Hadoop 是一个由 Apache 软件基金会监管的开源框架,它是用Java编写的,用于存储和处理具有商用硬件集群的庞大数据集。大数据主要有两个问题。第一个是存储如此大量的数据,第二个是处理存储的数据。由于数据的异质性,像 RDBMS 这样的传统方法是不够的。因此,Hadoop 是解决大数据问题的解决方案,即存储和处理具有一些额外功能的大数据。 Hadoop 主要有两个组件,分别是Hadoop 分布式文件系统 (HDFS)和另一个资源协商器 (YARN) 。
Hadoop 历史
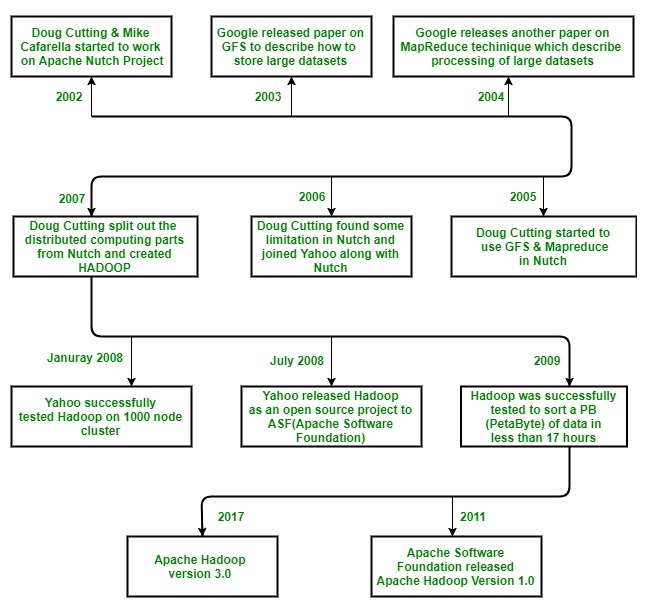
Hadoop 由Doug Cutting 和 Mike Cafarella于 2002 年开始,当时他们都开始致力于 Apache Nutch 项目。 Apache Nutch 项目是构建一个可以索引 10 亿个页面的搜索引擎系统的过程。在对 Nutch 进行大量研究后,他们得出的结论是,这样的系统将花费大约 50 万美元的硬件,加上每月大约 30,000 美元的运行成本,这是非常昂贵的。因此,他们意识到他们的项目架构不足以解决网络上数十亿页面的问题。因此,他们正在寻找一种可行的解决方案,既可以降低实施成本,又可以解决大型数据集的存储和处理问题。
2003年,他们看到一篇论文,描述了谷歌发布的分布式文件系统GFS(谷歌文件系统)的架构,用于存储大数据集。现在他们意识到这篇论文可以解决他们存储非常大的文件的问题,这些文件是由于网络爬行和索引过程而产生的。但是这篇论文只是解决了他们问题的一半。
2004 年,谷歌又发表了一篇关于MapReduce技术的论文,这是处理那些大型数据集的解决方案。现在,这篇论文是 Doug Cutting 和 Mike Cafarella 的 Nutch 项目的另一半解决方案。这两种技术(GFS 和 MapReduce)都在 Google 的白皮书中。谷歌没有实施这两种技术。 Doug Cutting 从他在 Apache Lucene(它是一个免费的开源信息检索软件库,最初由 Doug Cutting 于 1999 年用Java编写)的工作中知道,开源是将该技术传播给更多人的好方法。因此,他与 Mike Cafarella 一起开始在 Apache Nutch 项目中实施 Google 的技术(GFS 和 MapReduce)作为开源技术。
2005 年, Cutting 发现 Nutch 仅限于 20 到 40 个节点集群。他很快意识到两个问题:
(a)除非 Nutch 在更大的集群上可靠运行,否则它不会发挥其潜力
(b)只有两个人(Doug Cutting 和 Mike Cafarella)这看起来是不可能的。
Nutch 项目的工程任务比他想象的要大得多。因此,他开始在一家有兴趣投资于他们的努力的公司找到一份工作。他发现雅虎!.雅虎有一个庞大的工程师团队,他们渴望在这个项目上工作。
所以在 2006 年, Doug Cutting 和 Nutch 项目一起加入了雅虎。他想在雅虎的帮助下为世界提供一个开源、可靠、可扩展的计算框架。所以在雅虎,他首先将分布式计算部分从 Nutch 中分离出来,形成了一个新的项目 Hadoop(他给 Hadoop 取了名字,它是一个黄色玩具大象的名字,它是 Doug Cutting 的儿子拥有的。它很容易发音,而且是独特的词。 )现在他想让 Hadoop 能够在数千个节点上良好运行。于是有了 GFS 和 MapReduce,他开始研究 Hadoop。
2007 年,雅虎在 1000 个节点的集群上成功测试了 Hadoop 并开始使用它。
2008 年 1 月,雅虎将 Hadoop 作为开源项目发布给 ASF(Apache 软件基金会) 。 2008 年 7 月,Apache Software Foundation 成功地使用 Hadoop 测试了一个 4000 节点的集群。
2009 年, Hadoop 成功通过测试,可在不到 17 小时内对 PB (PetaByte) 数据进行排序,以处理数十亿次搜索并为数百万个网页编制索引。而Doug Cutting 离开了雅虎,加入了 Cloudera,完成了将 Hadoop 推广到其他行业的挑战。
2011年12 月, Apache 软件基金会发布了Apache Hadoop 1.0 版。
后来在 2013 年 8 月,版本 2.0.6 可用。
目前,我们有2017年12 月发布的Apache Hadoop 3.0 版。
让我们总结一下上面的历史: