- KDB+教程(1)
- KDB+教程
- 讨论KDB+(1)
- 讨论KDB+
- KDB+概述(1)
- KDB+概述
- KDB+-有用的资源(1)
- KDB+-有用的资源
- MySQL的体系结构
- MySQL的体系结构(1)
- Docker-体系结构
- Docker-体系结构(1)
- Docker体系结构
- Docker体系结构(1)
- Angular 7体系结构
- TensorFlow的体系结构(1)
- TensorFlow的体系结构
- DBMS-体系结构(1)
- DBMS-体系结构
- DBMS体系结构(1)
- DBMS体系结构
- JavaFX-体系结构
- JavaFX体系结构
- JavaFX体系结构(1)
- JavaFX-体系结构(1)
- CodeIgniter体系结构(1)
- CodeIgniter体系结构
- 什么是.NET 3层体系结构?
- 什么是.NET 3层体系结构?(1)
📅 最后修改于: 2020-11-03 06:42:05 🧑 作者: Mango
Kdb +是从一开始就设计用于处理大量数据的高性能,大容量数据库。它是全64位的,并具有内置的多核处理和多线程功能。实时和历史数据使用相同的体系结构。数据库结合了自己强大的查询语言q,因此分析可以直接在数据上运行。
kdb + tick是一种允许捕获,处理和查询实时和历史数据的体系结构。
Kdb + / tick体系结构
下图提供了典型的Kdb + / tick体系结构的一般概述,然后简要说明了各种组件和数据流。
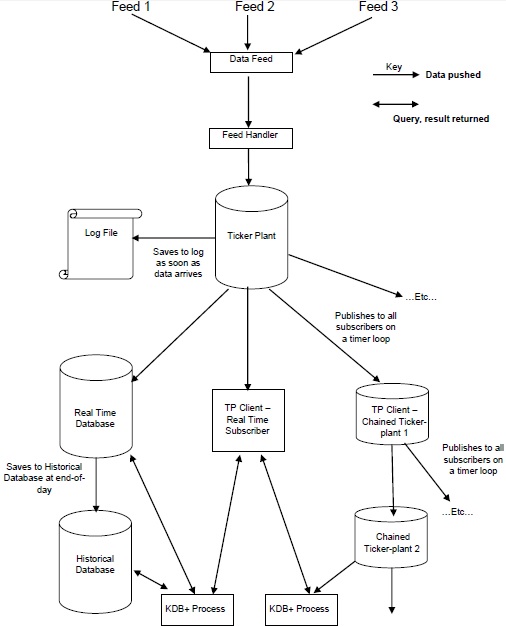
-
数据Feed是一个时间序列数据,主要由路透社,彭博社等数据Feed提供商或直接从交易所提供。
-
为了获取相关数据,供稿处理程序会解析来自数据供稿的数据。
-
提要处理程序解析完数据后,该数据将转到ticker-plant 。
-
为了从任何故障中恢复数据,自动报价机首先将新数据更新/存储到日志文件,然后更新其自己的表。
-
更新内部表和日志文件后,将按时循环数据连续发送/发布到实时数据库以及所有需要数据的链接订户。
-
在工作日结束时,将删除日志文件,创建一个新文件,并将实时数据库保存到历史数据库中。将所有数据保存到历史数据库后,实时数据库将清除其表。
Kdb + Tick体系结构的组件
数据馈送
数据Feed可以是任何市场数据或其他时间序列数据。将数据提要视为提要处理程序的原始输入。提要可以直接来自交易所(实时流数据),来自汤姆森-路透社,彭博社或任何其他外部机构的新闻/数据提供者。
饲料处理机
提要处理程序将数据流转换为适合写入kdb +的格式。它连接到数据提要,并从提要特定的格式中检索数据并将其转换为Kdb +消息,该消息将发布到置顶工厂流程中。通常,提要处理程序用于执行以下操作-
- 根据一组规则捕获数据。
- 将数据从一种格式转换(/丰富)到另一种格式。
- 捕获最新值。
股票行情
股票代号工厂是KDB+体系结构中最重要的组成部分。实时数据库或直接与订户(客户端)相连的代币工厂,以访问财务数据。它以发布和订阅机制运行。一旦获得订阅(许可证),就定义了来自发布者(代码工厂)的价格变动(常规)发布。它执行以下操作-
-
从提要处理程序接收数据。
-
报价器工厂收到数据后,立即将副本存储为日志文件,并在报价器工厂进行任何更新后立即对其进行更新,这样,万一发生任何故障,我们就不会有任何数据丢失。
-
客户(实时订户)可以直接订阅行情收录器。
-
在每个工作日结束时,即实时数据库接收到最后一条消息后,它将所有今天的数据存储到历史数据库中,并将其推送给所有订阅了今天数据的订户。然后,它重置所有表。一旦数据存储在历史数据库或其他直接链接到实时数据库(rtdb)的订户中,日志文件也将被删除。
-
结果,股票行情发生器,实时数据库和历史数据库的运行时间为24/7。
由于ticker-plant是Kdb +应用程序,因此可以像其他任何Kdb +数据库一样使用q查询其表。所有股票行情客户端都只能以订阅者身份访问数据库。
实时数据库
实时数据库(rdb)存储当今的数据。它直接连接到采摘工厂。通常,它将在一天的工作时间(一天)存储在内存中,并在一天结束时写到历史数据库(hdb)中。由于数据(rdb数据)存储在内存中,因此处理速度非常快。
由于kdb +建议将RAM大小设置为每天预期数据大小的四倍或更多倍,因此在rdb上运行的查询速度非常快,并且可以提供出色的性能。由于实时数据库仅包含今天的数据,因此不需要日期列(参数)。
例如,我们可以使用rdb查询,例如
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100
历史数据库
如果必须计算公司的估计值,则需要提供其历史数据。历史数据库(hdb)保存过去完成的交易数据。每一天的新记录将在一天结束时添加到hdb中。 hdb中的大型表要么被扩展显示(每个列存储在其自己的文件中),要么被临时数据分区存储。另外,一些非常大的数据库也可以使用par.txt (文件)进行进一步分区。
这些存储策略(扩展,分区等)在从大表中搜索或访问数据时非常有效。
历史数据库也可以用于内部和外部报告目的,即用于分析。例如,假设我们要从交易(或任何)表名称获取特定日期的IBM公司交易,我们需要编写如下查询:
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibm
注意-一旦获得q语言的概述,我们将编写所有此类查询。