Hadoop Streaming 是 Hadoop 自带的一个特性,它允许用户或开发人员使用各种不同的语言来编写 MapReduce 程序,如Python、C++、Ruby 等。它支持所有可以从标准输入读取并写入到标准输出的语言。我们将使用 Hadoop Streaming 实现Python ,并将观察它是如何工作的。我们将在Python实现字数计算来理解Hadoop Streaming。我们将创建mapper.py和reducer.py来执行 map 和 reduce 任务。
让我们创建一个文件,其中包含我们可以计算的多个单词。
步骤 1:创建一个名为word_count_data.txt的文件并向其中添加一些数据。
cd Documents/ # to change the directory to /Documents
touch word_count_data.txt # touch is used to create an empty file
nano word_count_data.txt # nano is a command line editor to edit the file
cat word_count_data.txt # cat is used to see the content of the file

第 2 步:创建一个实现映射器逻辑的mapper.py文件。它将从 STDIN 读取数据并将行拆分为单词,并将生成每个单词的输出及其单独的计数。
cd Documents/ # to change the directory to /Documents
touch mapper.py # touch is used to create an empty file
cat mapper.py # cat is used to see the content of the file
将以下代码复制到mapper.py文件中。
Python3
#!/usr/bin/env python
# import sys because we need to read and write data to STDIN and STDOUT
import sys
# reading entire line from STDIN (standard input)
for line in sys.stdin:
# to remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# we are looping over the words array and printing the word
# with the count of 1 to the STDOUT
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
print '%s\t%s' % (word, 1)Python3
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# read the entire line from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# slpiting the data on the basis of tab we have provided in mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)在上面的程序中#!被称为shebang,用于解释脚本。该文件将使用我们指定的命令运行。
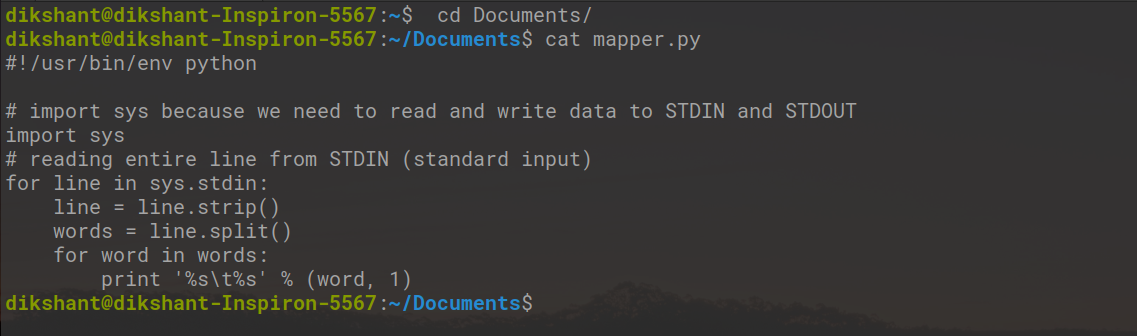
让我们在本地测试我们的mapper.py是否工作正常。
句法:
cat | python
命令(在我的情况下)
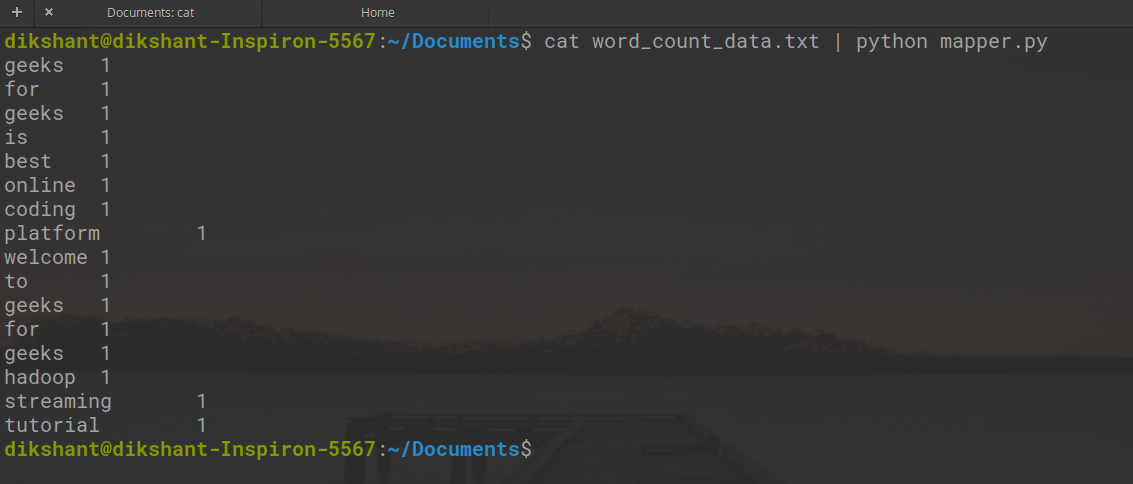
cat word_count_data.txt | python mapper.py
映射器的输出如下所示。
第 3 步:创建一个实现 reducer 逻辑的reducer.py文件。它将从 STDIN(标准输入)读取 mapper.py 的输出,并将聚合每个单词的出现并将最终输出写入 STDOUT。
cd Documents/ # to change the directory to /Documents
touch reducer.py # touch is used to create an empty file
蟒蛇3
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# read the entire line from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# slpiting the data on the basis of tab we have provided in mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
现在让我们使用 mapper.py 检查我们的减速器代码 reducer.py 是否在以下命令的帮助下正常工作。
cat word_count_data.txt | python mapper.py | sort -k1,1 | python reducer.py

我们可以看到我们的减速器在我们的本地系统中也运行良好。
第 4 步:现在让我们使用以下命令启动所有 Hadoop 守护进程。
start-dfs.sh
start-yarn.sh

现在在根目录下的 HDFS 中创建一个目录word_count_in_python ,该目录将使用以下命令存储我们的word_count_data.txt文件。
hdfs dfs -mkdir /word_count_in_python
在copyFromLocal命令的帮助下,将word_count_data.txt复制到我们 HDFS 中的此文件夹中。
将文件从本地文件系统复制到 HDFS 的语法如下:
hdfs dfs -copyFromLocal /path 1 /path 2 .... /path n /destination
实际命令(在我的情况下)
hdfs dfs -copyFromLocal /home/dikshant/Documents/word_count_data.txt /word_count_in_python

现在我们的数据文件已经成功发送到HDFS。我们可以使用以下命令或手动访问我们的 HDFS 来检查它是否发送。
hdfs dfs -ls / # list down content of the root directory
hdfs dfs -ls /word_count_in_python # list down content of /word_count_in_python directory

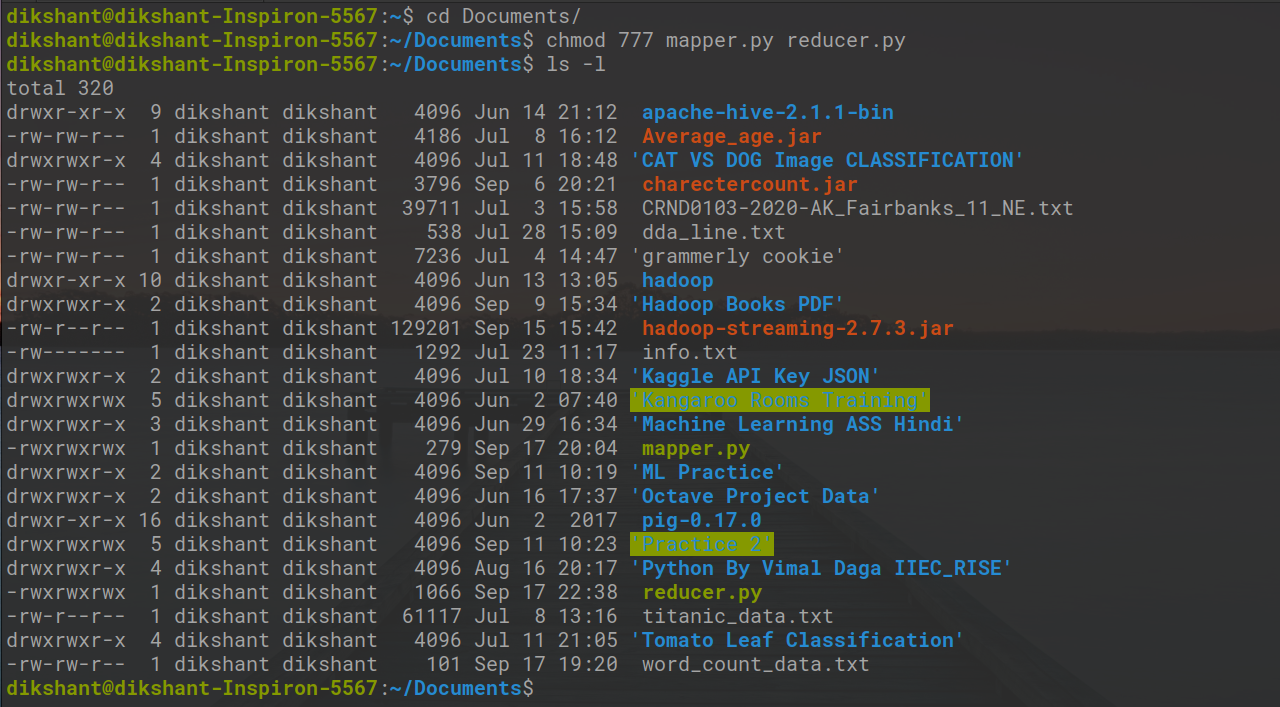
让我们在以下命令的帮助下为我们的mapper.py和reducer.py授予可执行权限。
cd Documents/
chmod 777 mapper.py reducer.py # changing the permission to read, write, exectute for user, group and others
在下图中,然后我们可以观察到我们已经更改了文件权限。
第 5 步:现在从此链接下载最新的hadoop-streaming jar文件。然后把这个 Hadoop,-streaming jar 文件放到一个你可以轻松访问的地方。就我而言,我将它放在/Documents文件夹中,其中存在mapper.py和reducer.py文件。
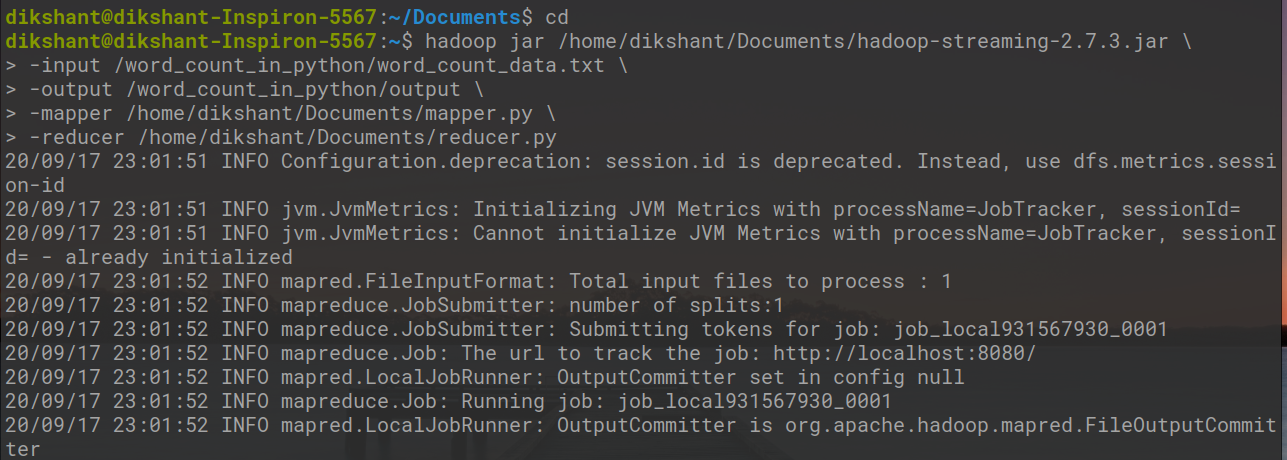
现在让我们在 Hadoop 流实用程序的帮助下运行我们的Python文件,如下所示。
hadoop jar /home/dikshant/Documents/hadoop-streaming-2.7.3.jar \
> -input /word_count_in_python/word_count_data.txt \
> -output /word_count_in_python/output \
> -mapper /home/dikshant/Documents/mapper.py \
> -reducer /home/dikshant/Documents/reducer.py
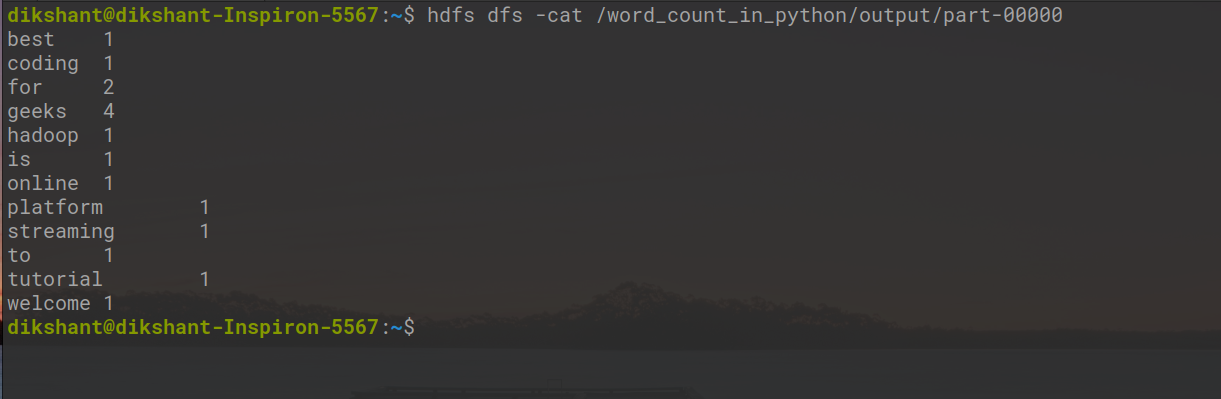
在上面的命令中-output , 我们将在 HDFS 中指定我们希望存储输出的位置。因此,在我的情况下,让我们检查位于/word_count_in_python/output/part-00000位置的输出文件中的输出。我们可以通过手动查看 HDFS 中的位置或在 cat 命令的帮助下检查结果,如下所示。
hdfs dfs -cat /word_count_in_python/output/part-00000
我们可以与 Hadoop Streaming 一起使用的基本选项
|
Option |
Description |
|---|---|
| -mapper | The command to be run as the mapper |
| -reducer | The command to be run as the reducer |
| -input | The DFS input path for the Map step |
| -output | The DFS output directory for the Reduce step |