- 编译器设计中的语义分析
- 编译器设计中的语义分析(1)
- 编译器设计中的语义分析
- 编译器设计-词法分析
- 编译器设计-词法分析(1)
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器
- 编译器设计中的活力分析(1)
- 编译器设计中的活力分析
- 编译器设计教程(1)
- 编译器设计教程
- 编译器设计-正则表达式(1)
- 编译器设计-正则表达式
- 讨论编译器设计
- 编译器设计中的解析树
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析树(1)
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的左递归 (1)
- 编译器设计-概述(1)
- 编译器设计-概述
- 编译器设计介绍(1)
- 编译器设计介绍
- 编译器设计介绍
- 编译器设计介绍(1)
📅 最后修改于: 2021-01-18 05:27:56 🧑 作者: Mango
我们已经了解了语法分析阶段解析器如何构造解析树。在该阶段构造的纯分析树通常对于编译器没有用,因为它不包含任何有关如何评估树的信息。上下文相关语法的产生使语言规则成为可能,但它们不适应如何解释它们。
例如
E → E + T
上面的CFG生产没有与之相关的语义规则,也无助于使生产有任何意义。
语义学
语言的语义为其标记提供含义,例如标记和语法结构。语义有助于解释符号,符号的类型及其相互之间的关系。语义分析判断源程序中构造的语法结构是否得出任何含义。
CFG + semantic rules = Syntax Directed Definitions
例如:
int a = “value”;
不应在词法和语法分析阶段发出错误,因为它在词法和结构上都是正确的,但应在分配类型不同时产生语义错误。这些规则由语言的语法设置,并在语义分析中进行评估。在语义分析中应执行以下任务:
- 范围解析
- 类型检查
- 数组绑定检查
语义错误
我们已经提到了语义分析器应该识别的一些语义错误:
- 类型不匹配
- 未声明的变量
- 保留的标识符滥用。
- 作用域中变量的多重声明。
- 访问超出范围的变量。
- 实际和形式参数不匹配。
属性语法
属性语法是上下文无关语法的一种特殊形式,其中一些附加信息(属性)被附加到一个或多个非上下文非终结符上,以提供上下文相关的信息。每个属性都有明确定义的值域,例如整数,浮点数,字符,字符串和表达式。
属性语法是一种向上下文无关语法提供语义的媒介,它可以帮助指定编程语言的语法和语义。属性语法(当被视为解析树时)可以在树的节点之间传递值或信息。
例:
E → E + T { E.value = E.value + T.value }
CFG的右侧部分包含语义规则,这些语义规则指定应如何解释语法。在此,将非终端E和T的值相加,然后将结果复制到非终端E。
语义属性可以在解析时从其域分配给它们的值,并在分配或条件时进行评估。根据属性获取值的方式,可以将它们大致分为两类:综合属性和继承属性。
综合属性
这些属性从其子节点的属性值获取值。为说明起见,假定以下生产:
S → ABC
如果S从其子节点(A,B,C)取值,则称其为综合属性,因为ABC的值已综合到S.
如前面的示例(E→E + T),父节点E从其子节点获取其值。合成属性从不从其父节点或任何同级节点获取值。
继承的属性
与合成属性相反,继承的属性可以从父级和/或同级中获取值。在以下制作中,
S → ABC
A可以从S,B和C获取值。B可以从S,A和C获取值。同样,C可以从S,A和B获取值。
扩展:当非终结符按照语法规则扩展为终结符时
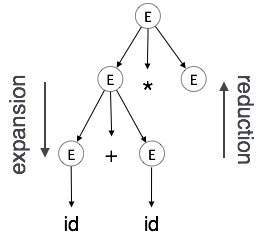
归约:根据语法规则将一个终端缩减为对应的非终端时。语法树是自上而下且从左到右解析的。每当发生归约时,我们都会应用其相应的语义规则(动作)。
语义分析使用语法定向翻译来执行上述任务。
语义分析器从上一阶段(语法分析)接收AST(抽象语法树)。
语义分析器将属性信息与AST一起附加,称为AST。
属性是两个元组值,<属性名称,属性值>
例如:
int value = 5;
对于每个产品,我们都附加一个语义规则。
S属性SDT
如果SDT仅使用合成属性,则将其称为S属性SDT。这些属性是使用S属性SDT进行评估的,这些SDT的语义动作在生产后(右侧)写入。

如上所述,由于父节点的值取决于子节点的值,因此在S自定义SDT中的属性在自下而上的解析中进行评估。
L属性SDT
这种形式的SDT使用合成属性和继承属性,并限制了不从正确的同级中获取值。
在具有L属性的SDT中,非终端可以从其父节点,子节点和同级节点获取值。如以下生产
S → ABC
S可以取A,B和C中的值(综合值)。 A只能从S获取值。 B可以从S和A中获取值。C可以从S,A和B中获取值。非终结符不能从其右侧的同级中获取值。
通过深度优先和从左到右的解析方式来评估L属性SDT中的属性。
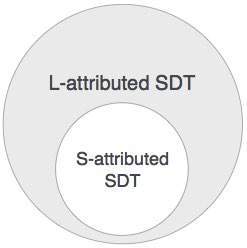
我们可以得出的结论是,如果定义具有S属性定义,那么它也属于L属性,因为L属性定义包含S属性定义。