- Python Web爬网-简介
- Python Web爬网-简介(1)
- 讨论Python Web爬网
- 讨论Python Web爬网(1)
- Python Web爬网-处理文本
- Python Web爬网-数据提取(1)
- Python Web爬网-数据提取
- Python Web爬网-有用的资源
- Python Web爬网-有用的资源(1)
- Python Web爬网-动态网站(1)
- Python Web爬网-动态网站
- Python Web爬网-数据处理(1)
- Python Web爬网-数据处理
- Python Web爬网-使用爬虫进行测试(1)
- Python Web爬网-使用爬虫进行测试
- Python Web爬网-基于表单的网站
- Python Web爬网-基于表单的网站(1)
- Python Web爬网-处理验证码
- Python Web爬网-处理验证码(1)
- 使用 c# (1)
- c++的使用(1)
- 使用 c#9 - C# (1)
- == python的使用(1)
- 在 python 中使用库(1)
- 使用 c#9 - C# 代码示例
- c++代码示例的使用
- 使用 c# 代码示例
- 如何使用 - C++ (1)
- 如何使用和在c++中(1)
📅 最后修改于: 2020-10-28 01:32:30 🧑 作者: Mango
使用Python网页搜刮
什么是网页抓取?
Web Scraping是一种从多个网站提取大量数据的技术。术语“抓取”是指从其他来源(网页)获取信息并将其保存到本地文件中。例如:假设您正在开发一个名为“电话比较网站”的项目,在该项目中,您需要手机的价格,等级和型号名称才能在不同的手机之间进行比较。如果您通过检查各个站点来收集这些详细信息,则将花费大量时间。在这种情况下,Web抓取起着重要的作用,通过编写几行代码,您可以获得期望的结果。
Web爬网以非结构化格式从网站提取数据。它有助于收集这些非结构化数据并将其转换为结构化形式。
初创企业更喜欢使用网络抓取,因为这是一种无需与数据销售公司建立任何合作关系即可获取大量数据的廉价有效方式。
Web报废合法吗?
此处出现的问题是,Web报废是否合法。答案是某些网站在合法使用时允许使用。 Web抓取只是您可以正确或错误使用它的工具。
如果有人试图剪贴非公开数据,则网络剪贴是非法的。非公开数据并非所有人都能获得;如果您尝试提取此类数据,则违反法律条款。
有多种工具可用于从网站抓取数据,例如:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
为什么要进行网络报废?

正如我们上面讨论的,网络抓取用于从网站提取数据。但是我们应该知道如何使用原始数据。原始数据可以用于各个领域。让我们看一下网络抓取的用法:
- 动态价格监控
它被广泛用于从多个在线购物网站收集数据,比较产品价格并做出有利可图的定价决策。使用网络报废数据进行价格监控可以使公司了解市场状况并促进动态定价。这样可以确保他们始终领先于其他公司。
- 市场调查
eb报废非常适合市场趋势分析。它正在获得对特定市场的见识。大型组织需要大量数据,Web抓取为数据提供了一定程度的可靠性和准确性。
- 电子邮件收集
许多公司使用个人电子邮件数据进行电子邮件营销。他们可以针对特定的受众群体进行营销。
- 新闻和内容监控
一个新闻周期可以对您的业务产生卓越的影响或真正的威胁。如果您的公司依赖于组织的新闻分析,则它经常出现在新闻中。因此,网络抓取为监视和解析最关键的故事提供了最终的解决方案。新闻文章和社交媒体平台可以直接影响股票市场。
- 社交媒体报废
在从Twitter,Facebook和Instagram等社交媒体网站提取数据以查找趋势主题方面,Web爬网起着至关重要的作用。
- 研究与开发
从网站上删除了大量数据,例如常规信息,统计数据和温度,然后对其进行分析并用于进行调查或研发。
为什么要使用Python进行Web爬虫?
还有其他流行的编程语言,但是为什么我们选择Python不是其他用于网络抓取的编程语言?下面我们描述了Python的功能列表,这些功能使Web爬网成为最有用的编程语言。
- 动态类型
在Python,我们不需要为变量定义数据类型。我们可以在任何需要的地方直接使用该变量。这样可以节省时间,并使任务更快。 Python定义了其类以标识变量的数据类型。
- 大量库
Python附带了广泛的库,例如NumPy,Matplotlib,Pandas,Scipy等,这些库提供了可灵活用于各种用途的库。它适用于几乎每个新兴领域,也适用于Web抓取以提取数据和进行操作。
- 更少的代码
网页剪贴的目的是节省时间。但是,如果您花费更多时间编写代码怎么办?这就是我们使用Python的原因,因为Python可以用几行代码执行任务。
- 开源社区
Python是开源的,这意味着每个人都可以免费使用。它拥有全球最大的社区之一,如果您陷入Python代码的任何地方,都可以在其中寻求帮助。
网页抓取的基本知识
网页抓取由两部分组成:网页抓取工具和网页抓取工具。简而言之,网络爬虫是一匹马,而刮板是战车。搜寻器引导抓取器并提取所需的数据。让我们了解一下Web抓取的两个组成部分:
- The crawler
网络爬虫通常称为“蜘蛛”。这是一种人工智能技术,可浏览互联网以建立索引并通过给定的链接搜索内容。它搜索程序员要求的相关信息。
网络抓取工具是一种专用工具,旨在快速有效地从多个网站提取数据。 Web抓取工具的设计和复杂程度因项目而异。
Web报废如何工作?
这些是执行Web抓取的以下步骤。让我们了解一下网络抓取的工作原理。
步骤-1:找到您要抓取的网址
首先,您应该根据您的项目了解数据需求。网页或网站包含大量信息。因此,仅废弃相关信息。简而言之,开发人员应该熟悉数据需求。
步骤-2:检查页面
数据以原始HTML格式提取,必须仔细分析并减少原始数据带来的噪音。在某些情况下,数据可以像名称和地址一样简单,也可以像高维天气和股市数据一样复杂。
步骤-3:编写代码
编写代码以提取信息,提供相关信息并运行代码。
步骤-4:将数据存储在文件中
将该信息以必需的csv,xml和JSON文件格式存储。
Web抄袭入门
Python有大量的库,并且还为Web抓取提供了非常有用的库。让我们了解Python所需的库。
用于网络抓取的库
- Selenium -Selenium是一个开源的自动化测试库。它用于检查浏览器活动。要安装此库,请在终端中键入以下命令。
pip install selenium
注意-最好使用PyCharm IDE。

- Pandas
Pandas库用于数据处理和分析。它用于提取数据并以所需格式存储。
- BeautifulSoup
让我们详细了解BeautifulSoup库。
安装BeautifulSoup
您可以通过键入以下命令来安装BeautifulSoup:
pip install bs4
安装解析器
BeautifulSoup支持HTML解析器和几个第三方Python解析器。您可以根据自己的依赖性安装它们中的任何一个。 BeautifulSoup的解析器列表如下:
| Parser | Typical usage |
|---|---|
| Python’s html.parser | BeautifulSoup(markup,”html.parser”) |
| lxml’s HTML parser | BeautifulSoup(markup,”lxml”) |
| lxml’s XML parser | BeautifulSoup(markup,”lxml-xml”) |
| Html5lib | BeautifulSoup(markup,”html5lib”) |
我们建议您安装html5lib解析器,因为它非常适合新版本的Python,或者您可以安装lxml解析器。
在终端中键入以下命令:
pip install html5lib

BeautifulSoup用于将复杂的HTML文档转换为复杂的Python对象树。但是有一些主要使用的基本类型对象:
- 标签
Tag对象对应于XML或HTML原始文档。
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
输出:
标签包含许多属性和方法,但是标签最重要的功能是名称和属性。
- Name
每个标签都有一个名称,可以通过.name进行访问:
tag.name
- Attributes
标签可以具有任意数量的属性。标签具有属性“ id”,其值为“ boldest”。我们可以通过将标签视为字典来访问标签的属性。
tag[id]
我们可以添加,删除和修改标签的属性。可以通过使用标签作为字典来完成。
# add the element
tag['id'] = 'verybold'
tag['another-attribute'] = 1
tag
# delete the tag
del tag['id']
- 多值属性
在HTML5中,有些属性可以具有多个值。类(由多个CSS组成)是最常见的多值属性。其他属性是rel,rev,accept-charset,header和accesskey。
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- NavigableString
BeautifulSoup中的字符串引用标记内的文本。 BeautifulSoup使用NavigableString类包含这些文本位。
tag.string
# u'Extremely bold'
type(tag.string)
#
字符串是不可变的,表示无法编辑。但是可以使用replace_with()将其替换为另一个字符串。
tag.string.replace_with("No longer bold")
tag
在某些情况下,如果要在BeautifulSoup之外使用NavigableString,则unicode()可以将其转换为普通的Python Unicode字符串。
- BeautifulSoup对象
BeautifulSoup对象整体上表示完整的已解析文档。在许多情况下,我们可以将其用作Tag对象。这意味着它支持导航树和搜索树中描述的大多数方法。
doc=BeautifulSoup("输出:
?xml version="1.0" encoding="utf-8"?>
# Web剪贴示例:
让我们以一个示例为例,通过从网页中提取数据并检查整个页面来实际了解爬网。
首先,在Wikipedia上打开您喜欢的页面并检查整个页面,在从网页中提取数据之前,应确保您的要求。考虑以下代码:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests.get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
输出:
The object type
Convert the object into:
在以下代码行中,我们将按类名称提取网页的所有标题。在这里,前端知识在检查网页中起着至关重要的作用。
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
输出:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,
Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,
Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,
Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,
Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,
Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,
Free and open-source software,Proprietary software with free and open-source editions,Proprietary
software,Journals,Conferences,See also,References,Further reading,External links,
在上面的代码中,我们导入了bs4并请求了库。在第三行中,我们创建了一个res对象,以将请求发送到网页。如您所见,我们已经从网页中提取了所有标题。

维基百科学习网页
让我们理解另一个例子。我们将对URL进行GET请求,并使用BeautifulSoup和Python内置的“ html5lib”解析器创建一个解析Tree对象(汤)。
在这里,我们将废弃给定链接的网页(https://www.javatpoint.com/)。考虑以下代码:
following code:
# importing the libraries
from bs4 import BeautifulSoup
import requests
url="https://www.javatpoint.com/"
# Make a GET request to fetch the raw HTML content
html_content = requests.get(url).text
# Parse the html content
soup = BeautifulSoup(html_content, "html5lib")
print(soup.prettify()) # print the parsed data of html
上面的代码将显示javatpoint主页的所有html代码。
使用BeautifulSoup对象(即汤),我们可以收集所需的数据表。让我们使用汤对象print一些有趣的信息:
- 让我们print网页的标题。
print(soup.title)
输出:它将给出如下输出:
Tutorials List - Javatpoint
- 在上面的输出中,HTML标签包含在标题中。如果要文本不带标签,则可以使用以下代码:
print(soup.title.text)
输出:它将给出如下输出:
Tutorials List - Javatpoint
- 我们可以在页面上获得整个链接及其属性,例如href,title及其内部Text。考虑以下代码:
for link in soup.find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
输出:它将print所有链接及其属性。这里我们显示其中一些:
href is: https://www.facebook.com/javatpoint
Inner Text is:
The title is: None
href is: https://twitter.com/pagejavatpoint
Inner Text is:
The title is: None
href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg
Inner Text is:
The title is: None
href is: https://javatpoint.blogspot.com
Inner Text is: Learn Java
Title is: None
href is: https://www.javatpoint.com/java-tutorial
Inner Text is: Learn Data Structures
Title is: None
href is: https://www.javatpoint.com/data-structure-tutorial
Inner Text is: Learn C Programming
Title is: None
href is: https://www.javatpoint.com/c-programming-language-tutorial
Inner Text is: Learn C++ Tutorial
演示:从Flipkart网站抓取数据
在此示例中,我们将从流行的电子商务网站之一Flipkart中删除手机的价格,等级和型号名称。以下是完成此任务的先决条件:
先决条件:
- 的Python 2.x或Python 3.x都有硒,BeautifulSoup,熊猫库安装。
- Google-Chrome浏览器
- 报废解析器,例如html.parser,xlml等。
步骤-1:找到要剪贴的网址
第一步是找到要剪贴的URL。在这里,我们从活动卡中提取手机详细信息。此页面的网址为https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off。
步骤-2:检查页面
由于数据通常包含在标签中,因此有必要仔细检查页面。因此,我们需要检查以选择所需的标签。要检查页面,请右键单击该元素,然后单击“检查”。
步骤-3:找到要提取的数据
提取分别包含在“ div”标签中的价格,名称和评分。
步骤-4:编写代码
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
输出:
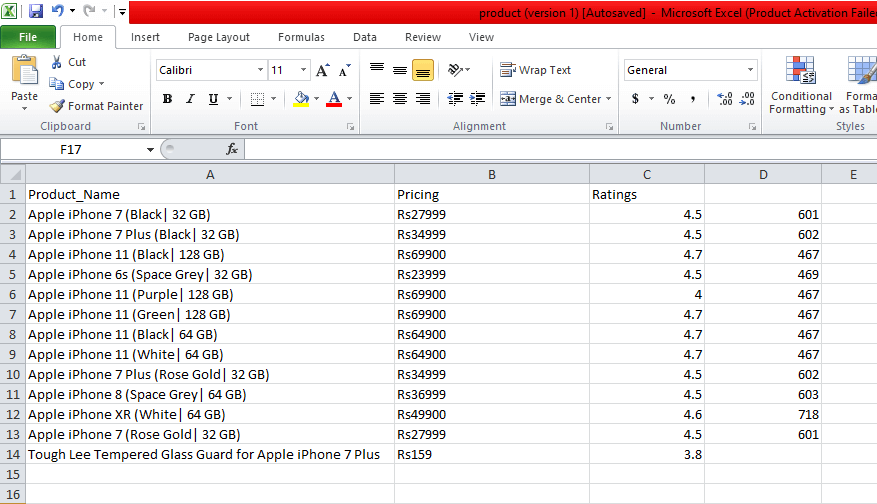
我们将iPhone的详细信息报废,并将这些详细信息保存在CSV文件中,如您在输出中看到的那样。在上面的代码中,我们对几行代码进行了注释,以进行测试。您可以删除这些注释并观察输出。
在本教程中,我们讨论了Web爬网的所有基本概念,并描述了来自领先的在线电子商务网站flipkart的示例爬网。