使用 PCA 减少数据维度 – Python
介绍
数据科学和机器学习的进步使我们能够解决一些复杂的回归和分类问题。但是,所有这些 ML 模型的性能取决于提供给它们的数据。因此,我们必须为我们的 ML 模型提供最佳数据集。现在,人们可能会认为我们为模型提供的数据越多,它就会变得越好——然而,事实并非如此。如果我们为模型提供过大的数据集(具有大量特征/列),则会产生过度拟合的问题,其中模型开始受到异常值和噪声的影响。这被称为维度诅咒。
下图表示随着数据集维数的增加,模型性能的变化。可以观察到,模型性能仅在一个期权维度上是最好的,超过这个维度它开始下降。

模型性能与维度数(特征)——维度的诅咒
降维是一种基于统计/ML 的技术,我们尝试减少数据集中的特征数量并获得具有最佳维数的数据集。
实现降维的最常见方法之一是特征提取,其中我们通过将高维特征空间映射到低维特征空间来减少维数。最流行的特征提取技术是主成分分析(PCA)
主成分分析 (PCA)
如前所述,主成分分析是一种将高维特征空间映射到低维特征空间的特征提取技术。在减少维数的同时,PCA 保证原始数据集的最大信息保留在减少维数的数据集中。维数和新获得的主成分之间的相关性最小。应用 PCA 后获得的新特征称为主成分,记为PCi (i=1,2,3…n) 。这里,(Principal Component-1)PC1 捕获原始数据集的最大信息,其次是 PC2,然后是 PC3,以此类推。
下面的条形图描述了各种主成分捕获的解释方差的数量。 (解释方差定义了主成分捕获的信息量)。

解释方差与主成分
为了了解主成分分析中涉及的数学方面,请查看 PCA 的数学方法。在本文中,我们将重点介绍如何在Python中使用 PCA 进行降维。
在Python中应用 PCA 进行降维的步骤
我们将通过一个示例逐步了解在Python中应用主成分分析的方法。在此示例中,我们将使用 iris 数据集,该数据集已经存在于Python的 sklearn 库中。
Step-1:导入必要的库
下面提到了加载数据集、对其进行预处理然后对其应用 PCA 所需的所有必要库:
Python3
# Import necessary libraries
from sklearn import datasets # to retrieve the iris Dataset
import pandas as pd # to load the dataframe
from sklearn.preprocessing import StandardScaler # to standardize the features
from sklearn.decomposition import PCA # to apply PCA
import seaborn as sns # to plot the heat mapsPython3
#Load the Dataset
iris = datasets.load_iris()
#convert the dataset into a pandas data frame
df = pd.DataFrame(iris['data'], columns = iris['feature_names'])
#display the head (first 5 rows) og the dataset
df.head()Python3
#Standardize the features
#Create an object of StandardScaler which is present in sklearn.preprocessing
scalar = StandardScaler()
scaled_data = pd.DataFrame(scalar.fit_transform(df)) #scaling the data
scaled_dataPython3
#Check the Co-relation between features without PCA
sns.heatmap(scaled_data.corr())Python
#Applying PCA
#Taking no. of Principal Components as 3
pca = PCA(n_components = 3)
pca.fit(scaled_data)
data_pca = pca.transform(scaled_data)
data_pca = pd.DataFrame(data_pca,columns=['PC1','PC2','PC3'])
data_pca.head()Python3
#Checking Co-relation between features after PCA
sns.heatmap(data_pca.corr())步骤 2:加载数据集
导入所有必要的库后,我们需要加载数据集。现在,虹膜数据集已经存在于 sklearn 中。首先,我们将其加载,然后将其转换为 pandas 数据框以方便使用。
Python3
#Load the Dataset
iris = datasets.load_iris()
#convert the dataset into a pandas data frame
df = pd.DataFrame(iris['data'], columns = iris['feature_names'])
#display the head (first 5 rows) og the dataset
df.head()
输出:

虹膜数据集
第三步:标准化特征
在应用 PCA 或任何其他机器学习技术之前,标准化数据始终被认为是一种好的做法。为此,标准标量是最常用的标量。 sklearn 中已经存在标准标量。因此,现在我们将使用标准标量对特征集进行标准化,并将缩放后的特征集存储为 pandas 数据框。
Python3
#Standardize the features
#Create an object of StandardScaler which is present in sklearn.preprocessing
scalar = StandardScaler()
scaled_data = pd.DataFrame(scalar.fit_transform(df)) #scaling the data
scaled_data
输出:

缩放的虹膜数据集
步骤 3:检查没有 PCA 的特征之间的相关性(可选)
现在,我们将使用热图检查我们的缩放数据集之间的相互关系。为此,我们已经在 Step-1 中导入了 seaborn 库。各种特征之间的相关性由corr()函数给出,然后热图由 heatmap()函数绘制。热图一侧的色标有助于确定相关性的大小。在我们的示例中,我们可以清楚地看到,较深的阴影表示较少的相关性,而较浅的阴影表示较多的相关性。热图的对角线表示特征与其自身的相关性——它始终为 1.0,因此,热图的对角线具有最高的阴影。
Python3
#Check the Co-relation between features without PCA
sns.heatmap(scaled_data.corr())
输出:
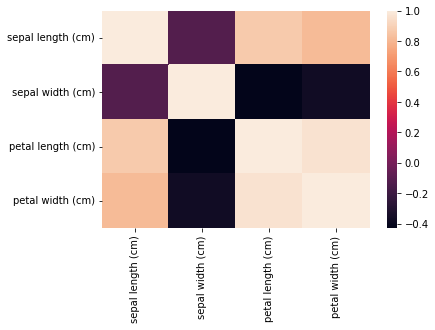
没有 PCA 的 Iris 数据集的相关热图
我们可以从上面的热图中观察到萼片长度和花瓣长度以及花瓣长度和花瓣宽度具有高度的相关性。因此,我们显然需要应用降维。如果您已经知道您的数据集需要降维 - 您可以跳过此步骤。
第四步:应用主成分分析
我们将在缩放数据集上应用 PCA。为此, Python提供了另一个名为 PCA 的内置类,它存在于sklearn.decomposition中,我们已经在步骤 1 中导入了该类。我们需要创建一个 PCA 对象,同时我们还需要初始化 n_components——这是我们想要在最终数据集中的主成分的数量。在这里,我们取 n_components = 3,这意味着我们的最终特征集将有 3 列。我们将缩放数据拟合到 PCA 对象,这为我们提供了简化的数据集。
Python
#Applying PCA
#Taking no. of Principal Components as 3
pca = PCA(n_components = 3)
pca.fit(scaled_data)
data_pca = pca.transform(scaled_data)
data_pca = pd.DataFrame(data_pca,columns=['PC1','PC2','PC3'])
data_pca.head()
输出:

PCA 数据集
第 5 步:在 PCA 之后检查特征之间的相关性
现在我们已经应用了 PCA 并获得了简化的特征集,我们将再次使用热图检查各种主成分之间的相互关系。
Python3
#Checking Co-relation between features after PCA
sns.heatmap(data_pca.corr())
输出:

PCA 后的热图
上面的热图清楚地描绘了各种获得的主成分(PC1、PC2 和 PC3)之间没有相关性。因此,我们已经从高维特征空间转移到低维特征空间,同时确保如此获得的 PC 之间没有相关性是最小的。因此,我们已经实现了 PCA 的目标。
主成分分析 (PCA) 的优点:
- 为了高效地工作 ML 模型,我们的特征集需要具有没有关联的特征。在我们的数据集上实施 PCA 后,所有的主成分都是独立的——它们之间没有相关性。
- 大量的特征集导致模型中的过度拟合问题。 PCA 减少了特征集的维度——从而减少了过度拟合的机会。
- PCA 帮助我们减少特征集的维度;因此,新形成的包含主成分的数据集需要更少的磁盘/云空间来存储,同时保留最大的信息。