计算 Pandas Dataframe 中的值
在本文中,我们将计算 Pandas 数据框中的值。首先,我们将创建一个数据框,然后我们将计算不同属性的值。
Syntax: DataFrame.count(axis=0, level=None, numeric_only=False)
Parameters:
- axis {0 or ‘index’, 1 or ‘columns’}: default 0 Counts are generated for each column if axis=0 or axis=’index’ and counts are generated for each row if axis=1 or axis=”columns”.
- level (nt or str, optional): If the axis is a MultiIndex, count along a particular level, collapsing into a DataFrame. A str specifies the level name.
- numeric_only (boolean, default False): It includes only int, float or boolean value.
Returns: It returns count of non-null values and if level is used it returns dataframe
循序渐进的方法:
第 1 步:导入库。
Python3
# importing libraries
import numpy as np
import pandas as pdPython3
# Creating dataframe with
# some missing values
NaN = np.nan
dataframe = pd.DataFrame({'Name': ['Shobhit', 'Vaibhav',
'Vimal', 'Sourabh',
'Rahul', 'Shobhit'],
'Physics': [11, 12, 13, 14, NaN, 11],
'Chemistry': [10, 14, NaN, 18, 20, 10],
'Math': [13, 10, 15, NaN, NaN, 13]})
display(dataframe)Python3
# using dataframe.count()
# to count all values
dataframe.count()Python3
# we can pass either axis=1 or
# axos='columns' to count with respect to row
print(dataframe.count(axis = 1))
print(dataframe.count(axis = 'columns'))Python3
# it will give the count
# of individual columns count of null values
print(dataframe.isnull().sum())
# it will give the total null
# values present in our dataframe
print("Total Null values count: ",
dataframe.isnull().sum().sum())Python3
# count of student with greater
# than 11 marks in physics
print("Count of students with physics marks greater than 11 is->",
dataframe[dataframe['Physics'] > 11]['Name'].count())
# resultant of above dataframe
dataframe[dataframe['Physics']>11]Python3
# Count of students whose physics marks
# are greater than 10,chemistry marks are
# greater than 11 and math marks are greater than 9.
print("Count of students ->",
dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)]['Name'].count())
# dataframe of above result
dataframe[(dataframe['Physics'] > 10 ) &
(dataframe['Chemistry'] > 11 ) &
(dataframe['Math'] > 9 )]Python3
# importing Libraries
import pandas as pd
import numpy as np
# Creating dataframe using dictionary
NaN = np.nan
dataframe = pd.DataFrame({'Name': ['Shobhit', 'Vaibhav',
'Vimal', 'Sourabh',
'Rahul', 'Shobhit'],
'Physics': [11, 12, 13, 14, NaN, 11],
'Chemistry': [10, 14, NaN, 18, 20, 10],
'Math': [13, 10, 15, NaN, NaN, 13]})
print("Created Dataframe")
print(dataframe)
# finding Count of all columns
print("Count of all values wrt columns")
print(dataframe.count())
# Count according to rows
print("Count of all values wrt rows")
print(dataframe.count(axis=1))
print(dataframe.count(axis='columns'))
# count of null values
print("Null Values counts ")
print(dataframe.isnull().sum())
print("Total null values",
dataframe.isnull().sum().sum())
# count of student with greater
# than 11 marks in physics
print("Count of students with physics marks greater than 11 is->",
dataframe[dataframe['Physics'] > 11]['Name'].count())
# resultant of above dataframe
print(dataframe[dataframe['Physics'] > 11])
print("Count of students ->",
dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)]['Name'].count())
print(dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)])第 2 步:创建数据框
蟒蛇3
# Creating dataframe with
# some missing values
NaN = np.nan
dataframe = pd.DataFrame({'Name': ['Shobhit', 'Vaibhav',
'Vimal', 'Sourabh',
'Rahul', 'Shobhit'],
'Physics': [11, 12, 13, 14, NaN, 11],
'Chemistry': [10, 14, NaN, 18, 20, 10],
'Math': [13, 10, 15, NaN, NaN, 13]})
display(dataframe)
输出:
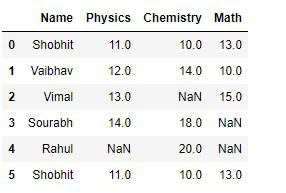
创建数据框
第 3 步:在这一步中,我们只是简单地使用.count()函数来计算不同列的所有值。
蟒蛇3
# using dataframe.count()
# to count all values
dataframe.count()
输出:
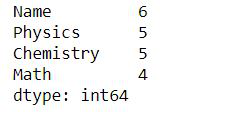
我们可以看到计数值存在差异,因为我们有缺失值。 Name 列中有 5 个值,物理和化学中有 4 个值,数学中有 3 个值。在这种情况下,它使用带有默认值的参数。
第 4 步:如果我们想计算关于行的所有值,那么我们必须传递轴 = 1 或“列”。
蟒蛇3
# we can pass either axis=1 or
# axos='columns' to count with respect to row
print(dataframe.count(axis = 1))
print(dataframe.count(axis = 'columns'))
输出:

相对于行计数
第 5 步:现在,如果我们想对数据框中的空值进行计数。
蟒蛇3
# it will give the count
# of individual columns count of null values
print(dataframe.isnull().sum())
# it will give the total null
# values present in our dataframe
print("Total Null values count: ",
dataframe.isnull().sum().sum())
输出:
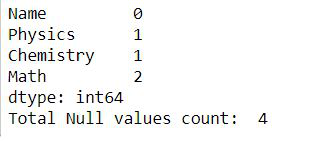
第 6 步: 。一些使用.count()的例子
现在我们要计算物理分数大于 11 的学生人数。
蟒蛇3
# count of student with greater
# than 11 marks in physics
print("Count of students with physics marks greater than 11 is->",
dataframe[dataframe['Physics'] > 11]['Name'].count())
# resultant of above dataframe
dataframe[dataframe['Physics']>11]
输出:
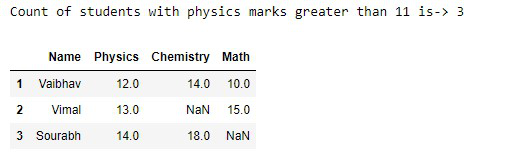
物理>11
物理成绩大于10、化学成绩大于11、数学成绩大于9的学生人数。
蟒蛇3
# Count of students whose physics marks
# are greater than 10,chemistry marks are
# greater than 11 and math marks are greater than 9.
print("Count of students ->",
dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)]['Name'].count())
# dataframe of above result
dataframe[(dataframe['Physics'] > 10 ) &
(dataframe['Chemistry'] > 11 ) &
(dataframe['Math'] > 9 )]
输出:
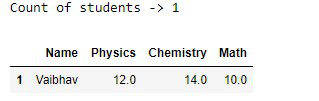
物理>10,化学>11,数学>9
下面是完整的实现:
蟒蛇3
# importing Libraries
import pandas as pd
import numpy as np
# Creating dataframe using dictionary
NaN = np.nan
dataframe = pd.DataFrame({'Name': ['Shobhit', 'Vaibhav',
'Vimal', 'Sourabh',
'Rahul', 'Shobhit'],
'Physics': [11, 12, 13, 14, NaN, 11],
'Chemistry': [10, 14, NaN, 18, 20, 10],
'Math': [13, 10, 15, NaN, NaN, 13]})
print("Created Dataframe")
print(dataframe)
# finding Count of all columns
print("Count of all values wrt columns")
print(dataframe.count())
# Count according to rows
print("Count of all values wrt rows")
print(dataframe.count(axis=1))
print(dataframe.count(axis='columns'))
# count of null values
print("Null Values counts ")
print(dataframe.isnull().sum())
print("Total null values",
dataframe.isnull().sum().sum())
# count of student with greater
# than 11 marks in physics
print("Count of students with physics marks greater than 11 is->",
dataframe[dataframe['Physics'] > 11]['Name'].count())
# resultant of above dataframe
print(dataframe[dataframe['Physics'] > 11])
print("Count of students ->",
dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)]['Name'].count())
print(dataframe[(dataframe['Physics'] > 10) &
(dataframe['Chemistry'] > 11) &
(dataframe['Math'] > 9)])
输出:
