Hive表为我们提供了以各种格式(如 CSV)存储数据的模式。 Hive提供了多种向表中添加数据的方法。我们可以在Hive使用 DML(Data Manipulation Language)查询来向表中导入或添加数据。也可以使用HDFS 命令直接将表放入 hive 中。如果我们在 MySQL、ORACLE、IBM DB2 等关系数据库中有数据,那么我们可以使用Sqoop在 Hadoop 和Hive之间有效地传输 PB 级数据。在本教程中,我们将使用Hive DML 查询将数据加载或插入到Hive表中。
要执行以下操作,请确保您的配置单元正在运行。以下是在本地系统上启动配置单元的步骤。
第 1 步:启动所有 Hadoop 守护进程
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons
第 2 步:从终端启动 hive
hive

在带有 DML 语句的 hive 中,我们可以通过两种不同的方式将数据添加到Hive表中。
- 使用插入命令
- 加载数据语句
1. 使用插入命令
句法:
INSERT INTO TABLE VALUES ();
例子:
要将数据插入表中,让我们创建一个名为student的表(默认情况下,hive 使用其默认数据库来存储 hive 表) 。
命令:
CREATE TABLE IF NOT EXISTS student(
Student_Name STRING,
Student_Rollno INT,
Student_Marks FLOAT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';

我们已经在Hive默认数据库中成功创建了学生表,分别具有Student_Name 、 Student_Rollno和Student_Marks属性。
现在,让我们使用 INSERT 查询将数据插入到该表中。
插入查询:
INSERT INTO TABLE student VALUES ('Dikshant',1,'95'),('Akshat', 2 , '96'),('Dhruv',3,'90');

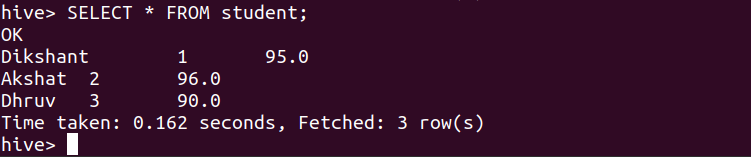
我们可以在下面的命令的帮助下检查学生表的数据。
SELECT * FROM student;
2.加载数据语句
Hive为我们提供了从本地文件系统或 HDFS 加载预先创建的表实体的功能。 LOAD DATA语句用于将数据加载到 hive 表中。
句法:
LOAD DATA [LOCAL] INPATH '' [OVERWRITE] INTO TABLE ;
笔记:
- LOCAL开关指定 我们正在加载的数据在我们的本地文件系统中可用。如果未使用LOCAL开关,则配置单元会将该位置视为 HDFS 路径位置。
- OVERWRITE 开关允许我们覆盖表数据。
让我们创建一个名为data.csv的 CSV(逗号分隔值)文件,因为我们在 hive 中创建表时提供了“,”作为字段终止符。出于演示目的,我们正在本地文件系统中的“ /home/dikshant/Documents”中创建此文件。
命令:
cd /home/dikshant/Documents // To change the directory
touch data.csv // use to create data.csv file
nano data.csv // nano is a linux command line editor to edit files
cat data.csv // cat is used to see content of file

在以下命令的帮助下将数据加载到学生配置单元表。
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/data.csv' INTO TABLE student;

借助下面的命令,让我们查看学生表内容以观察效果。
SELECT * FROM student;

我们可以观察到我们已经成功地将数据添加到学生表中。