编译器设计中的活力分析
活力分析由一种指定的技术组成,该技术被实施以优化给定代码的寄存器空间分配,并促进死代码消除过程。由于任何机器都有有限数量的寄存器来保存正在使用或操作的变量或数据,因此需要平衡内存的有效分配以降低成本并使机器能够处理复杂的代码和相当数量的变量同时进行。该过程是在编译器本身编译输入代码期间执行的。
实时变量:一个变量在程序编译过程中的任何时刻都是实时的,如果它的值被用于处理计算作为当时算术运算的评估,或者它持有一个将被使用的值将来不会在任何中间步骤重新定义变量。
有效范围:变量的有效范围定义为变量有效的代码部分。变量的有效范围可能是连续的或分布在代码的不同部分。这意味着一个变量可能会在某个瞬间生效,而在接下来的某个时间里会死掉,并且可能会在某个部分再次生效。
Liveliness Algorithm is used to evaluate the liveliness of each variable at each step. If one or more variables are live during the execution of a statement, the algorithm adds the evaluation to final result and repeats the same procedure for next statement. The output of the algorithm is further used to analyse the live range of variables and if any two variables are not live simultaneously at any instant of time, they share a common register. Hence, as a result, the available space is utilised effectively which is the motivation behind the algorithm.
基本概念源于这样一个事实,即对于一些临时变量,具有不相交生存范围的变量可以在需要时相应地放入特定寄存器中。为了保证一个寄存器对多个变量的适当分配,按照代码,引入了Liveliness Algorithm和Live Variable的概念。
使用的术语:
一些关键术语如下所述:
1.控制流图:控制流图被描述为在解析过程中通过有向图对程序进行流控制的图形表示形式。控制流图(CFG)的每个节点表示单个语句或一组语句,图的每个有向边表示给定代码的控制流。
请注意,对于控制流图:
出边指向后继节点。
succ[n] : It is the set of all successors of node 'n'.传入边来自前任节点。
pred[n] : It is the set of all predecessors of node 'n'.2. 数据流分析:仅通过查看和分析静态代码来提取有关给定程序的关键信息并了解其动态行为的过程。
3.基本块:收集活跃度信息的过程是一种数据流分析形式,在控制流图上运行,其中每个语句通常被认为是不同的 基本块。
It is important to note that liveliness is a property of a variable which flows through and around the directed edges of the control flow graph.
4. 定义变量:赋值表达式定义了一个变量,比如说v ,其中一个值被分配给v 。
- def(v):它被定义为控制流图中定义了'v'的所有节点的集合。
- def[n]:定义为'n'定义的变量集合,其中'n'是控制流图中的一个节点,'v'是一个变量。
5. 使用变量:在任意数量的表达式中每次出现v都被认为是使用v 的值,用于每个使用“v”值的语句。
- use(v):定义为控制流图中使用'v'的所有节点的集合,并且
- use[n]:它是'n'中使用的变量集,其中'n'是控制流图中的一个节点,'v'是一个变量。
Note that use[n] and def[n] for a given node, are both independent of the control flow and hence are constants for each node, irrespective of the iterations.
6. 实时:如果存在从边缘“e”到使用“v”的有向路径不通过任何 def(v),则变量“v”在边缘“e”上有效。
7. Live-In:如果变量“v”在节点“n”上存在,则变量“v”在 n 的任何入边上存在。
8. 活出:如果变量“v”位于节点“n”的任何一个出边上,则该变量“v”在节点“n”上活出。
为了评估 Live-In 和 Live-Out,我们定义
-> in[n]: As set of all the variables live-in at 'n' and
-> out[n]: As set of all the variables live-out at 'n',
where both in[n] and out[n] are initialised to NULL.笔记:
1.如果在某个节点中存在的程序语句中使用了变量,则该变量在该节点中存在。该定义表示为以下表达式:
v ∈ use[n] ⇒ v live-in at n2.一般情况下,我们假设所有的变量都已经被预先初始化。此外,如果一个变量在给定节点处存在,那么它在所有前导节点处都存在,被定向到 CFG 中的节点。
v live-in at n ⇒ v live-out at all m ∈ pred[n]3.如果存在从 'n' 到使用 'v' 的有向路径并且该路径不包含任何定义'v'。
v live-out at n, v ∉ def[n] ⇒ v live-in at n活力算法:
Liveliness 算法必须执行所需的功能,算法设计中包含的步骤概述如下:
- 第一步是通过逐步分析 CFG 中的每个节点来识别定义了哪些变量以及由指令或程序语句读取(使用)哪些变量。此外,将 IN 和 OUT 的值初始化为 NULL。请注意,步骤 1 仅执行一次。
- 维护全局信息记录,旨在指定指令如何在程序周围传输实时值,并从def计算IN和OUT集,并使用表达式使用集。
- 现在,迭代 (2) 直到 IN 和 OUT 集在连续迭代中变得恒定。请记住, def和use集是常量,因此与路径无关!
活跃度算法如下:
N : Set of nodes of CFG;
for each n ∈ N do
in[n] ← φ;
out[n] ← φ;
end
repeat
for each n ∈ Nodes do
// First save the current value for IN and OUT for comparison later.
in'[n] ← in[n];
out'[n] ← out[n];
// For OUT, find out the union of previous variables
in the IN set for each succeeding node of n.
out[n] ← ∪s∈succ[n]in[s] ; // Compute OUT for a node.
in[n] ← use[n]∪(out[n]−def [n]); // Compute IN for a node.
end
// Iterate, untill IN and OUT set are constants for last two consecutive iterations.
until ∀n,in'[n] = in[n] ∧ out' [n] = out[n]; 实例活度算法分析:
问题:如果以下三个条件同时成立,则称变量 x 在程序中的语句 Si 处有效:
- 存在使用 x 的语句 Sj
- 程序对应的流程图中有一条从Si到Sj的路径
- 该路径没有对 x 的干预分配,包括在 Si 和 Sj
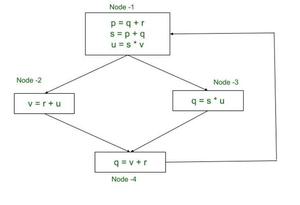
控制流图(活力分析示例)
解决方案: 4 3 2 1NODE(n) use[n] def[n] Initial Value 1st Iteration 2nd Iteration 3rd Iteration OUT1 IN1 OUT2 IN2 OUT3 IN3 OUT4 IN4 v,r q ∅ ∅ ∅ r,v q,r,v r,v q,r,v r,v s,u q ∅ ∅ v,r s,u,r,v v,r s,u,v,r v,r s,u,v,r r,u v ∅ ∅ v,r r,u v,r r,u v,r r,u q,r,v p,s,u ∅ ∅ s,u,r,v q,r,v s,u,r,v q,r,v s,u,r,v q,r,v
对于第一次迭代,当我们从节点 4 开始过程时,我们将 OUT 和 IN 设置为 ∅。截至目前,OUT 和 IN 是空集。现在 OUT[n] 使用表达式∪ s∈succ[n] in[s]进行评估,并且由于 Node-4 由 Node-1 接替,我们有:
Using , out[n] ← ∪s∈succ[n]in[s] , we have
OUT2[4] ← IN2[1]
OUT2[4] ← ∅It is important to note that IN2[1] has not been evaluated yet for the 1st iteration. Here, we only use the initial value for IN2[1] , which is same as IN1[1] and that is Empty Set. Later, when the value is evaluated by procedure, the result is updated to the table as well.
同样,我们评估 IN 2 [4] 如下:
in[n] ← use[n]∪(out[n]−def [n])
IN2[4] ← use[4]∪(OUT2[4]-def[4])
We know, use[4]← {v,r} , OUT2[4] is ∅ & def[4] ← {q}
IN2[4] ← {v,r}∪( ∅ - {q} )
IN2[4] ← {v,r}让我们评估 Node-1 的 IN 和 OUT,然后是 Node-2 和 Node-3,如下所示:
Using , out[n] ← ∪s∈succ[n]in[s] , we have
OUT2[1] ← IN2[2] ∪ IN2[3]
OUT2[1] ← {s, u, r, v} ∪ {r, u}
OUT2[1] ← { s, u, r, v}现在我们评估 IN 2 [1] 如下:
in[n] ← use[n]∪(out[n]−def [n])
IN2[1] ← use[1]∪(OUT2[1]-def[1])
We know, use[1]← {q, r, v} , OUT2[1] is {s,u,r,v} & def[1] ← {p,s,u}
IN2[1] ← {q,r,v}∪( {s,u,r,v}- {p,s,u})
IN2[1] ← {q,r,v}∪( {r,v} )
IN2[1] ← {q,r,v}此外,请注意,对于下一次迭代,Node-4 的 OUT 评估如下:
Using , out[n] ← ∪s∈succ[n]in[s] , we have
OUT3[4] ← IN3[1]
Note that we use the already evaluated value of IN.
As we begin with Node-4 we use IN3[1] = IN2[1].
IN2[1] is as calculated above.
OUT3[4] ← { q, r ,v}该过程在第 3次迭代后终止,因为最后两次迭代的每个结果集的值完全相同。
时间复杂度分析:
对于大小为 N 的输入程序,CFG 中≤N 个节点和≤N 个变量,我们有:
- 每个输入/输出 N 个元素,因此,在最坏的情况下,每个集合并集需要 O(N) 时间。
- 请注意, for循环对每个节点执行恒定数量的集合操作,因此 O(N 2 ) 是循环的总时间复杂度。
- 所有 IN 和 OUT 的大小总和为 2N 2 ,它限制了重复循环的迭代次数
- 我们可以将Liveliness算法的最坏情况时间复杂度评估为 O(N 4 )。
- 重要的是要注意,适当的排序和使用有效的数据结构可以将重复循环减少到 2-3 次迭代。
- 我们可以得出结论,Liveliness 算法的最小可能最坏情况时间复杂度是 O(N) 或 O(N 2 )。