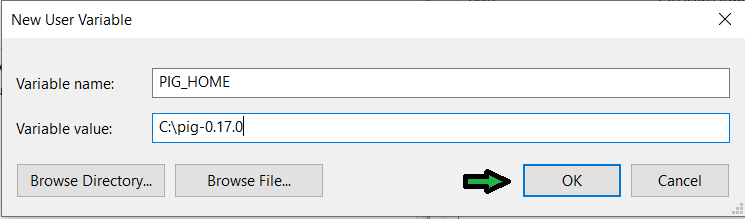
Variable Name - PIG_HOME
Variable value - C:\pig-0.17.0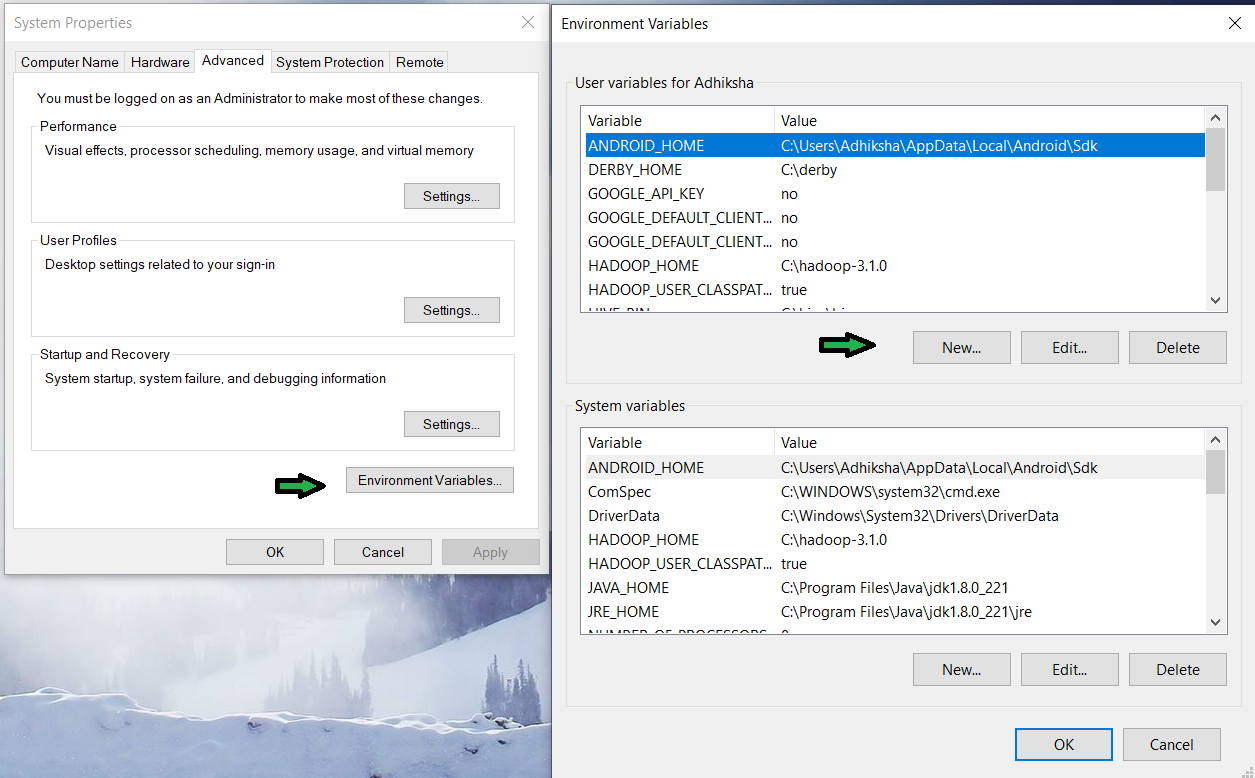
变量值字段中提取的猪文件夹的所有路径。我将其解压缩到“C”目录中。然后单击确定。
现在单击系统变量中的路径变量。这将打开一个新选项卡。然后单击“新建”按钮。并在文本框中添加值C:\pig-0.17.0\bin 。然后点击确定,直到所有选项卡都关闭。

步骤 3 :更正 Pig 命令文件
在pig文件(C:\pig-0.17.0\bin)的bin文件夹中找到文件’pig.cmd’
set HADOOP_BIN_PATH = %HADOOP_HOME%\bin找到这一行:
set HADOOP_BIN_PATH=%HADOOP_HOME%\bin 将此行替换为:
set HADOOP_BIN_PATH=%HADOOP_HOME%\libexec 并保存此文件。我们终于到了。现在您已准备好开始探索 Pig 及其环境。
有两种调用 grunt shell 的方法:
本地模式:所有文件都在本地机器上安装、访问和运行。无需使用 HDFS。在本地模式下运行 Pig 的命令如下。
pig -x local
MapReduce 模式:文件都存在于 HDFS 上。我们需要加载这些数据来处理它。在 MapReduce/HDFS 模式下运行 Pig 的命令如下。
pig -x mapreduce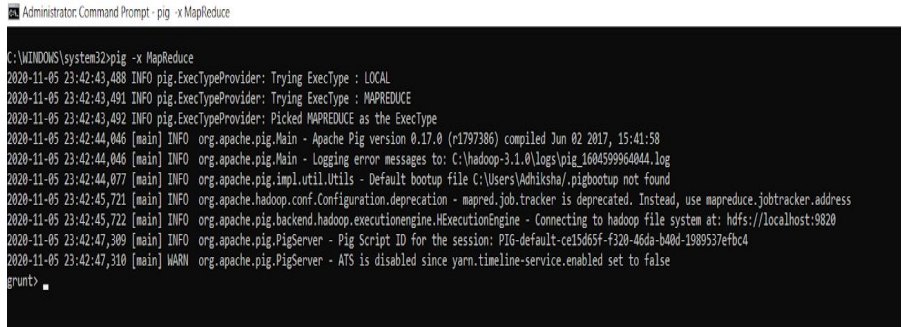
Apache PIG 案例研究:
1.下载包含农业相关数据的数据集,该数据集包含不同地区及其面积和产品的农作物。数据集链接 – https://www.kaggle.com/abhinand05/crop-production-in-india 数据集包含 7 列,如下所示。
State_Name : chararray ;
District_Name : chararray ;
Crop_Year : int ;
Season : chararray ;
Crop : chararray ;
Area : int ;
Production : intNo of rows: 246092
No of columns: 7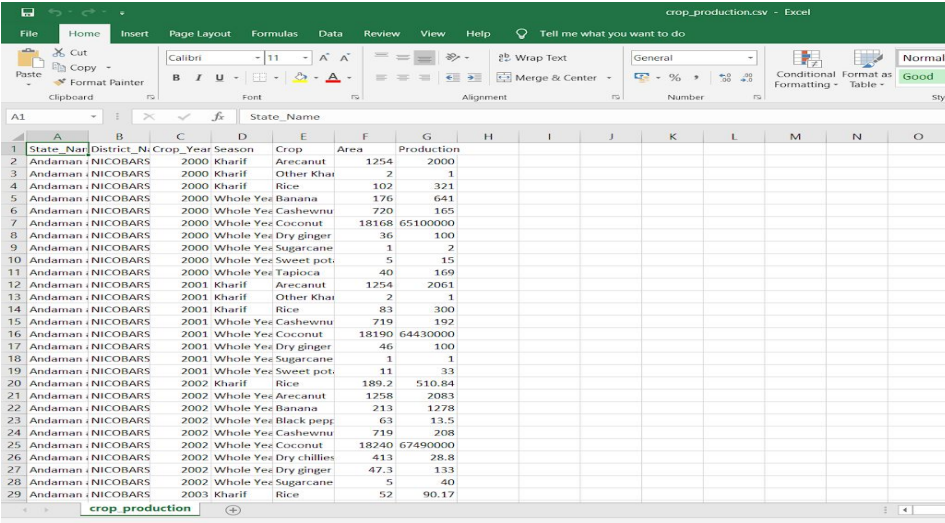
2.进入pig本地模式使用
grunt > pig -x local
3.以本地方式加载数据集
grunt > agriculture= LOAD 'F:/csv files/crop_production.csv' using PigStorage (',')
as ( State_Name:chararray , District_Name:chararray , Crop_Year:int ,
Season:chararray , Crop:chararray , Area:int , Production:int ) ;
4. 使用转储和描述数据集农业
grunt > dump agriculture;
grunt > describe agriculture;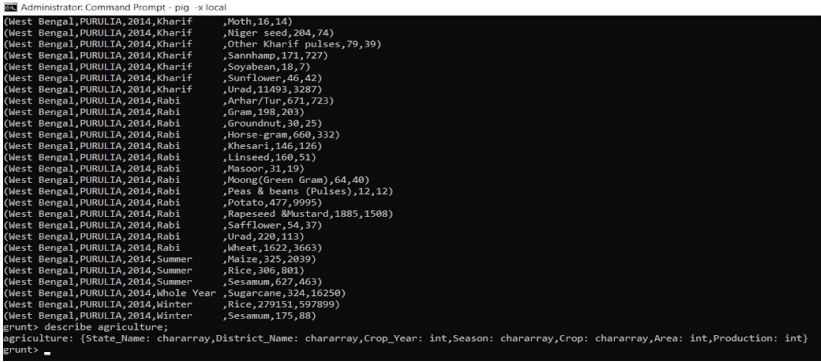
5.在本地模式下执行 PIG 查询
您可以按照这些书面查询使用 PIG 中的各种函数和运算符来分析数据集。在继续之前,您需要遵循上述所有步骤。
查询 1:明智地将所有记录分组。
此命令将按列 State_Name 对所有记录进行分组。
grunt > statewisecrop = GROUP agriculture BY State_Name;
grunt > DUMP statewisecrop;
grunt > DESCRIBE statewisecrop;
现在将查询结果存储在 CSV 文件中以便更好地理解。我们不得不提到对象的名称和需要存储的路径。
pathname -> 'F:/csv files/statewiseoutput'
grunt > STORE statewisecrop INTO ‘F:/csv files/statewiseoutput’;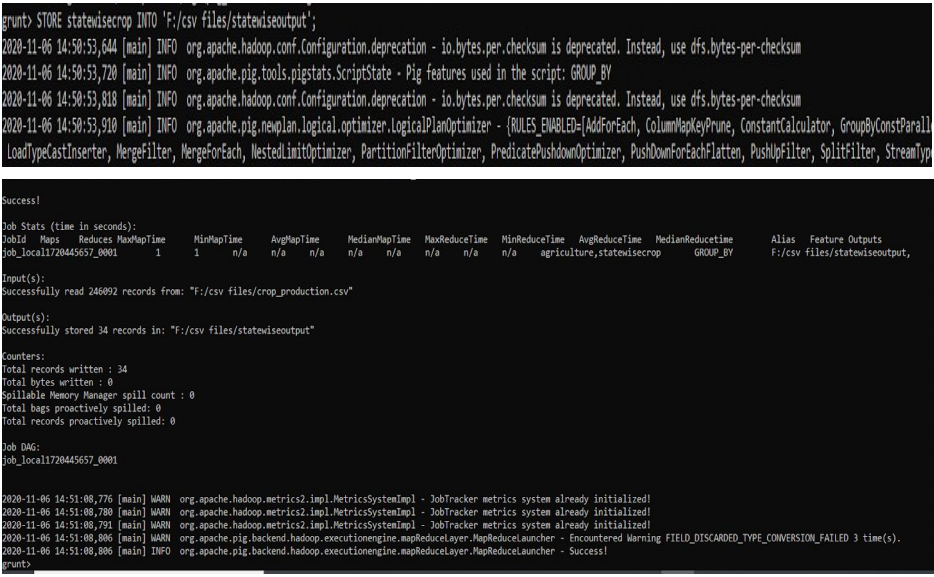
输出将在名为“part-r-00000”的文件中,需要将其重命名为“ part-r-00000.csv ”才能以 Excel 格式打开并使其可读。您将在我们在上述查询中提到的路径中找到此文件。就我而言,它位于路径“F:/csv files/statewiseoutput/”中。
输出文件将如下所示:

查询 1 输出的 CSV 文件
也可以在管理员模式下打开命令提示符查看raw文件,编写如下命令。
C:\Users\Adhiksha\ > Head -2 ‘F:\csv files\statewiseoutput\part-r-00000.csv’;此命令返回状态输出结果文件的前 2 条记录。看起来像这样。

查询编号 1 的输出
查询 2:生成总作物产量和面积
在上面的查询中,我们需要按 Crop type 分组,然后找到它们的 Productions 和 Area 的 SUM。
grunt > cropinfo = FOREACH( GROUP agriculture BY Crop )
GENERATE group AS Crop, SUM(agriculture.Area) as AreaPerCrop ,
SUM(agriculture.Production) as ProductionPerCrop;
grunt > DESCRIBE cropinfo;
grunt > STORE cropinfo INTO ‘F:/csv files/cropinfooutput’;输出将在名为“part-r-00000”的文件中,需要将其重命名为“part-r-00000.csv”才能以 Excel 格式打开并使其可读。
您可以通过在管理员模式下打开命令提示符并按如下方式运行命令来检查 csv 输出。
C:\Users > cat ‘F:/csv files/cropinfooutput/part-r-00000.csv’这将返回命令提示符上的所有输出。您可以看到我们在输出中有三列。
输出:
Crop ,
AreaperCrop ,
ProductionPerCrop.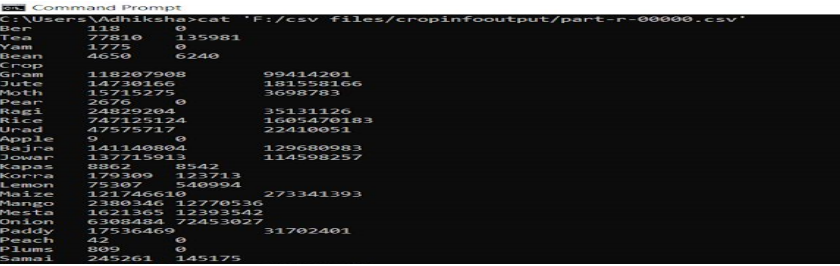
问题 3:大部分作物生长在一个季节和哪一年。
在这个查询中,我们需要按季节对作物进行分组并按字母顺序排列。此外,这将告诉我们在一个季节和一年中发现了哪些作物。
grunt > seasonalcrops = FOREACH (GROUP agriculture by Season ){
order_crops = ORDER agriculture BY Crop ASC;
GENERATE group AS Season , order_crops.(Crop) AS Crops;
};
grunt > DESCRIBE seasonalcrops;
grunt > STORE seasonalcrops INTO ‘F:/csv files/seasonaloutput;输出将在名为“part-r-00000”的文件中,需要将其重命名为“part-r-00000.csv”才能以 Excel 格式打开并使其可读。您可以通过在管理员模式下打开命令提示符并按如下方式运行命令来检查 csv 输出。
C:\Users > cat ‘F:/csv files/seasonaloutput/part-r-00000.csv’您可以通过打开文件来检查“part-r-00000.csv”的输出。您可以在第一行看到所有不同的季节,然后是所有作物及其生产年份。
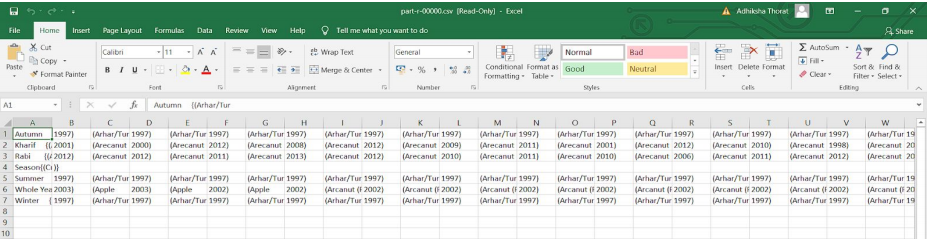
此查询编号 3 的输出
查询 4:2000 年后各区平均作物产量。
首先,我们需要按地区名称分组,然后找到总作物产量的平均值,但仅限于 2000 年之后。
grunt > averagecrops = FOREACH (GROUP agriculture by District_Name){
after_year = FILTER agriculture BY Crop_Year>2000;
GENERATE group AS District_Name , AVG(after_year.(Production)) AS
AvgProd;
};
grunt > DESCRIBE averagecrops;
grunt > STORE averagecrops INTO ‘F:/csv files/averagecrops;您可以通过打开文件来检查“part-r-00000.csv”的输出。该文件将包含两列。第一个具有所有不同的地区名称,第二个将具有 2000 年后每个地区所有作物的平均产量。
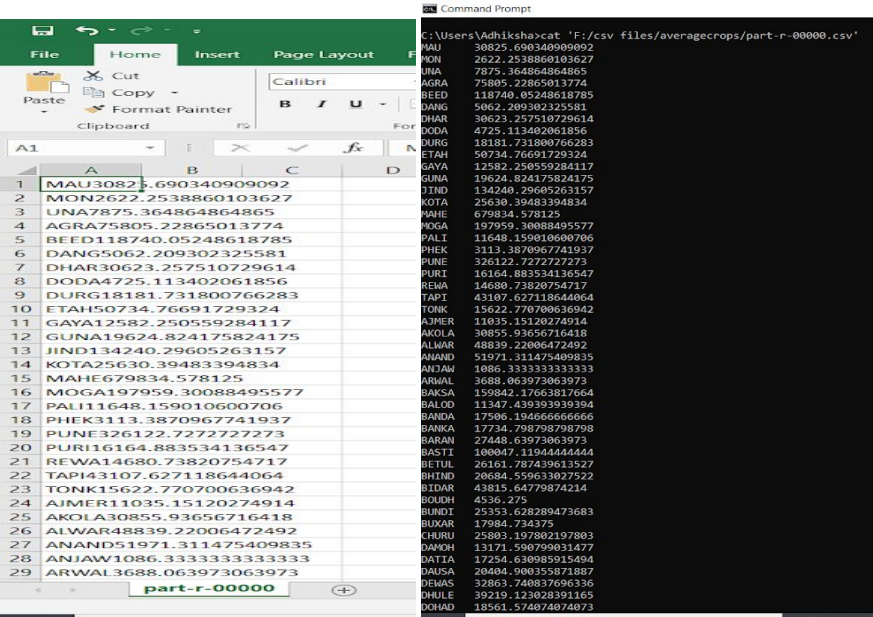
查询编号 4 的输出
问题 5:每个州产量最高的作物和详细信息。
首先,我们需要按状态名称对输入进行分组。然后遍历每个分组的记录,然后从每个状态中找到具有最高 Production 的 TOP 1 记录。
grunt > top_agri= GROUP agriculture BY State_Name;
grunt > data_top = FOREACH top_agri{
top = TOP(1, 6 , agriculture);
GENERATE top as Record;
}
grunt > DESCRIBE cropinfo;