使用 R 编程设置机器学习环境
机器学习是人工智能 (AI) 的一个子集,用于创建无需明确编程即可学习的智能系统。在机器学习中,我们创建算法和模型,智能系统使用这些算法和模型根据从给定数据中观察到的特定模式或趋势来预测结果。机器学习遵循使用数据和数据结果来预测存储在模型中的规则的独特原则。然后使用该模型来预测来自不同数据集的结果。在 R 编程中,机器学习环境可以通过 RStudio 轻松设置。
使用 Anaconda 设置机器学习环境
第 1 步:安装 Anaconda(Linux、Windows)并启动导航器。
第 2 步:打开 Anaconda Navigator 并单击 Rstudio 的安装按钮。 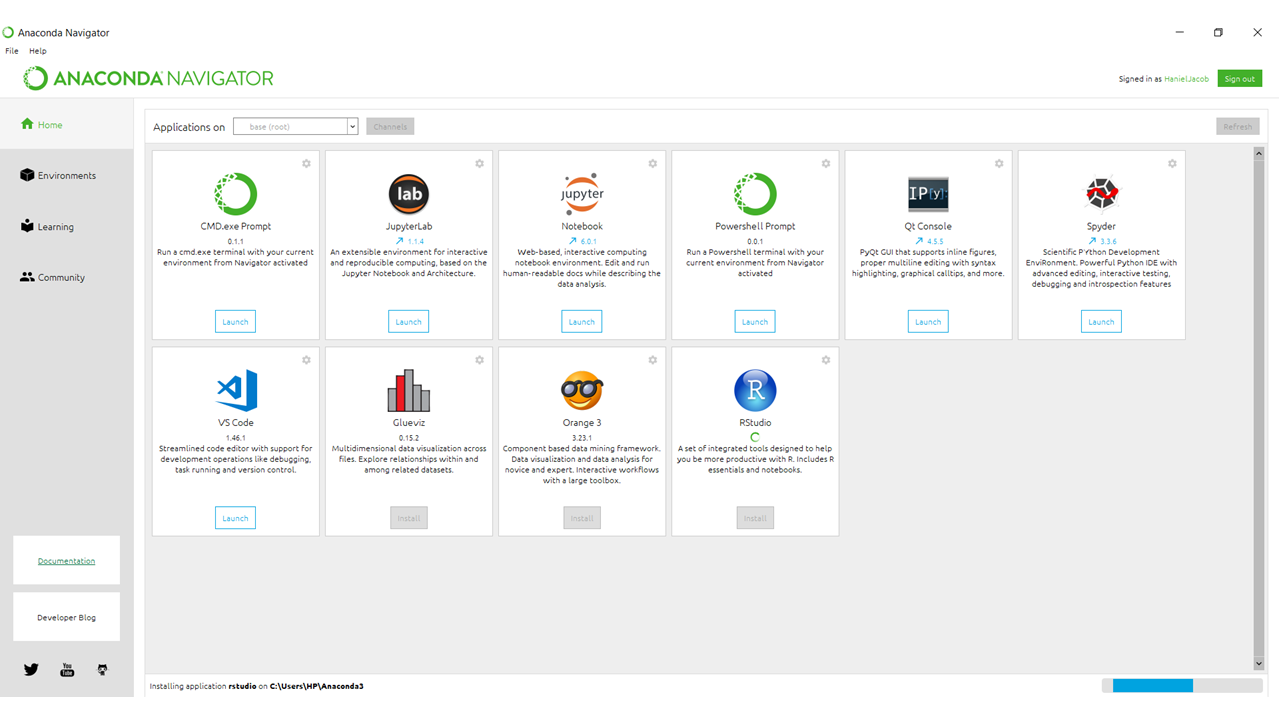
第三步:安装完成后,创建一个新环境。 Anaconda 然后会发送一个提示,要求输入新环境的名称和 R 工作室的午餐。 
运行 R 命令
方法 1: R 命令可以从 R studio 中提供的控制台运行。打开 Rstudio 后,只需在控制台输入 R 命令。 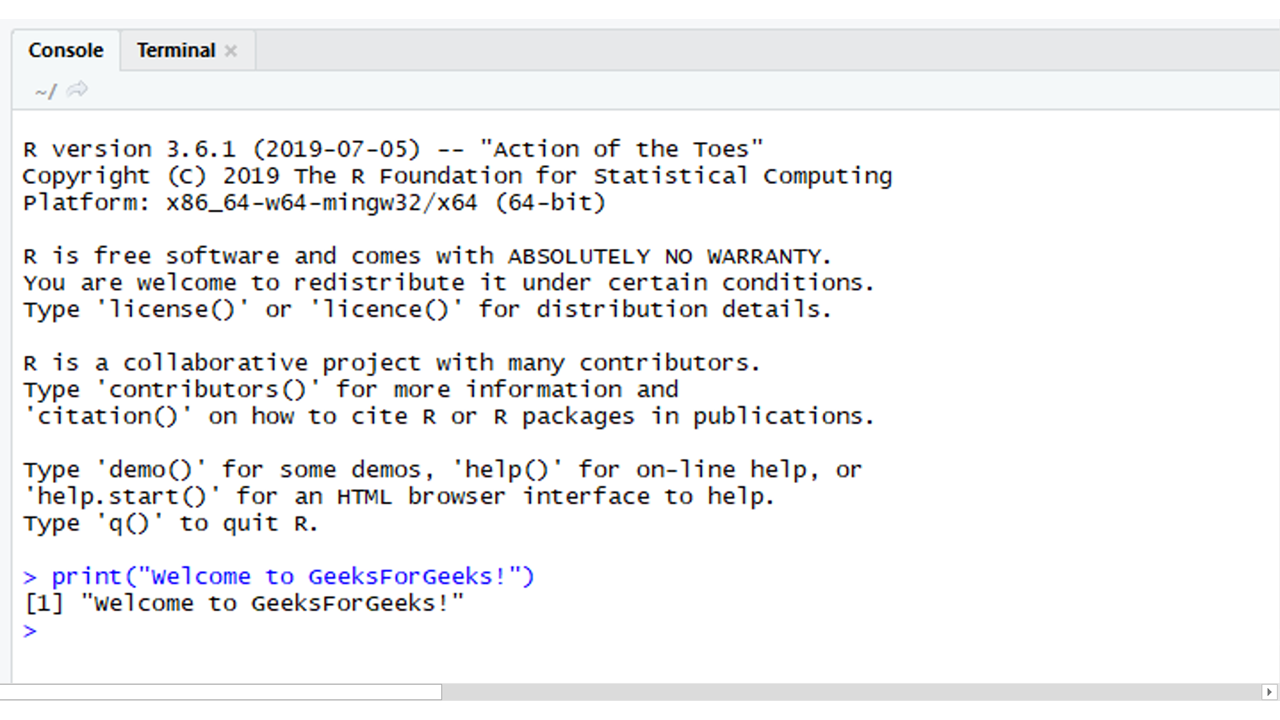
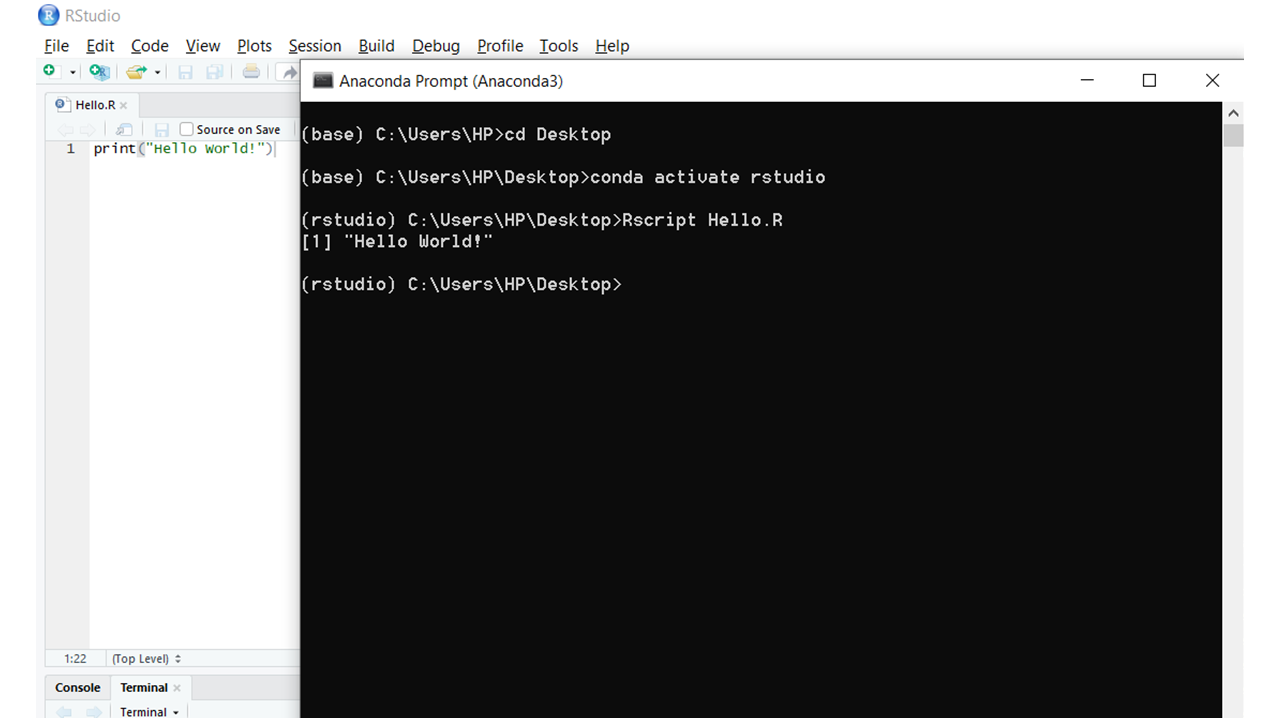
方法2 :R命令可以存储在一个文件中,可以在anaconda提示符下执行。这可以通过以下步骤来实现。
- 打开 anaconda 提示符
- 进入R文件所在目录
- 使用以下命令激活 anaconda 环境:
conda activate - 使用以下命令运行文件:
Rscript.R
在 R 中安装机器学习包
包有助于使代码更容易编写,因为它们包含一组执行各种任务的预定义函数。最常用的机器学习包是Caret、e1071、net、kernlab 和 randomforest 。有两种方法可用于为您的 R 程序安装这些包。
方法一:通过 Rstudio 安装包
- 打开 Rstudio 并单击菜单栏中的工具下的安装包选项。
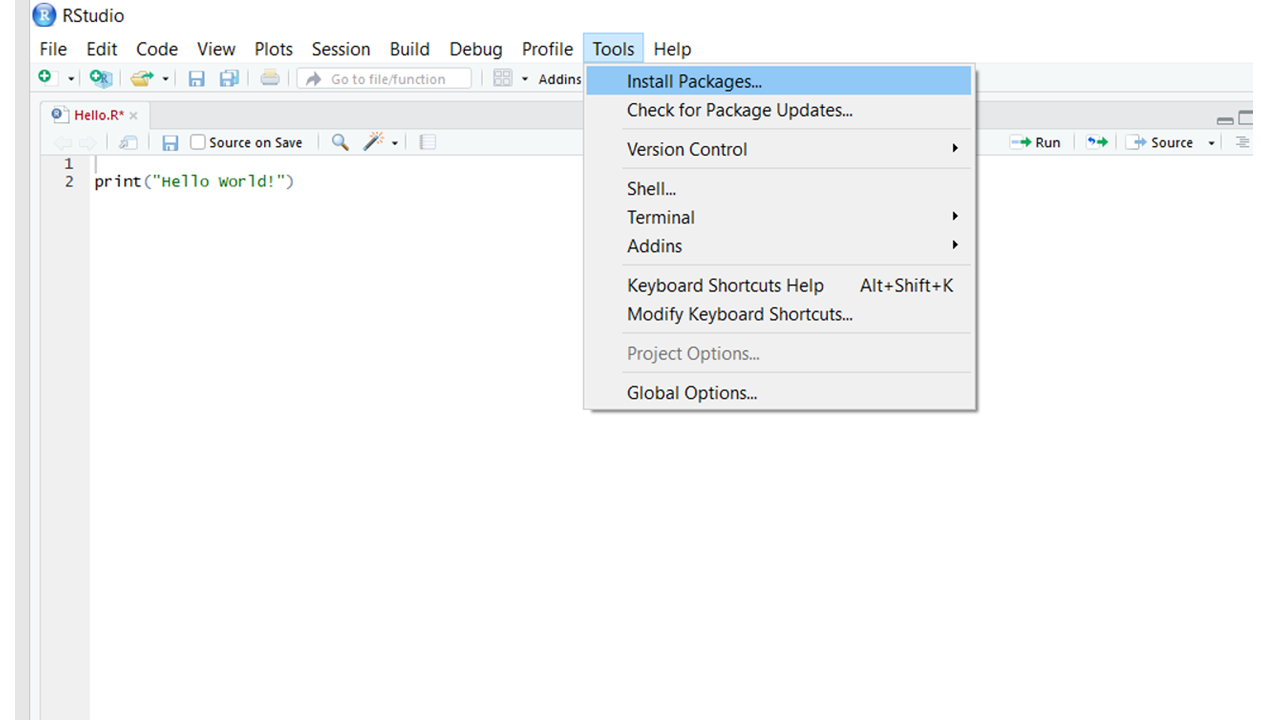
- 输入要安装的所有软件包的名称,用空格或逗号分隔,然后单击安装。
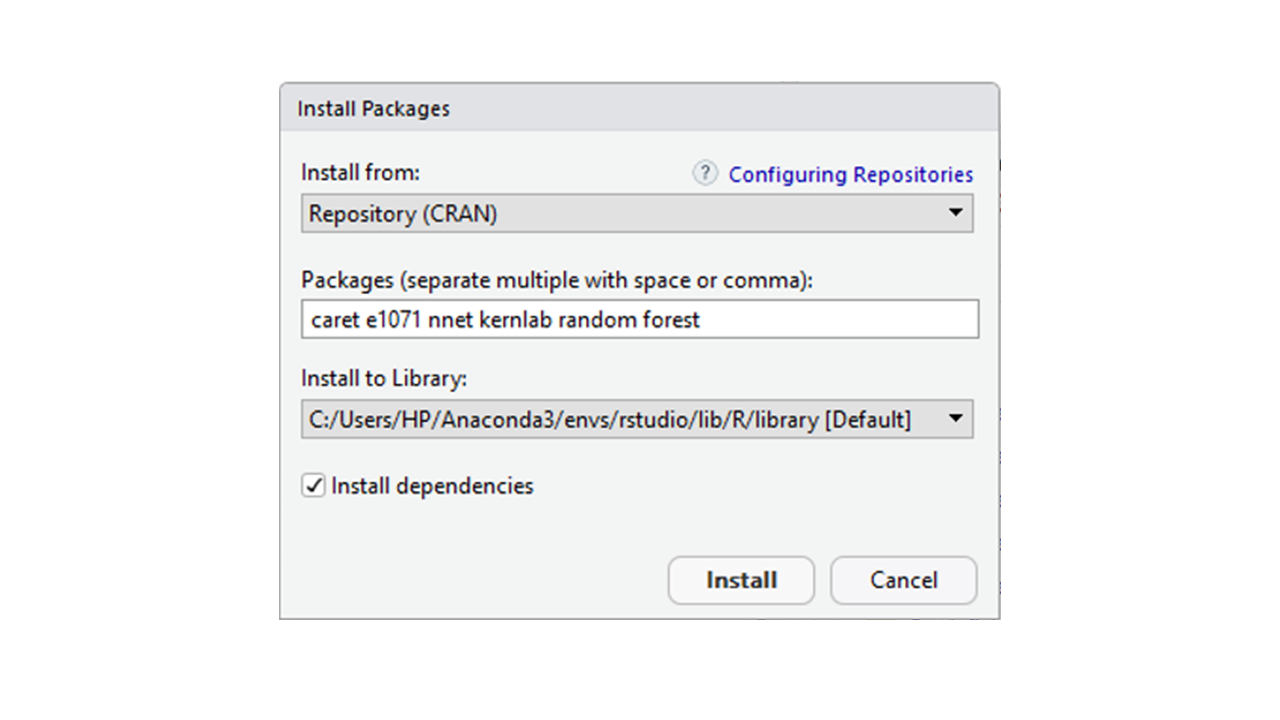
方法二:通过 Anaconda 提示符/Rstudio 控制台安装包
- 打开 Anaconda 提示符。
- 使用以下命令将环境切换到您用于 Rstudio 的环境:
conda activate - 输入命令r打开 R 控制台。
- 使用以下命令安装所需的包:
install.packages(c("", " ", ..., " "))
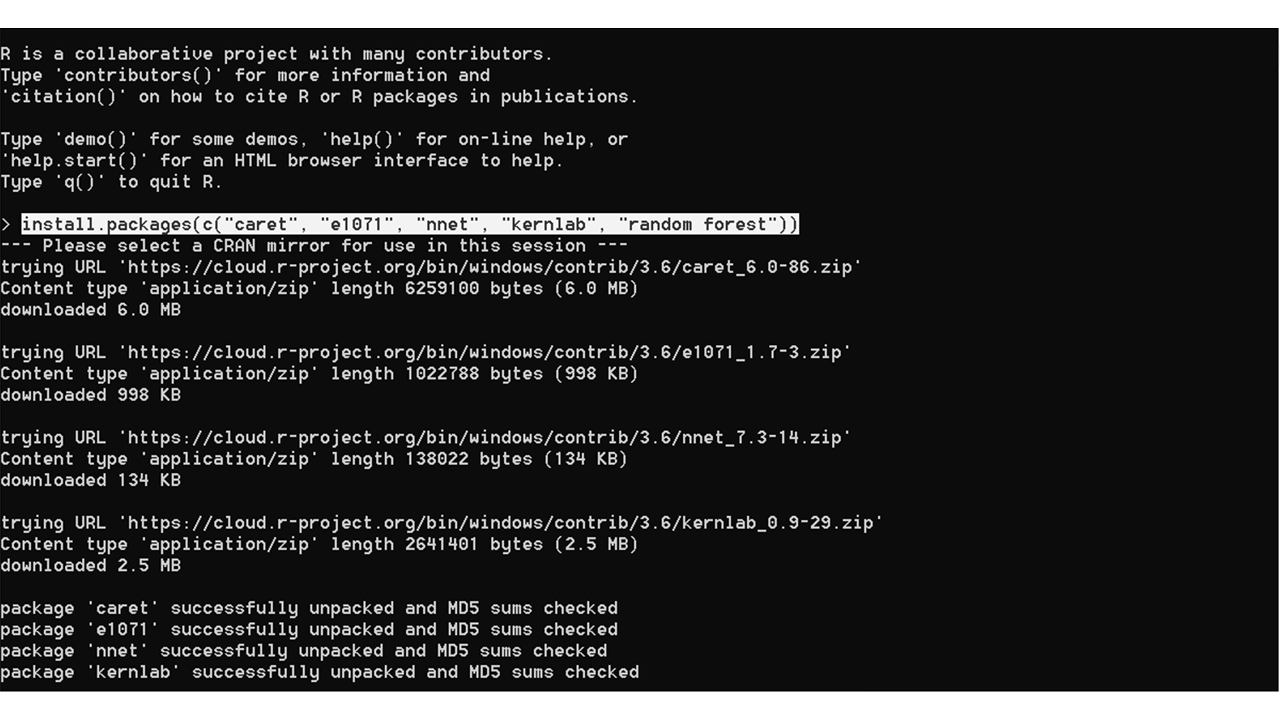
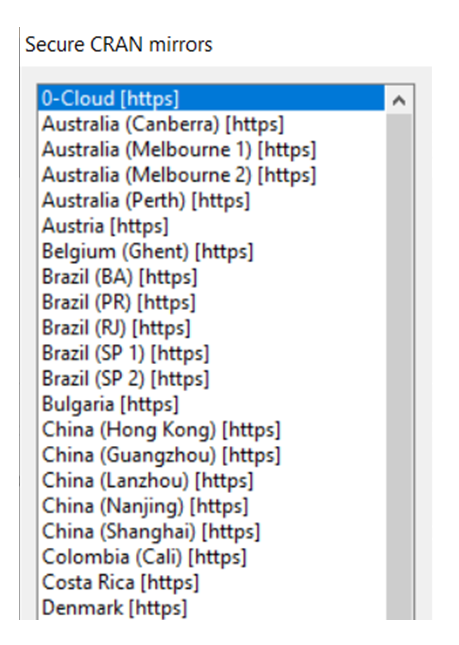
下载软件包时,系统可能会提示您选择CRAN镜像。建议选择离您最近的位置以加快下载速度。
R 中的机器学习包
有许多 R 库包含大量用于管理和分析数据的函数、工具和方法。这些库中的每一个都有一个特定的重点,其中一些库管理图像和文本数据、数据操作、数据可视化、网络爬虫、机器学习等。在这里,让我们通过一个示例来讨论一些重要的机器学习包。
例子:
准备数据集:
在使用这些包之前,首先将数据集导入 RStudio,清理数据集,并将数据拆分为训练和测试数据集。从此链接下载 CSV 文件。# Import the data set Data <- read.csv("GenderClassification.csv", stringsAsFactors = TRUE) # Using set.seed() # Generating random number set.seed(10) # Cleaning the data set Data$Favorite.Color <- as.numeric (Data$Favorite.Color) Data$Favorite.Music.Genre <- as.numeric (Data$Favorite.Music.Genre) Data$Favorite.Beverage <- as.numeric (Data$Favorite.Beverage) Data$Favorite.Soft.Drink <- as.numeric (Data$Favorite.Soft.Drink) # Split into train and test data set TrainingSize <- createDataPartition(Data$Gender, p = 0.8, list = FALSE) TrainingData <- Data[TrainingSize,] TestingData <- Data[-TrainingSize,]CARET : Caret 代表分类和回归训练。 CARET包用于执行分类和回归任务。它由许多其他内置包组成。
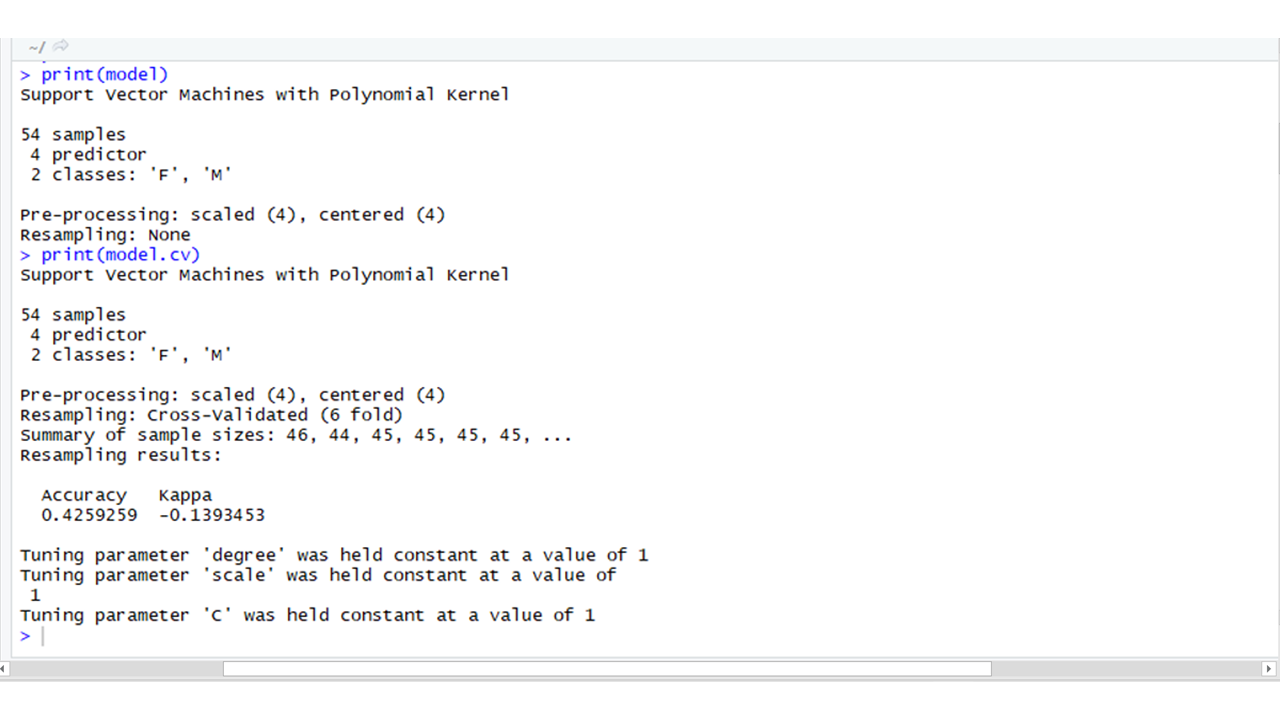
# Using CARET package # Importing the library library(caret) # Using the train() available in # Caret package model <- train(Gender ~ ., data = TrainingData, method = "svmPoly", na.action = na.omit, preProcess = c("scale", "center"), trControl = trainControl(method = "none"), tuneGrid = data.frame(degree = 1, scale = 1, C = 1) ) model.cv <- train(Gender ~ ., data = TrainingData, method = "svmPoly", na.action = na.omit, preProcess = c("scale", "center"), trControl = trainControl(method = "cv", number = 6), tuneGrid = data.frame(degree = 1, scale = 1, C = 1) ) # Printing the models print(model) print(model.cv)输出:
ggplot2 :R 以其可视化库 ggplot2 最为著名。它提供了一组美观的图形,这些图形也是交互式的。 ggplot2包用于创建绘图和可视化数据。
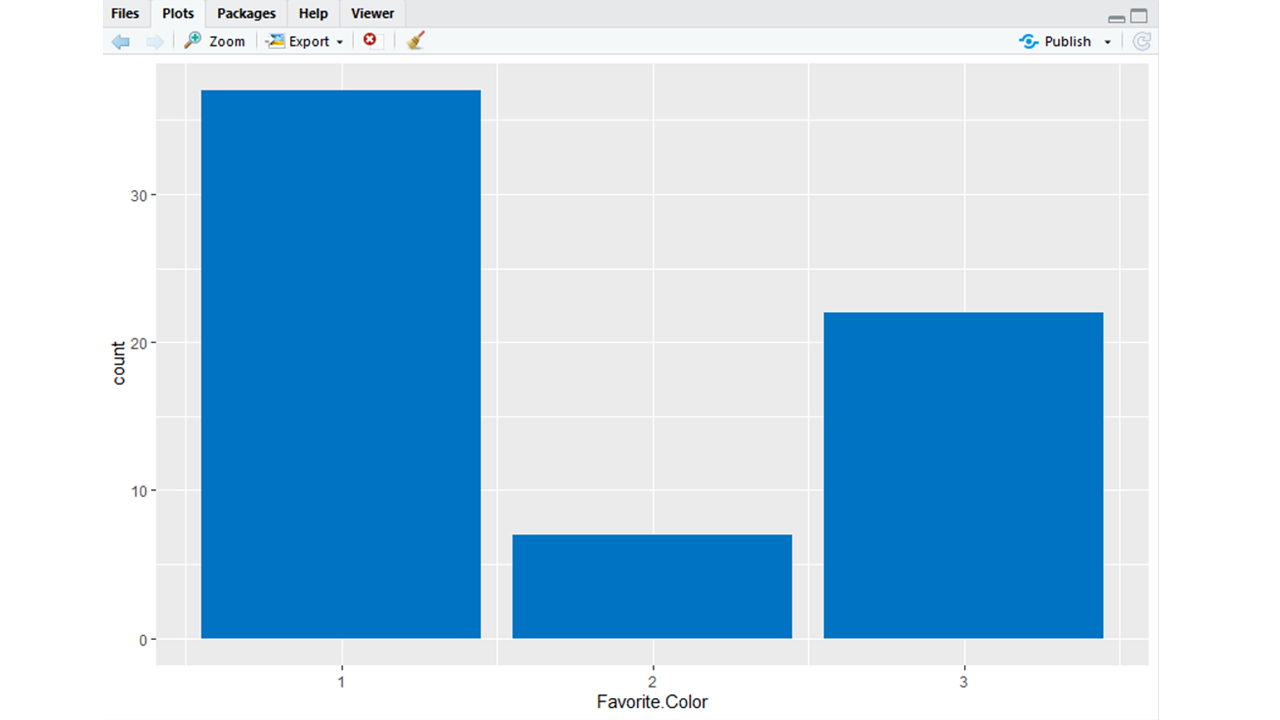
# Using ggplot2 # Creating a bar plot from the # Data's Favorite.Color attribute ggplot(Data, aes(Favorite.Color)) + geom_bar(fill = "#0073C2FF")输出:
randomForest : randomForest包允许我们轻松使用随机森林算法。
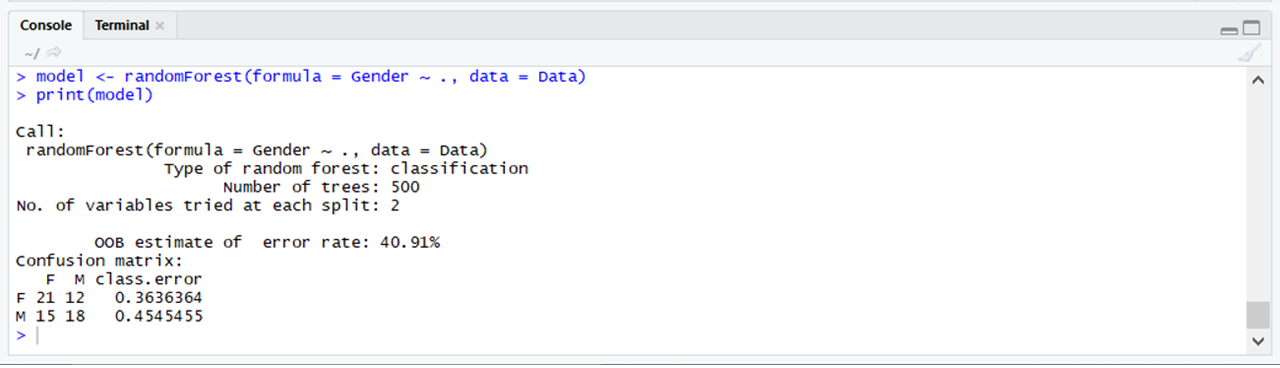
# Using randomforset # Importing the randomForest package library(randomForest) # Using the randomForest function # From the randomForest package model <- randomForest(formula = Gender ~ ., data = Data) print(model)输出:
nnet : nnet包在深度学习中使用神经网络来创建有助于训练和预测模型的层。每次训练迭代后,损失(实际值和预测值之间的差异)都会减小。
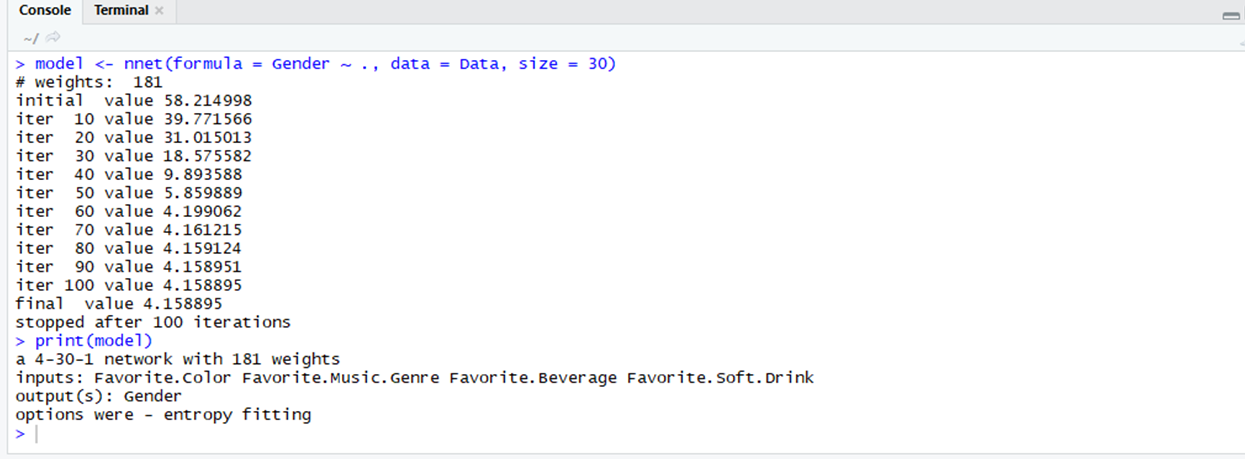
# Using nnet # Importing the nnet package library(nnet) # Using the nnet function # In the nnet package model <- nnet(formula = Gender ~ ., data = Data, size = 30) print(model)输出:
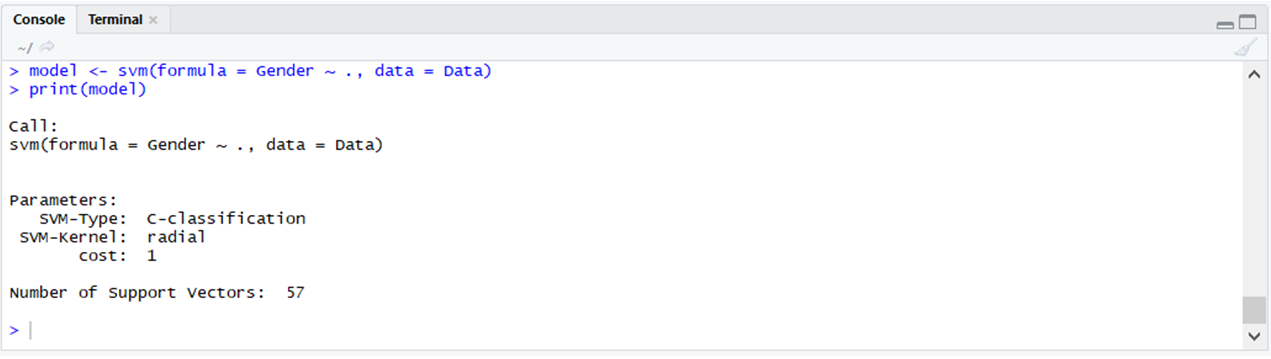
e1071 : e1071包用于实现支持向量机、朴素贝叶斯算法和许多其他算法。
# Using e1071 # Importing the e1071 package library(e1071) # Using the svm function # In the e1071 package model <- svm(formula = Gender ~ ., data = Data) print(model)输出:
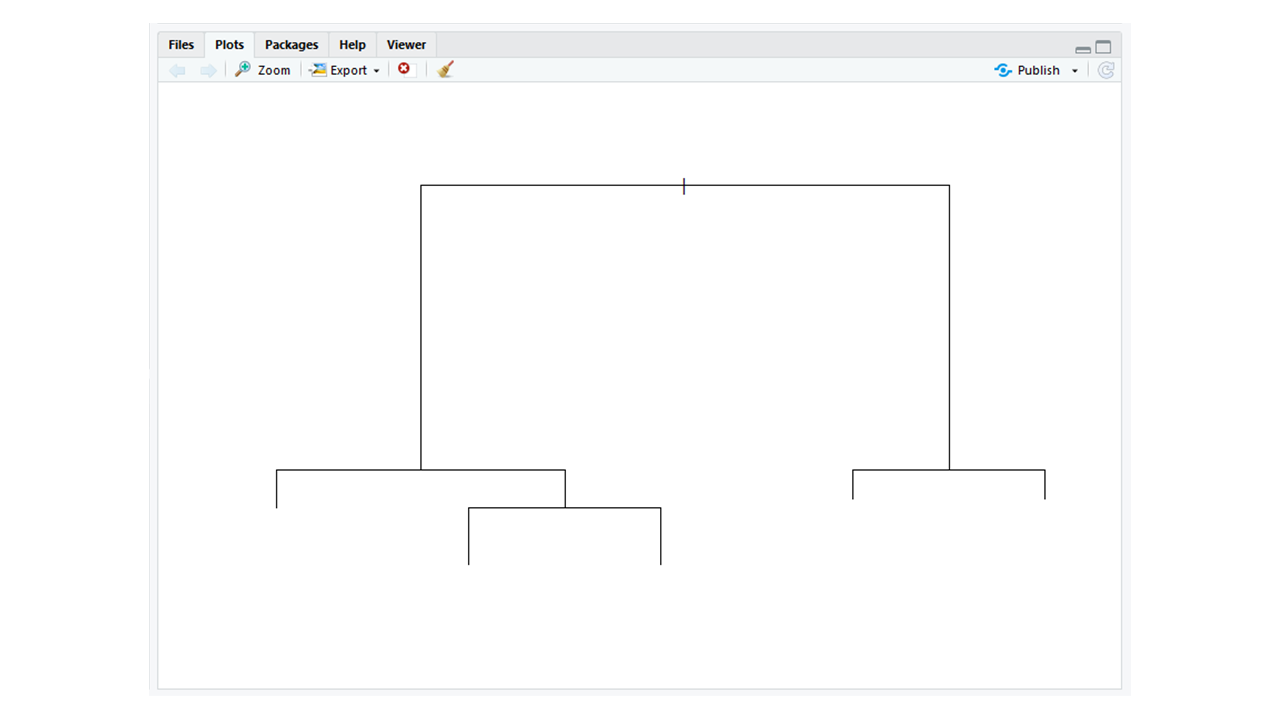
rpart : rpart包用于对数据进行分区。它用于分类和回归任务。结果模型是二叉树的形式。
# Using rpart # Importing the rpart package library(rpart) # Using the rpart function # To partition data partition <- rpart(formula = Gender~., data = Data) plot(partition)输出:
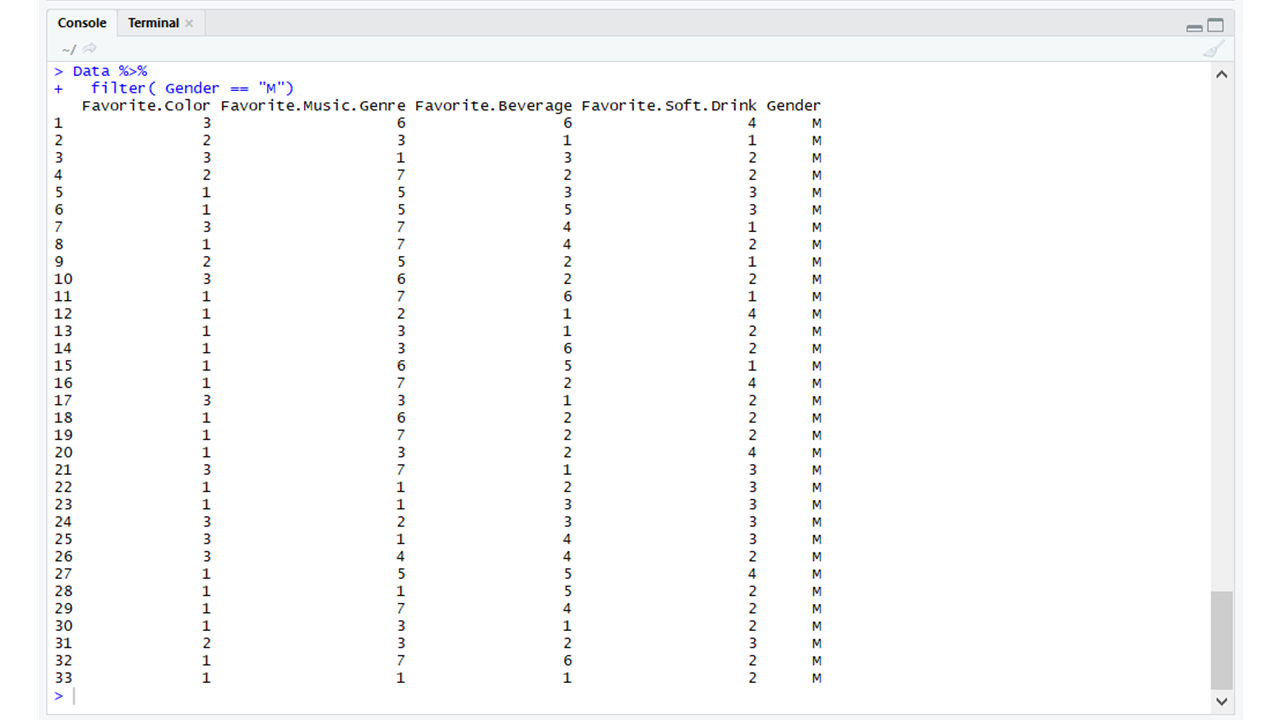
dplyr :与rpart一样, dplyr包也是一个数据操作包。它通过使用过滤、选择和排列等功能来帮助操作数据。
# Using dplyr # Importing the dplyr package library(dplyr) # Using the filter function # From the dplyr package Data %>% filter(Gender == "M")输出: