📌 相关文章
- Python|熊猫 Dataframe.sample()
- Python|熊猫 Dataframe.sample()(1)
- python中的R sample()函数(1)
- python代码示例中的R sample()函数
- Python Pandas DataFrame
- Python Pandas DataFrame(1)
- Lodash _.sample() 方法(1)
- Lodash _.sample() 方法
- random.sample python (1)
- random.sample - Python (1)
- 红宝石 |数组 sample()函数
- 红宝石 |数组 sample()函数(1)
- Python中的 pandas.DataFrame.T()函数(1)
- Python中的 pandas.DataFrame.T()函数
- random.sample - Python 代码示例
- random.sample python 代码示例
- 计算 Pandas Dataframe 中的值(1)
- 计算 Pandas Dataframe 中的值
- 用 Pandas 中另一个 DataFrame 的值替换 DataFrame 的值
- Python| random.sample()函数
- Python| random.sample()函数(1)
- Underscore.js _.sample函数
- Underscore.js _.sample函数(1)
- 如何从 Pandas DataFrame 创建饼图?
- 如何从 Pandas DataFrame 创建饼图?(1)
- Python | Pandas 数据 DataFrame
- Python | Pandas 数据 DataFrame(1)
- 魔杖 sample()函数- Python
- 魔杖 sample()函数- Python(1)
📜 Pandas DataFrame.sample()
📅 最后修改于: 2020-10-29 02:14:51 🧑 作者: Mango
Pandas Dataframe.sample()
Pandas sample()用于从DataFrame中随机选择行和列。如果要从大量数据集构建模型,则必须随机选择通过函数样本完成的较小数据样本。
句法
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
参量
- n:这是一个可选参数,由整数值组成,并定义生成的随机行的数量。
- frac:它也是一个可选参数,由float值组成,并返回float值*数据帧值的长度。不能与参数n一起使用。
- replace:由布尔值组成。如果为true,则返回带有替换的样本。替换的默认值为false。
weights:它也是一个可选参数,由类似于str或ndarray的参数组成。默认值“无“导致相等的概率加权。如果正在通过系列赛;它将与索引上的目标对象对齐。在采样对象中找不到的权重索引值将被忽略,而在采样对象中没有权重的索引值将被分配零权重。如果在轴= 0时传递了DataFrame,则返回0。它将接受列的名称。如果权重是系列;然后,权重必须与被采样轴的长度相同。如果权重不等于1;它将标准化为1的总和。权重列中的缺失值被视为零。权重栏中不允许无穷大。- random_state:它也是一个可选参数,由整数或numpy.random.RandomState组成。如果值为int,则为随机数生成器或numpy RandomState对象设置种子。
- axis:它也是由整数或字符串值组成的可选参数。 0或“行“和1或“列”。
返回值
它返回与调用者相同类型的新对象,其中包含从调用者对象中随机采样的n个项目。
例1
import pandas as pd
info = pd.DataFrame({'data1': [2, 4, 8, 0],
'data2': [2, 0, 0, 0],
'data3': [10, 2, 1, 8]},
index=['John', 'Parker', 'Smith', 'William'])
info
info['data1'].sample(n=3, random_state=1)
info.sample(frac=0.5, replace=True, random_state=1)
info.sample(n=2, weights='data3', random_state=1)
输出量
data1 data2 data3
John 2 2 10
William 0 0 8
例2
在此示例中,我们获取一个csv文件,并使用示例从DataFrame中提取随机行。
名为aa的csv文件,其中包含以下数据集:
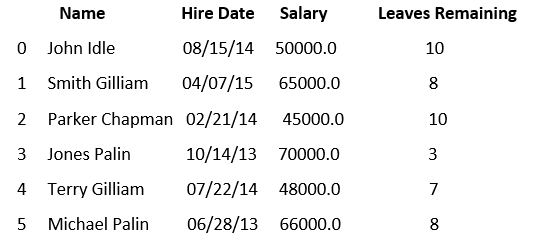
让我们编写一个代码,从上述数据集中提取随机行:
# importing pandas package
import pandas as pd
# define data frame from csv file
data = pd.read_csv("aa.csv")
# randomly select one row
row1 = data.sample(n = 1)
# display row
row1
# randomly select another row
row2 = data.sample(n = 2)
# display row
row2
输出量
Name Hire Date Salary Leaves Remaining
2 Parker Chapman 02/21/14 45000.0 10
5 Michael Palin 06/28/13 66000.0 8