PostgreSQL – LEAD函数
在 PostgreSQL 中,LEAD()函数用于访问当前行之后的行,在特定的物理偏移处,通常用于将当前行的值与当前行之后的下一行的值进行比较。
LEAD()函数的语法如下所示:
Syntax:
LEAD(expression [, offset [, default_value]])
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
我们来分析一下上面的语法:
- 表达可以是列,表达,子查询必须评估为单个值。
- 偏移量是一个正整数,指定从当前行转发的行数。它通常是一个表达式、子查询或列。如果未设置偏移量,则默认为 1。
- PARTITION BY 子句将行划分为多个分区。默认情况下,它将查询结果作为单个分区。
- ORDER BY子句用于每个分区中的查询结果行进行排序。
示例 1:
让我们为名为 Match 的演示设置一个新表:
CREATE TABLE Match(
year SMALLINT CHECK(year > 0),
match_id INT NOT NULL,
overs DECIMAL(10,2) NOT NULL,
PRIMARY KEY(year,match_id)
);
现在插入一些数据:
INSERT INTO
Match(year, match_id, overs)
VALUES
(2018, 1, 140),
(2018, 2, 174),
(2018, 3, 130),
(2019, 1, 90),
(2019, 2, 100),
(2019, 3, 120),
(2020, 1, 50),
(2020, 2, 70),
(2020, 3, 20);
下面的查询使用LEAD()函数返回当前年份的溢价和每年的平均溢价:
WITH cte AS (
SELECT
year,
SUM(overs) overs
FROM Match
GROUP BY year
ORDER BY year
)
SELECT
year,
overs,
LEAD(overs, 1) OVER (
ORDER BY year
) year_average
FROM
cte;
输出:

示例 2:
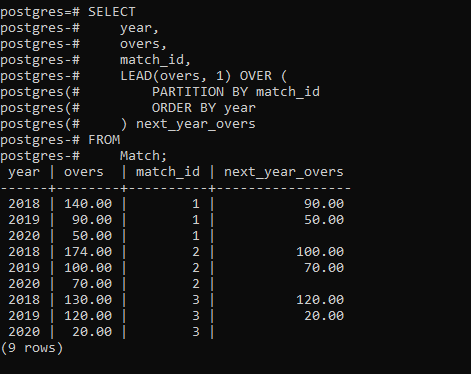
以下语句使用LEAD()函数来比较每个组的当前年份和下一年的结果:
SELECT
year,
overs,
match_id,
LEAD(overs, 1) OVER (
PARTITION BY match_id
ORDER BY year
) next_year_overs
FROM
Match;
输出: