📌 相关文章
- x=x+1 - Python (1)
- 在 python 中(1)
- python 类 - Python (1)
- Python包
- Python包
- Python -P值
- python 新行 - Python (1)
- Python堆(1)
- 在 python [:-1] - Python (1)
- python 类 - Python (1)
- -- python (1)
- :: python(1)
- += python (1)
- \n python (1)
- \r\n python (1)
- python 蛇 - Python (1)
- python 解耦 - Python (1)
- Python (1)
- Python中的库
- python中的0 1 1 2 3 5(1)
- [1, 2, 3] - Python (1)
- == 在 python 中(1)
- 和 python (1)
- 5**5 - Python (1)
- [1::2] python (1)
- a - Python (1)
- 在 python 中(1)
- 硒python(1)
- 表 - Python (1)
- Python
📜 Python块和块
📅 最后修改于: 2020-11-06 06:19:53 🧑 作者: Mango
分块是根据单词的性质将相似单词分组在一起的过程。在下面的示例中,我们定义了必须通过其生成块的语法。语法建议了短语的顺序,例如名词和形容词等,在创建块时将遵循这些顺序。块的图片输出如下所示。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {?*}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
当我们运行上面的程序时,我们得到以下输出-
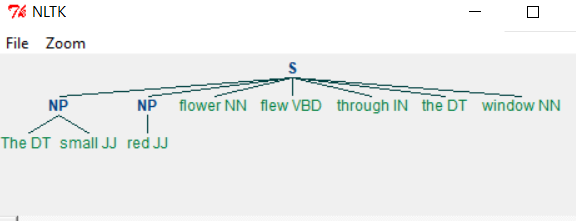
更改语法后,我们将得到不同的输出,如下所示。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {当我们运行上面的程序时,我们得到以下输出-
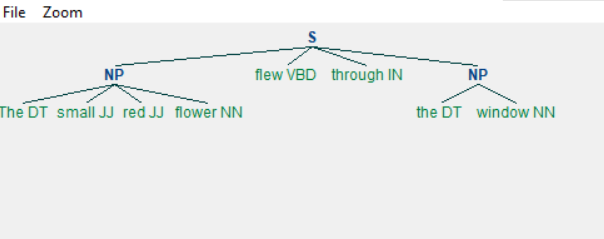
叮叮当当
压缩是从块中删除一系列令牌的过程。如果令牌序列出现在块的中间,则将删除这些令牌,在它们已经存在的位置留下两个块。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = r"""
NP:
{+} # Chunk everything
}+{ # Chink sequences of JJ and NN
"""
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
当我们运行上面的程序时,我们得到以下输出-
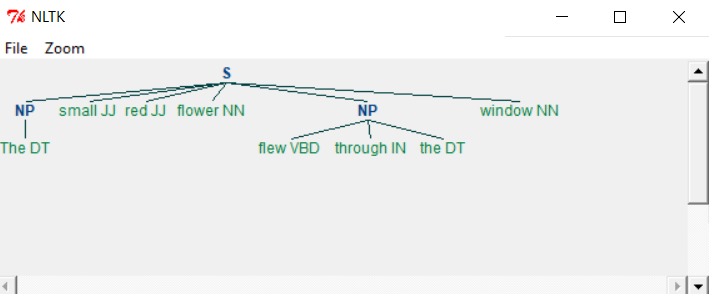
如您所见,符合语法标准的部分作为单独的块从名词短语中被漏掉了。提取不在所需块中的文本的过程称为chinking。